JPEG图片存储格式及原理
JPEG是联合图象专家组(Joint Picture Expert Group)的英文缩写,是国际标准化组织(ISO)和CCITT联合制定的静态图象的压缩编码标准。和相同图象质量的其它常用文件格式(如GIF,TIFF,PCX)相比,JPEG是目前静态图象中压缩比最高的。我们给出具体的数据来对比一下。例图采用Windows95目录下的Clouds.bmp,原图大小为640*480,256色。用工具SEA(version1.3)将其分别转成24位色BMP、24位色JPEG、GIF(只能转成256色)压缩格式、24位色TIFF压缩格式、24位色TGA压缩格式。得到的文件大小(以字节为单位)分别为:921,654,17,707,177,152,923,044,768,136。可见JPEG比其它几种压缩比要高得多,而图象质量都差不多(JPEG处理的颜色只有真彩和灰度图)。
正是由于JPEG的高压缩比,使得它广泛地应用于多媒体和网络程序中,例如HTML语法中选用的图象格式之一就是JPEG(另一种是GIF)。这是显然的,因为网络的带宽非常宝贵,选用一种高压缩比的文件格式是十分必要的。
JPEG有几种模式,其中最常用的是基于DCT变换的顺序型模式,又称为基线系统(Baseline),以下将针对这种格式进行讨论。
1. JPEG的压缩原理
JPEG的压缩原理其实上面介绍的那些原理的综合,博采众家之长,这也正是JPEG有高压缩比的原因。其编码器的流程为:

图9.3 JPEG编码器流程
解码器基本上为上述过程的逆过程:
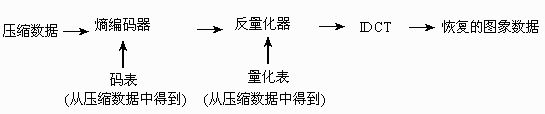
图9.4 解码器流程
8×8的图象经过DCT变换后,其低频分量都集中在左上角,高频分量分布在右下角(DCT变换实际上是空间域的低通滤波器)。由于该低频分量包含了图象的主要信息(如亮度),而高频与之相比,就不那么重要了,所以我们可以忽略高频分量,从而达到压缩的目的。如何将高频分量去掉,这就要用到量化,它是产生信息损失的根源。这里的量化操作,就是将某一个值除以量化表中对应的值。由于量化表左上角的值较小,右上角的值较大,这样就起到了保持低频分量,抑制高频分量的目的。JPEG使用的颜色是YUV格式。我们提到过,Y分量代表了亮度信息,UV分量代表了色差信息。相比而言,Y分量更重要一些。我们可以对Y采用细量化,对UV采用粗量化,可进一步提高压缩比。所以上面所说的量化表通常有两张,一张是针对Y的;一张是针对UV的。
上面讲了,经过DCT变换后,低频分量集中在左上角,其中F(0,0)(即第一行第一列元素)代表了直流(DC)系数,即8×8子块的平均值,要对它单独编码。由于两个相邻的8×8子块的DC系数相差很小,所以对它们采用差分编码DPCM,可以提高压缩比,也就是说对相邻的子块DC系数的差值进行编码。8×8的其它63个元素是交流(AC)系数,采用行程编码。这里出现一个问题:这63个系数应该按照怎么样的顺序排列?为了保证低频分量先出现,高频分量后出现,以增加行程中连续“0”的个数,这63个元素采用了“之”字型(Zig-Zag)的排列方法,如图9.5所示。

图9.5 Zig-Zag
这63个AC系数行程编码的码字用两个字节表示,如图9.6所示。

图9.6 行程编码
上面,我们得到了DC码字和 AC行程码字。为了进一步提高压缩比,需要对其再进行熵编码,这里选用Huffman编码,分成两步:
(1)熵编码的中间格式表示
对于AC系数,有两个符号。符号1为行程和尺寸,即上面的(RunLength,Size)。(0,0)和(15,0)是两个比较特殊的情况。(0,0)表示块结束标志(EOB),(15,0)表示ZRL,当行程长度超过15时,用增加ZRL的个数来解决,所以最多有三个ZRL(3×16+15=63)。符号2为幅度值(Amplitude)。
对于DC系数,也有两个符号。符号1为尺寸(Size);符号2为幅度值(Amplitude)。
(2)熵编码
对于AC系数,符号1和符号2分别进行编码。零行程长度超过15个时,有一个符号(15,0),块结束时只有一个符号(0,0)。
