《集体智慧编程》读书笔记 3 - 神经网络
使用神经网络来帮助建立搜索关键词所响应的页面
对于搜索引擎而已,每一位用户可以通过只点击某条搜索结果,而不选择点击其他内容,从而向引擎及时提供有关于他对搜索结果喜好程度的信息。
为此,我们可以构造一个神经网络,向该网络提供:查询的单词,返回给用户的搜索结果,以及用户的点击决策,然后对该神经网络加以训练。
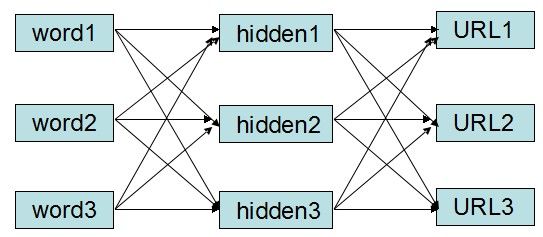
图1 多层感知机
由多层神经元构成的网络称为多层感知机(multilayer perception,MLP)。
为什么我们不是简单地记录下查询条件以及每个搜索结果被点击的次数,而要使用如此复杂的神经网络呢?
因为神经网络的威力在于,它能根据与其他查询结果相似度的情况,对以前从未见过的查询结果给出合理的猜测。
为了实现这个神经网络,我们需要建立几张表。
①word和URL的映射表
②hiddenNode的表
③word2hiddenNode的表
④hiddenNode2URL的表
前馈法
前馈法就是按照网络正向传播的意思。
例如:我们有一个3个单词的列表,以及一个3个URL的列表:
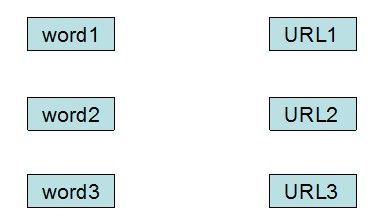
图2 输入及输出列表
现在,我们输入了word1和word3,意味着word1和word3这两个输入节点被激活,它们的输出为1。现在,我们新建一个隐藏层节点(假设没执行一次不存在的单词查询就产生一个新的隐藏层节点),该隐藏层节点的输入即为输入层节点的输出:
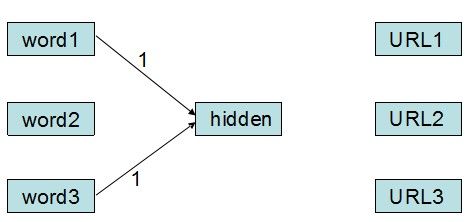
图3 输入被激活
除了上一层节点给自己的输入外,对于每一个神经元连接而言还有一个重要的参数,那就是权重值。此处,我们假设word2hiddenNode的权重值为1/len(words),hiddenNode2URL的权重值为0.1,故有:
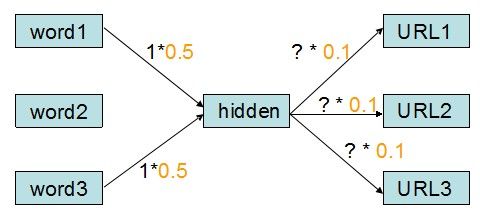
图4 带权重的神经元连接
现在,我们的任务是要确定这三个“?”所对应的值是什么。显然,它们是hiddenNode的输出值。hiddenNode的输出值的计算方式为:
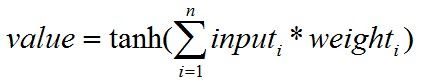
公式1 神经元输出值的计算方法
通俗地说,就是将它的每一个输入连接上的值乘以该连接的权重,求和后,再经过一个tanh函数(如下图)求得结果。
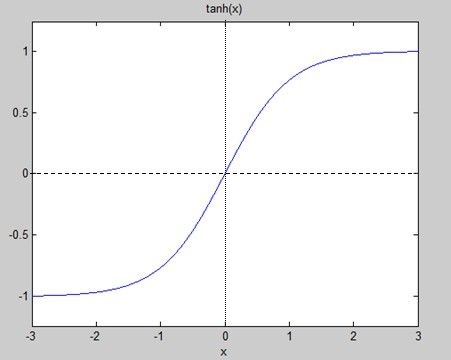
图5 tanh函数
本例中,value=tanh(1 * 0.5 + 1 * 0.5) = tanh(1) = 0.76
现在,我们知道图4中“?”的值为0.76。下一步,我们就可以计算各个URL输出的值了。
计算的方法也是公式1,因此
URL1_output = tanh(0.76 * 0.1) = tanh(0.076) = 0.076
同理,URL2_output = URL3_output = 0.076
以上就是整个前馈法的计算过程,重点就是神经元连接的权重的设定以及求和后经过的响应函数(本例中选用tanh函数)。响应函数用来指示每个节点对输入的响应程度,一般选取S型函数(tanh就是S型函数的一种)。
现在,通过前馈法我们得出网络在接受word1和word3的激励后,整个网络的反应和输出是:

图6 前馈法输出
