一氪钟:了解和实现 Lucene 分词器
| 说明:本文所涉及的 Lucene 类型来源于 Apache Lucene 4.3.0 版本。 |
Lucene 分词器是通过继承 Tokenizer 类型来实现的, Tokenizer 类型的继承结构如下。
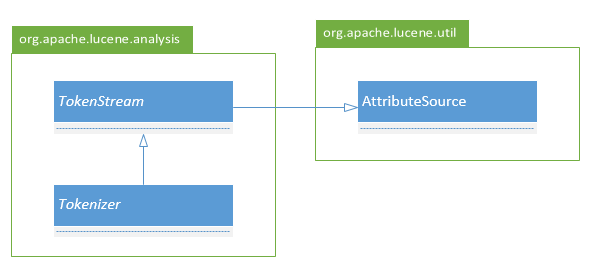
图中与分词器实现相关的类型一共有三个: AttributeSource、 TokenStream 和 Tokenizer,这三个类型在我们实现的分词器的继承路径上各自发挥不同的作用,可以说它们分别描述和封闭了一个具体分词器的三个不同方面的特性。
首先是 AttributeSource 类型,它的主要结构如下。
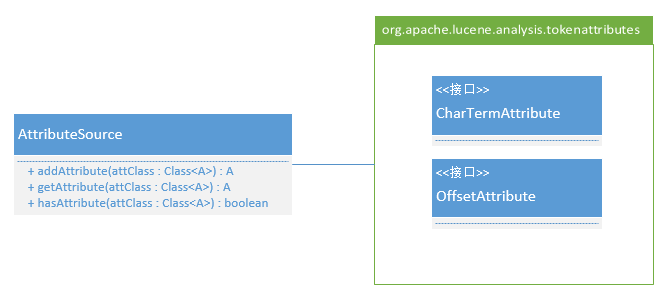
AttributeSource 的作用对于刚接触 Lucene 的同学而言会有点难理解,其实可以从字面上来了解一下,就是“属性源”,这个属性是谁的属性呢?就是被拆分出来的词条的属性。后面我们会了解到 Tokenizer 在拆分词条时,会像迭代器一样从前至后一个词条一个词条的提供给调用方,而这些词条会具备一些描述自己特征的属性。比如 CharTermAttribute 属性用于描述词条的内容, OffsetAttribute 属性用于描述词条在被拆分文本中的位置信息,不同的分词器可以为词条设置不同的属性(Lucene 内核支持的词条属性可以参见 org.apache.lucene.analysis.tokenattributes 包),但要支持检索,则 CharTermAttribute 和 OffsetAttribute 属性是必须的。由于 Tokenizer 拆分词条的方式,它返回的词条被设计为共享同类型的属性对象,这样可以节省大量的属性对象实例化开销以及垃圾对象的回收开销,这就意为着即便你为前一个词条的属性保留了引用,一旦你获取了下一个词条,这些属性的引用返回的内容都将会是新词条的。
分词器在拆分词条时会先设置这个词条的属性然后再返回给调用方,作为 Tokenizer 的继承者,它们操作属性(在 Tokenizer 中是共享的)的安全方法是在自身被实例化的过程中先使用 AttributeSource. addAttriubte 方法添加自己要为返回词条设置的属性并保留引用,再在后续的拆分过程中使用 AttributeSource. getAttribute 方法或通过之前保留的引用来获取指定属性的共享对象。以下是分词器操作词条属性的一个场景。
public class DemoTokenizer extends Tokenizer {
private CharTermAttribute termAtt = addAttribute(CharTermAttribute.class);
private OffsetAttribute offsetAtt = addAttribute(OffsetAttribute.class);
protected DemoTokenizer(AttributeFactory factory, Reader input) {
super(factory, input);
}
...
@Override
public boolean incrementToken() throws IOException {
termAtt.setEmpty();
...
termAtt.setLength(len);
offsetAtt.setOffset(startPos, endPos);
return true;
}
}
调用方在使用分词器拆分出的词条时,通常也是在开始处理词条前通过 AttributeSource. getAttribute 方法来获取和保留词条的某类属性对象,当然这么做的前提是已经明确知道这个分词器会为词条设置这样的属性(绝大多数情况下我们都能知道),否则就应该先使用 AttributeSource. hasAttribute 方法来检测分词器是否支持某个属性,以避免程序异常。
接下来是 TokenStream
类型,它的主要结构如下。

TokenStream 的作用是描述一个抽象的词条流,它定义了调用方应该如何使用词条资源(比如一个字符串可以被拆分为词条,那么这个字符串被封装之后就是一个词条资源),它是真正完全为分词活动而设计的类型,不像 AttributeSource 还可以应用于其它适用的场景。
调用方使用一个 TokenStream 的流程一般如下:
- 实例化一个 TokenStream 的对象;
- 调用方调用 reset() 方法;
- 调用方从当前上下文或词条流中获取自己需要访问和词条属性对象;
- 调用方调用 incrementToken() 方法,并在每次调用后处理词条属性的信息,直到这个方法返回 false;
- 调用方调用 end() 方法,以便任何结束当前词条流的方法可以被执行,这个步骤绝对不要省略;
- 当不再需要使用 TokenStream 时,调用方调用 close() 方法来释放任何被 TokenStream 使用的资源。
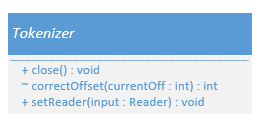
最后来看看 Tokenizer 类型,它的主要结构如下。
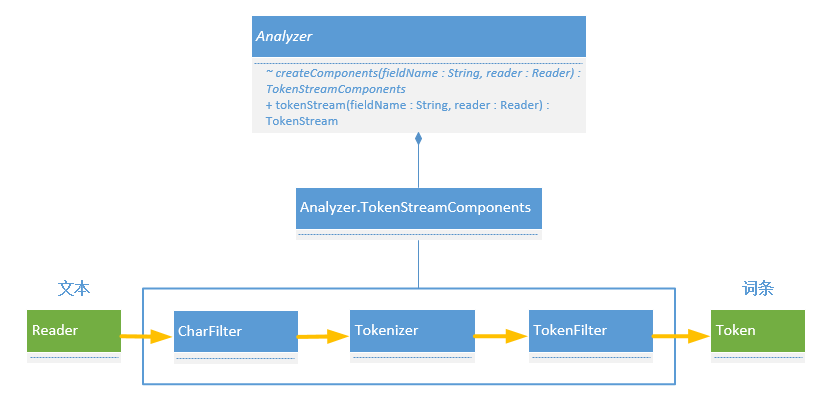
Tokenizer 的作用是将分词器作为一个组件加入到由 Analyzer 创建的
TokenStreamComponents 中,并协调自己与
CharFilter 和
TokenFilter 这两类组件之间的关系。这里只简单说明一下, CharFilter
是一种字符过滤器,它根据规则过滤掉输入文本中的一些字符,剩下的再传递给 Tokenizer 进行分词,而 Tokenizer 拆分出来的词条又会被 TokenFilter
这种词条过滤器根据规则过滤掉输出词条中的一些词条,最后剩下的词条才会被调用系统真正使用。 Analyzer 作为文本分析器,在整个完整的文本分析和分词过程中扮演一个组织者,特定的 Analyzer 会将需要的 CharFilter
、 Tokenizer 和 TokenFilter 组织起来成为一个 TokenStreamComponents