对符号1进行Hufffman编码(亮度,色差的Huffman码表不同)。对符号2进行变长整数VLI编码。举例来说:Size=6时,Amplitude的范围是-63~-32,以及32~63,对绝对值相同,符号相反的码字之间为反码关系。所以AC系数为32的码字为100000,33的码字为100001,-32的码字为011111,-33的码字为011110。符号2的码字紧接于符号1的码字之后。
对于DC系数,Y和UV的Huffman码表也不同。
掉了这么半天的书包,你可能已经晕了,呵呵。举个例子来说明上述过程就容易明白了。
下面为8×8的亮度(Y)图象子块经过量化后的系数。
15 0 -1 0 0 0 0 0
-2 -1 0 0 0 0 0 0
-1 -1 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
可见量化后只有左上角的几个点(低频分量)不为零,这样采用行程编码就很有效。
第一步,熵编码的中间格式表示:先看DC系数。假设前一个8×8子块DC系数的量化值为12,则本块DC系数与它的差为3,根据下表
Size Amplitude
0 0
1 –1,1
2 –3,-2,2,3
3 –7~-4,4~7
4 –15~-8,8~15
5 –31~-16,16~31
6 –63~-32,32~63
7 –127~-64,64~127
8 –255~-128,128~255
9 –511~-256,256~511
10 –1023~512,512~1023
11 –2047~-1024,1024~2047
查表得Size=2,Amplitude=3,所以DC中间格式为(2)(3)。
下面对AC系数编码。经过Zig-Zag扫描后,遇到的第一个非零系数为-2,其中遇到零的个数为1(即RunLength),根据下面这张AC系数表:
Size Amplitude
1 –1,1
2 –3,-2,2,3
3 –7~-4,4~7
4 –15~-8,8~15
5 –31~-16,16~31
6 –63~-32,32~63
7 –127~-64,64~127
8 –255~-128,128~255
9 –511~-256,256~511
10 –1023~512,512~1023
查表得Size=2。所以RunLength=1,Size=2,Amplitude=3,所以AC中间格式为(1,2)(-2)。
其余的点类似,可以求得这个8×8子块熵编码的中间格式为
(DC)(2)(3),(1,2)(-2),(0,1)(-1),(0,1)(-1),(0,1)(-1),(2,1)(-1),(EOB)(0,0)
第二步,熵编码:
对于(2)(3):2查DC亮度Huffman表得到11,3经过VLI编码为011;
对于(1,2)(-2):(1,2)查AC亮度Huffman表得到11011,-2是2的反码,为01;
对于(0,1)(-1):(0,1)查AC亮度Huffman表得到00,-1是1的反码,为0;
……
最后,这一8×8子块亮度信息压缩后的数据流为11011, 1101101, 000, 000, 000, 111000,1010。总共31比特,其压缩比是64×8/31=16.5,大约每个象素用半个比特。
可以想见,压缩比和图象质量是呈反比的,以下是压缩效率与图象质量之间的大致关系,可以根据你的需要,选择合适的压缩比。
表9.1 压缩比与图象质量的关系
| 压缩效率(单位:bits/pixel) |
图象质量 |
| 0.25~0.50 |
中~好,可满足某些应用 |
| 0.50~0.75 |
好~很好,满足多数应用 |
| 0.75~1.5 |
极好,满足大多数应用 |
| 1.5~2.0 |
与原始图象几乎一样 |
以上我们介绍了JPEG压缩的原理,其中DC系数使用了预测编码DPCM,AC系数使用了变换编码DCT,二者都使用了熵编码Huffman,可见几乎所有传统的压缩方法在这里都用到了。这几种方法的结合正是产生JPEG高压缩比的原因。顺便说一下,该标准是JPEG小组从很多种不同中方案中比较测试得到的,并非空穴来风。
