重读网络挖掘中community detection 文章--Fast unfolding of communities in large networks
community detection 是源于复杂网络领域的关于网络节点的社团划分的工作。
复杂网络学科大量的实证研究发现很多网络存在聚簇效应,比如常见的社交网络。正所谓人以群分,物以类聚。
community detection 方法分为很多种,分裂方法,聚合方法等等。community detection 一个分支是重叠社区的发现(比如社交网络,一个节点可能属于多个社区),这个我这里暂时不累述,这个和非重叠社区识别方法有一定不同。这里主要说下非重叠社区划分方法。
community detection优化的目标大多是模块度指标,模块度越高,社团划分越好。
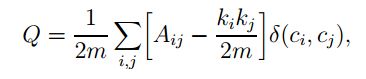
我最早接触的方法是NewMan组提出的Finding community structure in very large networks【1】文章提出的方法,这个可以处理百万规模的数据,但是,其实单机的话,20w上以上其实已经比较慢了。他这个方法是聚合方法,每个节点刚开始是单独社团,然后合并,每次取使模块度增大节点合并。具体细节参考文章本身。
后面接触的是label propagation方法:Near linear time algorithm to detect community structures in large-scale networks【2】这个方法是每次用户获取邻居中出现频次最高的社区标签作为自己的标签,反复迭代,直到收敛。这个算法一般使用异步更新节点社区标签,因为如果网络出现局部二部图结构,会出现震荡。他这个不是直接优化模块度的,时间很快,线性时间复杂度,但是经常出现不收敛情况,如果应用的话,需要做调整。
图例如下:

算法过程如下:

现在主要说下Fast unfolding of communities in large networks【3】
这个算法速度也很快,效率很高,处理的节点的规模可以很大。
这个方法分两步:
(1)从节点合并开始, 构建第一步社团划分结果。每个节点根据模块度增益决定是否加入到邻居节点的社团中和到底加入到哪个邻居节点的社团中。每个节点按序执行该过程。
(2)重新构建网络。把第一步每个社团单做一个节点,边是原来社团之间链接边权的和。
迭代(1),(2),直到收敛。
其中模块度增益如下:
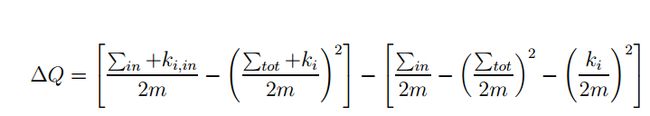
networkx包的community detection使用的方法就是这种方法。
算法过程的图例如下:
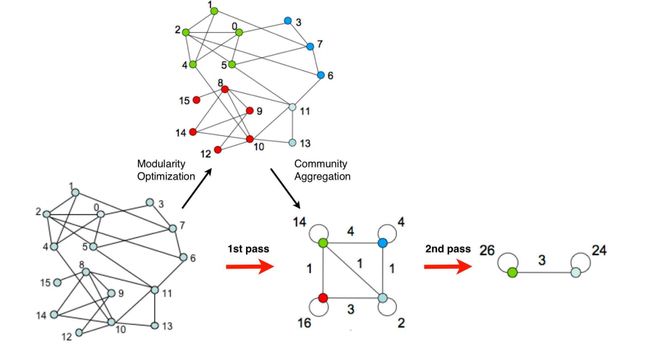
我在普通c用户的转账关系网络中尝试过这种方法,几十万节点很快,划分效果也很不错,不用自己设定社团大小。
参考文献:
[1] Clauset A, Newman M E J, Moore C. Finding community structure in very large networks[J]. Physical review E, 2004, 70(6): 066111.
[2] Near linear time algorithm to detect community structures in large-scale networks
[3] Fast unfolding of communities in large networks