,最后调用系统会通过 Analyzer.tokenStream(String fieldName, Reader reader) 方法将文本封装为 TokenStream 来获取文本中的词条。下图给出了前述场景的图示,有关 Analyzer、 TokenStreamComponents、 CharFilter 和 TokenFilter 的更多信息不是本文讲述的重要,请同学们参考其它资料。
Tokenizer 类型中的 setReader(Reader input) 方法用于为当前分词器指定分析文本,为什么要这么做?这是基于 Lucene 文本分析模块在设计时始终贯彻的复用原则(具体的复用策略由 Analyzer. ReuseStrategy 来指定),如果一个 Tokenizer 被 Analyzer 创建,那么通过这个方法就可以在不创建新的 Tokenizer 对象的情况下对其它文本重新开始分词,在对大量文档的内容建立索引时,这样的复用机制会带来显而易见的性能优势。
通过上述几段文字对 AttributeSource、 TokenStream 和 Tokenizer 这三个类型的讲述,我们应该可以对实现一个 Lucene 分词器有了一个基本的概念。当然,这些内容还不足以让同学们打开 IDE 就能马上写一个分词器出来,下面我们将通过一个非常简单的示例代码来加深对本文所提及概念的理解,同时也为真正实现一个分词器迈出第一步。
以下示例程序,我们将会对输入的文本按字母进行分词,每个词条包含一个 A-Z 的字母,其它所有符号均会被我们的示例分词器给忽略掉。
package com.simansoft.demos.demotokenizer;
import java.io.IOException;
import java.io.Reader;
import java.io.StringReader;
import java.lang.Character.UnicodeBlock;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
public final class DemoTokenizer extends Tokenizer {
private final CharTermAttribute termAtt = addAttribute(CharTermAttribute.class);
private final OffsetAttribute offsetAtt = addAttribute(OffsetAttribute.class);
private int pos;
public DemoTokenizer(Reader input) {
super(input);
}
@Override
public final boolean incrementToken() throws IOException {
clearAttributes();
while (true) {
int c = input.read();
if (c == -1)
return false;
if (Character.isLetter(c) &&
UnicodeBlock.of(c) == UnicodeBlock.BASIC_LATIN) {
termAtt.setEmpty();
termAtt.append((char)c);
termAtt.setLength(1);
offsetAtt.setOffset(correctOffset(pos++), correctOffset(pos));
return true;
}
pos += Character.charCount(c);
}
}
@Override
public final void end() throws IOException {
super.end();
int finalOffset = correctOffset(pos);
offsetAtt.setOffset(finalOffset, finalOffset);
}
@Override
public final void reset() throws IOException {
pos = 0;
}
public static void main(String[] args) throws Exception {
Reader text = new StringReader("Hello 123.");
DemoTokenizer tok = new DemoTokenizer(text);
CharTermAttribute termAtt = tok.getAttribute(CharTermAttribute.class);
OffsetAttribute offsetAtt = tok.getAttribute(OffsetAttribute.class);
try {
tok.reset();
while (tok.incrementToken()) {
System.out.println(String.format("%1$s %2$d %3$d", termAtt.toString(), offsetAtt.startOffset(), offsetAtt.endOffset()));
}
tok.end();
assert offsetAtt.startOffset() == offsetAtt.endOffset();
System.out.println(String.format("end at: %1$d", offsetAtt.endOffset()));
text.close();
text = new StringReader("中国 China!");
tok.setReader(text);
tok.reset();
while (tok.incrementToken()) {
System.out.println(String.format("%1$s %2$d %3$d", termAtt.toString(), offsetAtt.startOffset(), offsetAtt.endOffset()));
}
tok.end();
assert offsetAtt.startOffset() == offsetAtt.endOffset();
System.out.println(String.format("end at: %1$d", offsetAtt.endOffset()));
text.close();
} finally {
tok.close();
}
}
}