主题模型-LDA浅析
(一)LDA作用
传统判断两个文档相似性的方法是通过查看两个文档共同出现的单词的多少,如TF-IDF等,这种方法没有考虑到文字背后的语义关联,可能在两个文档共同出现的单词很少甚至没有,但两个文档是相似的。
举个例子,有两个句子分别如下:
“乔布斯离我们而去了。”
“苹果价格会不会降?”
可以看到上面这两个句子没有共同出现的单词,但这两个句子是相似的,如果按传统的方法判断这两个句子肯定不相似,所以在判断文档相关性的时候需要考虑到文档的语义,而语义挖掘的利器是主题模型,LDA就是其中一种比较有效的模型。
在主题模型中,主题表示一个概念、一个方面,表现为一系列相关的单词,是这些单词的条件概率。形象来说,主题就是一个桶,里面装了出现概率较高的单词,这些单词与这个主题有很强的相关性。
怎样才能生成主题?对文章的主题应该怎么分析?这是主题模型要解决的问题。
首先,可以用生成模型来看文档和主题这两件事。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到的。那么,如果我们要生成一篇文档,它里面的每个词语出现的概率为:

这个概率公式可以用矩阵表示:
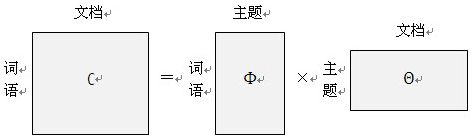
其中”文档-词语”矩阵表示每个文档中每个单词的词频,即出现的概率;”主题-词语”矩阵表示每个主题中每个单词的出现概率;”文档-主题”矩阵表示每个文档中每个主题出现的概率。
给定一系列文档,通过对文档进行分词,计算各个文档中每个单词的词频就可以得到左边这边”文档-词语”矩阵。主题模型就是通过左边这个矩阵进行训练,学习出右边两个矩阵。
主题模型有两种:pLSA(ProbabilisticLatent Semantic Analysis)和LDA(Latent Dirichlet Allocation),下面主要介绍LDA。
(二)LDA介绍
如何生成M份包含N个单词的文档,LatentDirichlet Allocation这篇文章介绍了3方法:
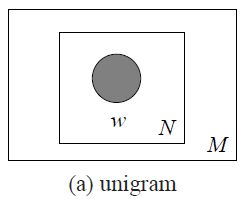
方法一:unigram model
该模型使用下面方法生成1个文档:
For each ofthe N words w_n:
Choose a word w_n ~ p(w);
其中N表示要生成的文档的单词的个数,w_n表示生成的第n个单词w,p(w)表示单词w的分布,可以通过语料进行统计学习得到,比如给一本书,统计各个单词在书中出现的概率。
这种方法通过训练语料获得一个单词的概率分布函数,然后根据这个概率分布函数每次生成一个单词,使用这个方法M次生成M个文档。其图模型如下图所示:
方法二:Mixture of unigram
unigram模型的方法的缺点就是生成的文本没有主题,过于简单,mixture of unigram方法对其进行了改进,该模型使用下面方法生成1个文档:
Choose a topicz ~ p(z);
For each ofthe N words w_n:
Choose a word w_n ~ p(w|z);
其中z表示一个主题,p(z)表示主题的概率分布,z通过p(z)按概率产生;N和w_n同上;p(w|z)表示给定z时w的分布,可以看成一个k×V的矩阵,k为主题的个数,V为单词的个数,每行表示这个主题对应的单词的概率分布,即主题z所包含的各个单词的概率,通过这个概率分布按一定概率生成每个单词。
这种方法首先选选定一个主题z,主题z对应一个单词的概率分布p(w|z),每次按这个分布生成一个单词,使用M次这个方法生成M份不同的文档。其图模型如下图所示:

从上图可以看出,z在w所在的长方形外面,表示z生成一份N个单词的文档时主题z只生成一次,即只允许一个文档只有一个主题,这不太符合常规情况,通常一个文档可能包含多个主题。
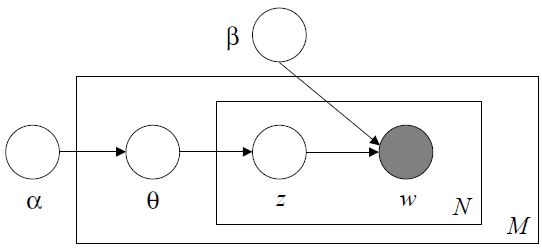
方法三:LDA(Latent Dirichlet Allocation)
LDA方法使生成的文档可以包含多个主题,该模型使用下面方法生成1个文档:
Chooseparameter θ ~ p(θ);
For each ofthe N words w_n:
Choose a topic z_n ~ p(z|θ);
Choose a word w_n ~ p(w|z);
其中θ是一个主题向量,向量的每一列表示每个主题在文档出现的概率,该向量为非负归一化向量;p(θ)是θ的分布,具体为Dirichlet分布,即分布的分布;N和w_n同上;z_n表示选择的主题,p(z|θ)表示给定θ时主题z的概率分布,具体为θ的值,即p(z=i|θ)= θ_i;p(w|z)同上。
这种方法首先选定一个主题向量θ,确定每个主题被选择的概率。然后在生成每个单词的时候,从主题分布向量θ中选择一个主题z,按主题z的单词概率分布生成一个单词。其图模型如下图所示:
从上图可知LDA的联合概率为:

把上面的式子对应到图上,可以大致按下图理解:

从上图可以看出,LDA的三个表示层被三种颜色表示出来:
1. corpus-level(红色):α和β表示语料级别的参数,也就是每个文档都一样,因此生成过程只采样一次。
2.document-level(橙色):θ是文档级别的变量,每个文档对应一个θ,也就是每个文档产生各个主题z的概率是不同的,所有生成每个文档采样一次θ。
3. word-level(绿色):z和w都是单词级别变量,z由θ生成,w由z和β共同生成,一个 单词w对应一个主题z。
通过上面对LDA生成模型的讨论,可以知道LDA模型主要是从给定的输入语料中学习训练两个控制参数α和β,学习出了这两个控制参数就确定了模型,便可以用来生成文档。其中α和β分别对应以下各个信息:
α:分布p(θ)需要一个向量参数,即Dirichlet分布的参数,用于生成一个主题θ向量;
β:各个主题对应的单词概率分布矩阵p(w|z)。
把w当做观察变量,θ和z当做隐藏变量,就可以通过EM算法学习出α和β,求解过程中遇到后验概率p(θ,z|w)无法直接求解,需要找一个似然函数下界来近似求解,原文使用基于分解(factorization)假设的变分法(varialtional inference)进行计算,用到了EM算法。每次E-step输入α和β,计算似然函数,M-step最大化这个似然函数,算出α和β,不断迭代直到收敛。
参考文献:
David M. Blei, AndrewY. Ng, Michael I. Jordan, LatentDirichlet Allocation, Journal of Machine Learning Research 3, p993-1022,2003
【JMLR’03】Latent Dirichlet Allocation (LDA)- David M.Blei
搜索背后的奥秘——浅谈语义主题计算
http://bbs.byr.cn/#!article/PR_AI/2530?p=1
转载请注明出处,原文地址:http://blog.csdn.net/huagong_adu/article/details/7937616