Apache Pig Reducer OOM 解决 -- Big DataBag
最近遇到一次Pig的reducer频繁OOM的问题, 记录一下解决过程.
问题描述
有一段pig代码, 示例如下:
Data = group SourceData all; Result = foreach Data generate group, COUNt(SourceData); store Result into 'XX';
简单的使用group all 后计算COUNT. 为了减少Load data 次数, 脚本中有多个group all, 计算结果后一起store
现象:
开始, 这段脚本运行完好. 随着数据量的增长, 突然发生了reducer OOM, 屡试不爽.
解决方法:
通过在mapred-site.xml中修改task JVM参数,添加-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/task.dump,重新运行pig 脚本, 将oom的heap dump 拖回来同mat分析, 结果如下:
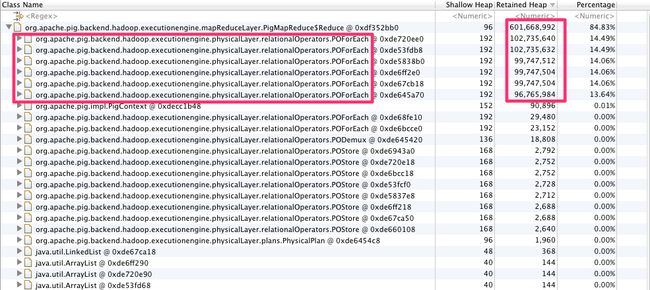
发现是POForEach 内出占用过高. 进一步展开POForEach, 结果如下:
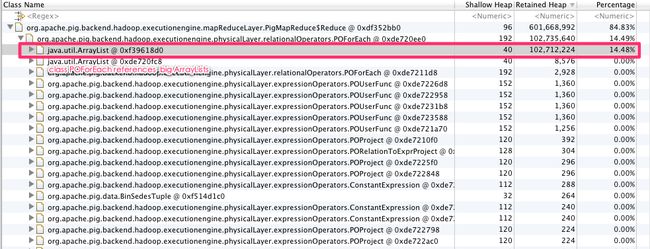
发现是POForEach 引用了非常大的ArrayList. 查看Pig 源代码发现, DataBag的默认实现DefaultDataBag是使用ArrayList存储数据. 既然是DataBag数据过多, 可以考虑手动调用spill方法, 将多余的数据spill到磁盘上, 节约空间.
第一次尝试:
编写UDF, 继承Pig默认的COUNT, 在计算完成后手动调用spill, 代码如下:
public class HECOUNT extends COUNT {
@Override
public Long exec(Tuple input) throws IOException {
DataBag bag = (DataBag)input.get(0);
Long result = super.exec(input);
bag.spill();
return result;
}
}
再次运行脚本, 仍旧OOM, dump出来的内存分布与上次没有什么区别,说明这次spill是没有意义的.
后来又在spill后手动调用System.gc(), 也是不行
mailinglist 求助
在[email protected]中发邮件求助, 无解. (貌似pig的邮件组并不是非常活跃.)
偶然在mail archive中搜索到一个邮件: 邮件内容
Alan Gate的意思是, pig希望数据能够在内存中放得下. 也有人建议我将reducer内存开到1GB. 受限于现有集群的配置, 这个方法对于我来说是不可行的.
柳暗花明
继续研究heap dump, 发现这个大的ArrayList的引用如下(图片显示可能有问题, 无法显示右边内存占用. OMG):

原来是InternalCacheBag, 不是DefaultDataBag的问题.
翻阅InternalCacheBag的源代码, 发现这个的cacheLimit是可以在pig.properties中设置的, 源代码如下:
public InternalCachedBag() {
this(1);
}
public InternalCachedBag(int bagCount) {
float percent = 0.2F;
if (PigMapReduce.sJobConfInternal.get() != null) {
String usage = PigMapReduce.sJobConfInternal.get().get("pig.cachedbag.memusage");
if (usage != null) {
percent = Float.parseFloat(usage);
}
}
init(bagCount, percent);
}
public InternalCachedBag(int bagCount, float percent) {
init(bagCount, percent);
}
private void init(int bagCount, float percent) {
factory = TupleFactory.getInstance();
mContents = new ArrayList<Tuple>();
long max = Runtime.getRuntime().maxMemory();
maxMemUsage = (long)(((float)max * percent) / (float)bagCount);
cacheLimit = Integer.MAX_VALUE;
// set limit to 0, if memusage is 0 or really really small.
// then all tuples are put into disk
if (maxMemUsage < 1) {
cacheLimit = 0;
}
addDone = false;
}
在 $PIG_HOME/conf/pig.properties 中, 设置 pig.cachedbag.memusage=0 , 重跑job , 通过.
又试了几个以前OOM的job, 都通过.
总结
Pig 的DataBag问题的确非常头疼, 而且文档也不是非常全面, 不读源代码根本不知道这个在哪里设置(默认的pig.properties文件里连这个选项都没有示例).不过对于复杂一点的数据分析系统, 需要通过编程的方式生成MR任务的情况下, Pig的确比Hive容易的多, 脚本的debug也比hive容易.
OK, 总结到这里.
--EOF--