上面介绍了JPEG压缩的基本原理,下面介绍一下JPEG的文件格式。
2. JPEG的文件格式
JPEG文件大体上可以分成以下两个部分:标记码(Tag)加压缩数据。先介绍标记码部分。
标记码部分给出了JPEG图象的所有信息(有点类似于BMP中的头信息,但要复杂的多),如图象的宽、高、Huffman表、量化表等等。标记码有很多,但绝大多数的JPEG文件只包含几种。标记码的结构为:
SOI
DQT
DRI
SOF0
DHT
SOS
…
EOI
标记码由两个字节组成,高字节为0XFF,每个标记码之前可以填上个数不限的填充字节0XFF。
下面介绍一些常用的标记码的结构及其含义。
(1)SOI(Start of Image)
标记结构 字节数
0XFF 1
0XD8 1
可作为JPEG格式的判据(JFIF还需要APP0的配合)
(2)APP0(Application)
标记结构 字节数 意义
0XFF 1
0XE0 1
Lp 2 APP0标记码长度,不包括前两个字节0XFF,0XE0
Identifier 5 JFIF识别码 0X4A,0X46,0X49,0X46,0X00
Version 2 JFIF版本号 可为0X0101或者0X0102
Units 1 单位,等于零时表示未指定,为1表示英寸,为2表示
厘米
Xdensity 2 水平分辨率
Ydensity 2 垂直分辨率
Xthumbnail 1 水平点数
Ythumbnail 1 垂直点数
RGB0 3 RGB的值
RGB1 3 RGB的值
…
RGBn 3 RGB的值,n=Xthumbnail*Ythumbnail
APP0是JPEG保留给Application所使用的标记码,而JFIF将文件的相关信息定义在此标记中。
(3)DQT(Define Quantization Table)
标记结构 字节数 意义
0XFF 1
0XDB 1
Lq 2 DQT标记码长度,不包括前两个字节0XFF,0XDB
(Pq,Tq) 1 高四位Pq为量化表的数据精确度,Pq=0时,Q0~Qn的
值为8位,Pq=1时,Qt的值为16位,Tq表示量化表的
编号,为0~3。在基本系统中,Pq=0,Tq=0~1,也就是
说最多有两个量化表。
Q0 1或2 量化表的值,Pq=0时;为一个字节,Pq=1时,为两个
字节
Q1 1或2 量化表的值,Pq=0时;为一个字节,Pq=1时,为两个
字节
…
Qn 1或2 量化表的值,Pq=0时,为一个字节;Pq=1时,为两个
字节。n的值为0~63,表示量化表中64个值(之字形排
列)
(4)DRI(Define Restart Interval)
此标记需要用到最小编码单元(MCU,Minimum Coding Unit)的概念。前面提到,Y分量数据重要,UV分量的数据相对不重要,所以可以只取UV的一部分,以增加压缩比。目前支持JPEG格式的软件通常提供两种取样方式YUV411和YUV422,其含义是YUV三个分量的数据取样比例。举例来说,如果Y取四个数据单元,即水平取样因子Hy乘以垂直取样因子Vy的值为4,而U和V各取一个数据单元,即Hu×Vu=1,Hv×Vv=1。那么这种部分取样就称为YUV411。如图9.7所示:
| 图9.7 YUV411的示意图 |
图9.8 YUV111的排列顺序 |
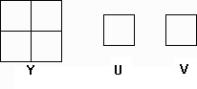

易知YUV411有50%的压缩比(原来有12个数据单元,现在有6个数据单元),YUV422有33%的压缩比(原来有12个数据单元,现在有8个数据单元)。
那么你可能会想,YUV911,YUV1611压缩比不是更高嘛?但是要考虑到图象质量的因素。所以JPEG标准规定了最小编码单元MCU,要求Hy×Vy+Hu×Vu+Hv×Vv≤10。
MCU中块的排列方式与H,V的值有密切关系,如图9.8、图9.9、图9.10所示。
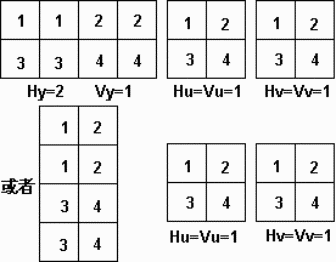
