Orthogonal Nonnegative Matrix Tri-factorizations for Clustering
文章对:Orthogonal NMF(正交非负矩阵分解)与kernel K-means之间的关系进行了分析,并证明两者有内在联系:
定理一:
Orthogonal NMF:min(F>=0,G>=0)||X-FGT||2,s.t. GTG=I
与K-means聚类是相等同的。
该证明可以查看:
C. Ding, X. He, and H.D. Simon. On the equivalence of nonnegative matrix factorization and spectral clustering. Proc. SIAM Data Mining Conf, 2005.
定理三:
令G为一个X的列K-means聚类的聚类指示符矩阵(cluster indicator matrix),F为X的行K-means聚类的聚类指示符矩阵。那么同步的行/列聚类可以用以下优化方法获得:
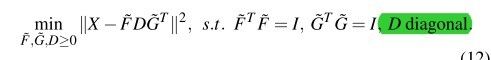
这说明3-factor的NMF与K-means聚类之间的关系。3个factor时,是在行和列上面同时进行了k-means聚类。

定理四:
在二正定三因素NMF(bi-Orthogonal 3-factor NMF)中,G给出了对X的列使用W=XTFFTX核函数进行k-means聚类的解决方案(X通过F跨越到的子空间的投影内积(inner product of the projection of X into the subspace spanned by F))。同样的,F给出了对X的列使用W=XGGTXT核函数进行k-means聚类的解决方案(X通过G跨越到的子空间的投影内积)。
文章中还提到了uni-orthogonal NMF的计算方法
一种是
min(F>=0,G>=0)||X-FGT||2,s.t. FTF=I.更新G和F的情况。
另一种是
min(F>=0,G>=0)||X-FGT||2,s.t. GTG=I.更新G和F的情况。
之后讲到:bi-orthogonal NMF的计算方法
考虑无限制的(unconstrained) 3-factor NMF
min(F>=0,G>=0,S>=0)||X-FSGT||2,在这种情况下,我们可以认为FS是2-factor NMF中的F。因此对于3-factor,只有当他不能被转化成2-factor NMF问题时才有讨论的意义。因此需要对3-factor增加一些约束。然而不是所有被约束的3-factor问题都有讨论的意义。
如:
min(F>=0,G>=0,S>=0)||X-FSGT||2,FTF=I
他和uni-orthogonal中的第一种情况是一样的。
再来看这种情况:
min(F>=0,G>=0,S>=0)||X-FSGT||2,FTF=I,GTG=I