基于Access数据源的Clementine数据挖掘技术
一、数据挖掘简介
数据挖掘(Data Mining,DM)又称数据库中的知识发现(Knowledge Discover in Database,KDD),是目前人工智能和数据库领域研究的热点问题,所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程。数据挖掘是一种决策支持过程,它主要基于人工智能、机器学习、模式识别、统计学、数据库、可视化技术等,高度自动化地分析企业的数据,做出归纳性的推理,从中挖掘出潜在的模式,帮助决策者调整市场策略,减少风险,做出正确的决策。
二、使用实例
本文运用数据挖掘技术中的关联规则对某学校的学生成绩数据进行深入分析,并选择关联分析中GRI模型分析各因素的关联规则,得出了学生专业基础课程与专业课程之间的相关趋势。数据源是基于Access数据库的学生成绩表,里面保存了学生基础课和专业课的成绩级别。
三、实现过程
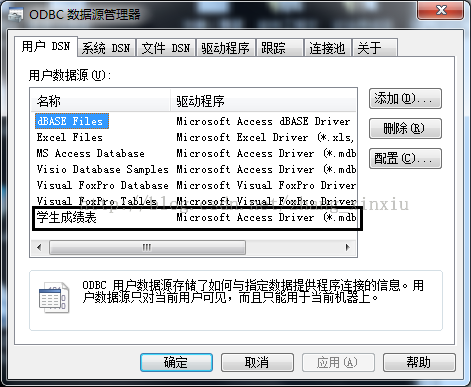
1、配置ODBC数据源
首先打开系统C盘下的Windows文件夹(系统要求:Win7及更高版本的Windows系统),找到名为SysWOW64命名的文件夹并打开,在该文件夹下找到名为odbcad32.exe的工具,并以管理员身份运行该配置工具,出现下图:
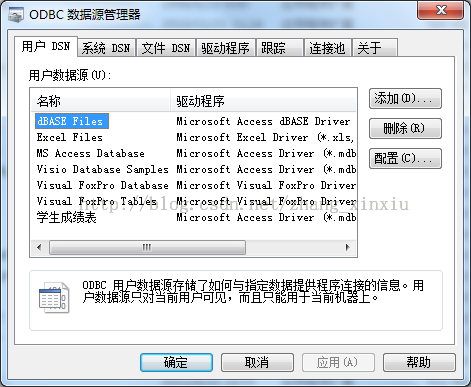
打开数据源管理器后需要我们手动添加学生成绩表的数据源,首先点击添加,在创建新数据源列表框中选择Mircrosoft Access Driver(*.mdb,*.accdb),具体操作如下图:
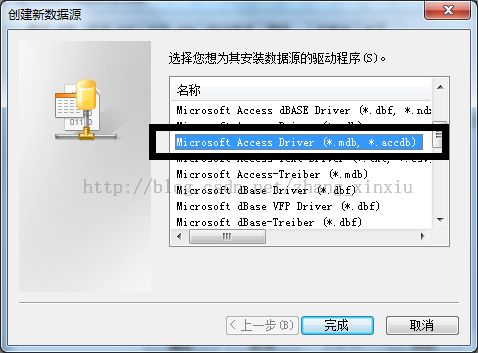
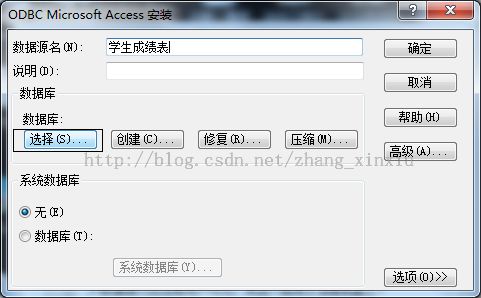
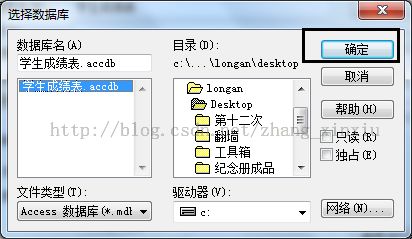
选择后点击完成,在弹出的对话框中填入我们的数据源名,并在数据库框中选择我们需要添加的Access数据库。