图9.9 YUV211的排列顺序

图9.10 YUV411的排列顺序
标记结构 字节数 意义
0XFF 1
0XDD 1
Lr 2 DRI标记码长度,不包括前两个字节0XFF,0XDD
Ri 2 重入间隔的MCU个数,Ri必须是一MCU行中MCU
个数的整数,最后一个零头不一定刚好是Ri个MCU。
每个重入间隔各自独立编码。
(5)SOF(Start of Frame) 在基本系统中,只处理SOF0
标记结构 字节数 意义
0XFF 1
0XC0 1
Lf 2 SOF标记码长度,不包括前两个字节0XFF,0XC0
P 1 基本系统中,为0X08
Y 2 图象高度
X 2 图象宽度
Nf 1 Frame中的成分个数,一般为1或3,1代表灰度图,3
代表真彩图
C1 1 成分编号1
(H1,V1) 1 第一个水平和垂直采样因子
Tq1 1 该量化表编号
C2 1 成分编号2
(H2,V2) 1 第二个水平和垂直采样因子
Tq2 1 该量化表编号
…
Cn 1 成分编号n
(Hn,Vn) 1 第n个水平和垂直采样因子
Tqn 1 该量化表编号
(6)DHT(Define Huffman Table)
标记结构 字节数 意义
0XFF 1
0XC4 1
Lh 2 DHT标记码长度,不包括前两个字节0XFF,0XC4
(Tc,Th) 1
L1 1
L2 1
…
L16 1
V1 1
V2 1
…
Vt 1
Tc为高4位,Th为低4位。在基本系统中,Tc为0或1,为0时,指DC所用的Huffman表,为1时,指AC所用的Huffman表。Th表示Huffman表的编号,在基本系统中,其值为0或1。所以,在基本系统中,最多有4个Huffman表,如下所示:
Tc Th Huffman表编号(2×Tc+Th)
0 0
1 1
0 2
1 1 3
Ln表示每个n比特的Huffman码字的个数,n=1~16
Vt表示每个Huffman码字所对应的值,也就是我们前面所讲的符号1,对DC来说该值为(Size),对AC来说该值为(RunLength,Size)。
t=L1+L2+…L16
(7)SOS(Start of Scan)
标记结构 字节数 意义
0XFF 1
0XDA 1
Ls 2 DHT标记码长度,不包括前两个字节0XFF,0XDA
Ns 1
Cs1 1
(Td1,Ta1) 1
Cs2 1
(Td2,Ta2) 1
…
CsNs 1
(TdNs,TaNs) 1
Ss 1
Se 1
(Ah,Al) 1
Ns为Scan中成分的个数,在基本系统中,Ns=Nf(Frame中成分个数)。CSNs为在Scan中成分的编号。TdNs为高4位,TaNs为低4位,分别表示DC和AC编码表的编号。在基本系统中Ss=0,Se=63,Ah=0,Al=0。
(8)EOI(End of Image) 结束标志
标记结构 字节数 意义
0XFF 1
0XD9 1
3. JPEG基本系统解码器的实现
笔者曾经实现了一个Windows下JPEG基本系统的解码器,限于篇幅,这里就不给源程序了,只给出大体上的程序流程图(见图9.11)。
| 图9.11 JPEG解码器的程序流程图 |
图9.12 程序运行时的画面 |


由于没有用到什么优化算法,该解码器的速度并不高,在用VC的性能评测工具Profile评测该程序时我发现最耗时的地方是反离散余弦变换(IDCT)那里,其实这是显然的,浮点数的指令条数要比整数的多得多,因此采用一种快速的IDCT算法能很大的提高性能,我这里采用是目前被认为比较好的一种快速IDCT算法,其主要思想是把二维IDCT分解成行和列两个一维IDCT。图9.12是程序运行时的画面。
符:
3、离散余弦变换 DCT
将图像从色彩域转换到频率域,常用的变换方法有:
DCT变换的公式为:
f(i,j) 经 DCT 变换之后,F(0,0) 是直流系数,其他为交流系数。
还是举例来说明一下。
8x8的原始图像:
推移128后,使其范围变为 -128~127:
使用离散余弦变换,并四舍五入取最接近的整数:
