sparkSQL1.1入门之五:测试环境之搭建
前面介绍了sparkSQL的运行架构,后面将介绍sparkSQL的使用。在介绍sparkSQL的使用之前,我们需要搭建一个sparkSQL的测试环境。本次测试环境涉及到hadoop之HDFS、hive、spark以及相关的数据文件,相关的信息如下:


- hadoop版本为2.2.0
- hive版本为0.13
- spark版本为1.1.0
- MySQL版本为5.6.12
- 测试数据下载地点:http://pan.baidu.com/s/1eQCbT30#path=%252Fblog 中的sparkSQL_data.zip
测试环境示意图:
本测试环境是在一台物理机上搭建的,物理机的配置是16G内存,4核8线程CPU。hadoop1、hadoop2、hadoop3是vitual box虚拟机,构建hadoop集群和spark集群;物理机wyy作为客户端,编写代码和提交计算任务。总的测试环境配置如下:
| 机器名 | 配置 | 角色 | 软件安装 |
| hadoop1 | 4G内存,1核 | hadoop:NN/DN Spark:Master/worker | /app/hadoop/hadoop220
/app/hadoop/spark110
/app/scala2104
/usr/java/jdk1.7.0_21
|
| hadoop2 | 4G内存,1核 | hadoop:DN Spark:worker hive0.13客户端 |
/app/hadoop/hadoop220
/app/hadoop/spark110
/app/hadoop/hive013
/app/scala2104
/usr/java/jdk1.7.0_21
|
| hadoop3 | 4G内存,1核 | hadoop:DN Spark:worker hive0.13 metaserver service mysql server |
/app/hadoop/hadoop220
/app/hadoop/spark100
/app/hadoop/hive013
/app/scala2104
/usr/java/jdk1.7.0_21
MySQL5.6.12
|
| wyy | 16G内存,4核 | client hive0.13客户端 |
/app/hadoop/hadoop220 /app/hadoop/spark110 /app/hadoop/hive013 |
以上hadoop220、spark、hive安装目录的用户属性都是hadoop(组别为hadoop),其他安装目录的用户属性是root:root。
测试环境搭建顺序
1:虚拟集群的搭建(hadoop1、hadoop2、hadoop3)
A:hadoop2.2.0集群搭建
参照博客 hadoop2.2.0测试环境搭建
或者参看视频 http://pan.baidu.com/s/1qWqFY4c 提取密码:xv4i
B:MySQL的安装
参照博客 mysql5.6.12 for Linux安装
C:hive的安装
参照博客 Hive 0.11.0 远程模式搭建
本测试中使用的hive0.13,和hive0.11的安装一样。
hive安装在hadoop3、hadoop2、wyy。其中hadoop3启动metastore serive;hadoop2、wyy配置uris后作为hive的客户端。
D:Spark1.1.0 Standalone集群搭建
参照博客 Spark1.0.0 on Standalone 模式部署
这里需要注意的是,本测试中使用的是spark1.1.0,部署包生成命令make-distribution.sh的参数发生了变化,spark1.1.0的make-distribution.sh使用格式:
./make-distribution.sh [--name] [--tgz] [--with-tachyon] <maven build options>参数的含义:
--with-tachyon:是否支持内存文件系统Tachyon,不加此参数时为不支持。
--tgz:在根目录下生成 spark-$VERSION-bin.tar.gz,不加此参数是不生成tgz文件,只生成/dist目录。
--name NAME :和— tgz 结合可以生成 spark-$VERSION-bin-$NAME.tgz 的部署包,不加此参数时 NAME 为 hadoop 的版本号。
maven build options:使用maven编译时可以使用的配置选项,如使用-P、-D的选项
本次要生成基于hadoop2.2.0和yarn并集成hive、ganglia、asl的spark1.1.0部署包,可以使用命令:
./make-distribution.sh --tgz --name 2.2.0 -Pyarn -Phadoop-2.2 -Pspark-ganglia-lgpl -Pkinesis-asl -Phive
最后生成部署包spark-1.1.0-bin-2.2.0.tgz,按照测试环境的规划进行安装。
2:客户端的搭建
客户端wyy采用的Ubuntu操作系统,而Spark虚拟集群采用的是CentOS,默认的java安装目录两个操作系统是不一样的,所以在Ubuntu下安装java的时候特意将java的安装路径改成和CentOS一样。不然的话,每次scp了虚拟集群的配置文件之后,要修改hadoop、spark运行配置文件中的JAVA_HOME。
客户端hadoop2.2.0、Spark1.1.0、hive0.13是直接从虚拟集群中scp出来的,放置在相同的目录下,拥有相同的用户属性。开发工具使用的IntelliJ IDEA,程序编译打包后复制到spark1.1.0的根目录/app/hadoop/spark110下,使用spark-submit提交虚拟机集群运行。
3:文件数据准备工作
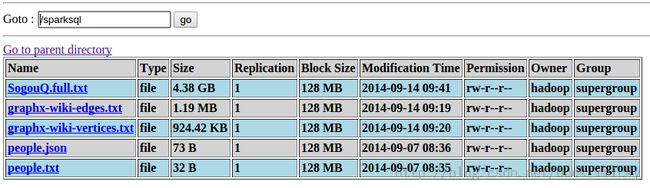
启动hadoop2.2.0(只需要HDFS启动就可以了),然后将数据文件上传到对应的目录:
- people.txt和people.json作为第六节sparkSQL之基础应用实验数据;
- graphx-wiki-vertices.txt和graphx-wiki-edges.txt作为第八节sparkSQL之综合应用中图处理数据;
- SogouQ.full.txt来源于Sogou实验室,下载地址:http://download.labs.sogou.com/dl/q.html 完整版(2GB):gz格式,作为第九节sparkSQL之调优的测试数据
4:hive数据准备工作
在hive里定义一个数据库saledata,和三个表tblDate、tblStock、tblStockDetail,并装载数据,具体命令:
CREATE DATABASE SALEDATA; use SALEDATA; //Date.txt文件定义了日期的分类,将每天分别赋予所属的月份、星期、季度等属性 //日期,年月,年,月,日,周几,第几周,季度,旬、半月 CREATE TABLE tblDate(dateID string,theyearmonth string,theyear string,themonth string,thedate string,theweek string,theweeks string,thequot string,thetenday string,thehalfmonth string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' ; //Stock.txt文件定义了订单表头 //订单号,交易位置,交易日期 CREATE TABLE tblStock(ordernumber string,locationid string,dateID string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' ; //StockDetail.txt文件定义了订单明细 //订单号,行号,货品,数量,金额 CREATE TABLE tblStockDetail(ordernumber STRING,rownum int,itemid string,qty int,price int,amount int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' ; //装载数据 LOAD DATA LOCAL INPATH '/home/mmicky/mboo/MyClass/doc/sparkSQL/data/Date.txt' INTO TABLE tblDate; LOAD DATA LOCAL INPATH '/home/mmicky/mboo/MyClass/doc/sparkSQL/data/Stock.txt' INTO TABLE tblStock; LOAD DATA LOCAL INPATH '/home/mmicky/mboo/MyClass/doc/sparkSQL/data/StockDetail.txt' INTO TABLE tblStockDetail;最终在HDFS可以看到相关的数据:
5:开始享受sparkSQL之旅。。。