2、在Clementine中添加数据源
配置完ODBC后需要我们在Clementine中添加SQL数据源文件。双击SQL数据源在弹出的对话框中选择数据源,在类表框中选择添加新的数据库连接,选中学生成绩表数据源后点击连接。
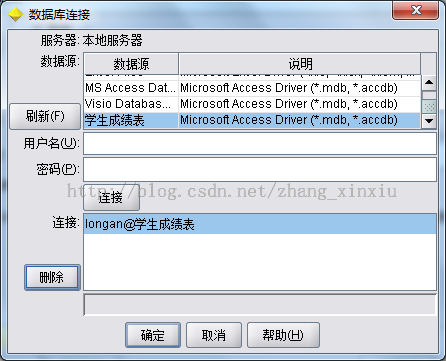
在数据源中我们将注解改为定制,并命名为导入数据。
3、对数据源进行散点分析
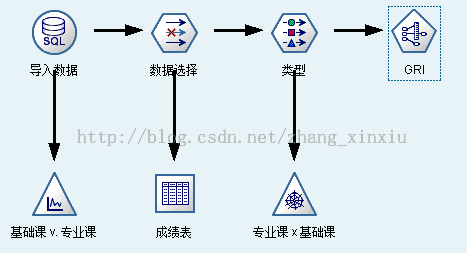
添加散点图,并将X字段设置为基础课,Y字段设置为专业课,点击执行,得到下图。

从散点图中可以较直观的看清楚两种课程成绩的分布情况。
4、数据选择去除学号
将导入的数据进行筛选,去除学号,并生成具体成绩表,操作完后的模型图如下:

5、对数据进行类型分析
对数据进行筛选后,需要对数据进行类型分析,选中数据选择模型图,双击添加类型。
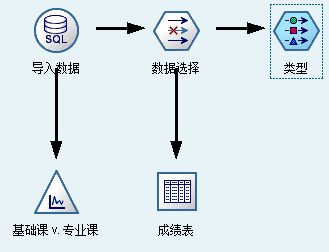
添加类型分析后,为了生成GRI图,需要添加专业课对基础课的绝对值网络图。
6、GRI建模
添加GRI建模图形,并将专业课和基础课添加到前项和后项中。
三、结果分析
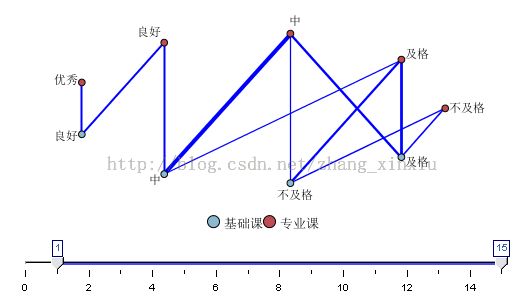
这个过程主要是分析大学生基础课成绩和专业课成绩中可能存在的各种关联以及各种关联的程度如何,从而进一步分析其中存在的因果关系。为了保证结果分析和预测的全面性,在本例中,对关联规则中的两个重要关联指标最小支持度和最小可信度的最小阈值均设置为0。
执行模型图后,得到如表2所示结果:
表2 基础课成绩和专业课成绩关联分析表
| 实例 |
后项 |
前项 |
支持度 % |
置信度 |
提升 |
| 48 |
基础课 = 中 |
专业课 = 中 |
29.81 |
64.58 |
2.07 |
| 26 |
基础课 = 良好 |
专业课 = 优秀 |
16.15 |
57.69 |
3.20 |
| 34 |
基础课 = 及格 |
专业课 = 及格 |
21.12 |
58.82 |
2.10 |
分析表2,如果设定最小支持度为20%,最小可信度为60%,从而得到一个弱关联规则是:基础课成绩为“及格”的学生,在专业课中取得“及格”成绩的支持度、可信度和提升值分别为21.12%,58.82%和2.10。
如果设定最小支持度为30%,最小可信度为70%,从而得到另一个强关联规则是:基础课成绩为“中”的学生,专业课也为“中”的支持度、可信度和提升值分别为29.81%,64.58%和2.07。
通过对以上关联规则数据挖掘提供的各项指标,对该大学院校学生成绩分析与预测的结果如下:该大学院校学生专业课程类成绩略高于基础课程类成绩,原因是多方面的,其中涉及到专业课程类师资力量配备强大、改进了专业类课程教学方法和手段、挖掘“中”等学生的学习潜力以及学生对专业课学习积极性等,该学院应根据自己的实际情况作进一步的分析。