上图就是将取样块由时间域转换为频率域的 DCT 系数块。
DCT 将原始图像信息块转换成代表不同频率分量的系数集,这有两个优点:其一,信号常将其能量的大部分集中于频率域的一个小范围内,这样一来,描述不重要的分量 只需要很少的比特数;其二,频率域分解映射了人类视觉系统的处理过程,并允许后继的量化过程满足其灵敏度的要求。
当u,v = 0 时,离散余弦正变换(DCT)后的系数若为F(0,0)=1,则离散余弦反变换(IDCT)后的重现函数 f(x,y)=1/8,是个常 数值,所以将 F(0,0) 称为直流(DC)系数;当 u,v≠0 时,正变换后的系数为 F(u,v)=0,则反变换后的重现函数 f(x,y) 不是常数,此时 正变换后的系数 F(u,v) 为交流(AC)系数。
DCT 后的64个 DCT 频率系数与 DCT 前的64个像素块相对应,DCT 过程的前后都是64个点,说明这个过程只是一个没有压缩作用的无损变换过程。
单独一个图像的全部 DCT 系数块的频谱几乎都集中在最左上角的系数块中。
DCT 输出的频率系数矩阵最左上角的直流 (DC)系数幅度最大,图中为-415;以 DC 系数为出发点向下、向右的其它 DCT 系数,离 DC 分量越远,频率越高,幅度值越小,图中最右下角为2,即图像信息的大部分集中于直流系数及其附近的低频频谱上,离 DC 系数越来越远的高频频谱几乎不含图像信息,甚至于只含杂波。
DCT 本身虽然没有压缩作用,却为以后压缩时的"取"、"舍" 奠定了必不可少的基础。
4、量化
量化过程实际上就是对 DCT 系数的一个优化过程。它是利用了人眼对高频部分不敏感的特性来实现数据的大幅简化。
量化过程实际上是简单地把频率领域上每个成份,除以一个对于该成份的常数,且接着四舍五入取最接近的整数。
这是整个过程中的主要有损运算。
以这个结果来说,经常会把很多高频率的成份四舍五入而接近0,且剩下很多会变成小的正或负数。
整个量化的目的是减小非“0”系数的幅度以及增加“0”值系数的数目。
量化是图像质量下降的最主要原因。
因为人眼对亮度信号比对色差信号更敏感,因此使用了两种量化表:亮度量化值和色差量化值。
使用这个量化矩阵与前面所得到的 DCT 系数矩阵:
如,使用?415(DC系数)且四舍五入得到最接近的整数
总体上来说,DCT 变换实际是空间域的低通滤波器。对 Y 分量采用细量化,对 UV 采用粗量化。
量化表是控制 JPEG 压缩比的关键,这个步骤除掉了一些高频量;另一个重要原因是所有图片的点与点之间会有一个色彩过渡的过程,大量的图像信息被包含在低频率中,经过量化处理后,在高频率段,将出现大量连续的零。
5、“Z”字形编排
量化后的数据,有一个很大的特点,就是直流分量相对于交流分量来说要大,而且交流分量中含有大量的0。这样,对这个量化后的数据如何来进行简化,从而再更大程度地进行压缩呢。
这就出现了“Z”字形编排,如图:
对于前面量化的系数所作的 “Z”字形编排结果就是:
底部 ?26,?3,0,?3,?3,?6,2,?4,1 ?4,1,1,5,1,2,?1,1,?1,2,0,0,0,0,0,?1,?1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 顶部
这样做的特点就是会连续出现多个0,这样很有利于使用简单而直观的行程编码(RLE:Run Length Coding)对它们进行编码。
8×8图像块经过 DCT 变换之后得到的 DC 直流系数有两个特点,一是系数的数值比较大,二是相邻8×8图像块的 DC 系数值变化不大。根据这个特点,JPEG 算法使用了差分脉冲调制编码(DPCM)技术,对相邻图像块之间量化 DC 系数的差值(Delta)进行编码。即充分利用相邻两图像块的特性,来再次简化数据。
即上面的 DC 分量-26,需要单独处理。
而对于其他63个元素采用zig-zag(“Z”字形)行程编码,以增加行程中连续0的个数。
http://www.360doc.com/content/07/0703/09/2228_591692.shtml