简单使用jsoup
中文在线手册
下载地址
jsoup是java的一款html解析器,可以很方便的对html进行解析。
1.获取标题:
public class TestJsoup {
public static void main(String[] args) {
Document doc;
try {
// 获取文档
doc = Jsoup.connect("http://news.ifeng.com/").get();
// 获取body
Element content = doc.body();
// 标签集合,是每页的标题和链接
Elements divs = content.select("div");
for (int i = 0; i < divs.size(); i++) {
// 今日要闻
if ("box_02".equals(divs.get(i).attributes().get("class"))) {
Elements titles = divs.get(i).select("a");
for (Element title : titles) {
if (""!=title.text()) {
System.out.println(title.text());
//链接
system.out.printlin(title.select("a").attr("href");
); }
}
}
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
结果:

2.获取新闻内容:
public static void main(String[] args) {
Document doc;
try {
// 获取文档
doc = Jsoup
.connect(
"http://news.ifeng.com/world/special/malaixiyakejishilian/content-4/detail_2014_03/30/35274873_0.shtml")
.get();
// 获取body
Element content = doc.getElementById("main_content");
// 标签集合,是每页的标题和链接
Elements divs = content.select("p");
for (Element ele : divs) {
// 假如标签是图片地址
if ("detailPic".equals(ele.attributes().get("class"))) {
System.out.println(ele.select("img").attr("src"));
} else {
System.out.println(ele.text() + "\n");
}
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
结果:

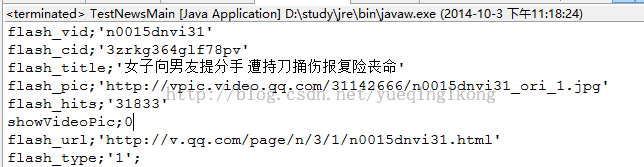
3.获取video信息:

这是某个新闻的视频消息,我们需要解析script里面的参数信息。
// video
s = p.select("script");
if (!s.isEmpty()) {
// 将参数列表转为文本
String data = s.first().data();
data = data.replaceAll("var", "");
String[] arr;
// arr= data.split("',");
// for (int i = 0; i < arr.length; i++) {
// String str = arr[i];
// str = str.replaceAll("flash_[\\S]{0,} = '", "");
// System.out.println(str.trim());
// }
arr = data.split(",");
for (String str : arr) {
String[] ir = str.split("=");
System.out.println(ir[0].trim() + ";" + ir[1].trim());
}
}
结果:
完整的例子:
public class Artcle {
private String artLink;
private Document Doc;
private Element ele;
private Elements eles;
// "http://news.qq.com/a/20141001/018175.htm?tu_biz=1.114.2.1"
public Artcle(String str) {
this.artLink = str;
}
public Document getDoc(String web) {
Document doc = null;
try {
doc = Jsoup.connect(web).get();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
return null;
}
return doc;
}
public void getArtcle() {
if (null == (Doc = getDoc(artLink))) {
return;
}
ele = Doc.select("div#Cnt-Main-Article-QQ").first();
eles = ele.select("p");
for (Element p : eles) {
Elements s = null;
// video
s = p.select("script");
if (!s.isEmpty()) {
// 将参数列表转为文本
String data = s.first().data();
data = data.replaceAll("var", "");
String[] arr;
// arr= data.split("',");
// for (int i = 0; i < arr.length; i++) {
// String str = arr[i];
// str = str.replaceAll("flash_[\\S]{0,} = '", "");
// System.out.println(str.trim());
// }
arr = data.split(",");
for (String str : arr) {
String[] ir = str.split("=");
System.out.println(ir[0].trim() + ";" + ir[1].trim());
}
}
}
}
}
注意:
1.使用的方法还是很简单的,在有时候解析网页的时候会抛出io异常,自己注意就是了。
2.// 将参数列表转为文本
String data = s.first().data();
很重要的方法,将script中的参数列表转为字符串格式,然后我们通过对字符串的裁剪等操作,就可以得到需要的信息。