可能大家会比较奇怪,为什么输出都是一样的?输出一样的情况下我们怎么知道那个URL应该排在前面哪个应该排在后面呢?不要着急,这是因为该网络还没有经过训练,不知道在word1和word3这样的组合激励下,应该输出那个URL才是对的。我们可以利用一些样本来训练它,让它可以调整神经元之间连接的权重,以达到能将各个URL区别开(哪个是相关度高的的、哪个是相关度低的)的目的。
PS:书的这个地方有一个印刷错误,就是前馈法的输出应该是(0.076,0.076,0.076),而不是(0.76,0.76,0.76)……算了半天啊,一直跟书上的结果差一位小数点,原来是印刷错误。
反向传播
通过前面前馈法的介绍,我们知道,如果不告诉神经网络什么是正确的什么是错误的,那么单单利用网络本身的计算能力,是不足以区分各个输出之间的不同之处的。神经网络之所以有趣,就在于可以通过调节神经元之间连接的权重,来训练该网络,使它可以对未知的输入做出跟训练样本相似的选择(训练样本就是用来训练权重的)。
现在我们来尝试进行一次反向传播,以调节神经网络中各个连接的权重。
再来回顾一下图6,假设输出URL1才是正确的(也就是用户输入word1和word3这一组合时,会希望出现URL1),那么我们可知我们的目标为URL1,即target[URL1]=1,其他targe[URLx]=0,如下图:
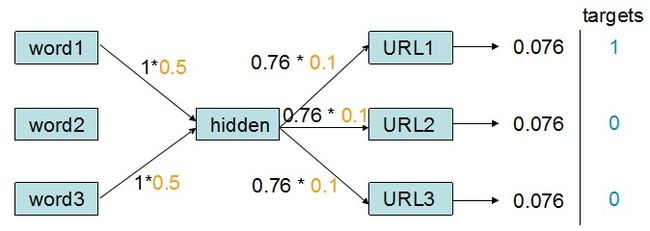
图7 为神经网络提供一个训练样本
通过训练样本,我们就可以计算出误差的大小。误差的计算公式为:
error = target - URL_output
公式2 输出层误差计算公式
故有:
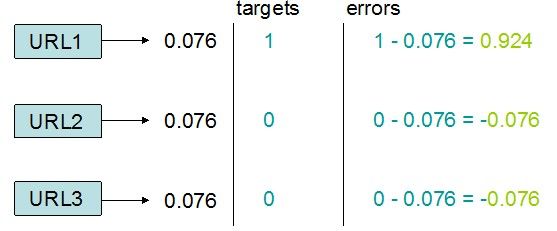
图8 输出层误差计算
知道了每一个URL的输出误差后,我们现在来逐层计算各个神经元输出值的误差梯度。
输出层的误差梯度计算公式,其中k为输出层的第k个元素:
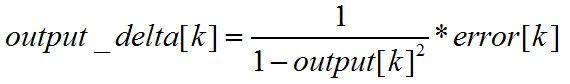
公式3 输出层误差梯度计算公式
这样,我们就可以计算得三个URL输出的误差梯度值:
output_delta[1] = 1/(1-0.0762) * 0.924 = 0.9294
output_delta[2] = 1/(1-0.0762) * (-0.076) = -0.0764
output_delta[3] = 1/(1-0.0762) * (-0.076) = -0.0764
输出层的误差梯度计算完后,我们来计算隐藏层的误差梯度,计算方法的伪代码是:
hidden_deltas = [0.0] * len(hiddenIDs) for j range(len(hiddenIDs)): error = 0.0 for k in range(len(URL_IDs)): error = error + output_delta[k] * weight_of_output[j][k] hidden_delta[j] = (1/(1-hiddenNode_value[j])) * error
即
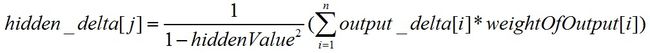
公式4 隐藏层误差梯度的计算方法
由于示例中只有一个隐藏层,因此可以方便的计算出它的误差梯度为:
hidden_delta = 1/(1-0.762) * (0.9294*0.1 - 0.0764*0.1 - 0.0764*0.1) = 0.1839
现在误差梯度已经得出,那么我们可以计算新的权重值了。
计算的方法是:
change = 梯度 * 神经元的值
new_weight = old_weight + change * 系数
PS:设 系数 = 0.5
更新隐藏层输出的权重
change1 = 0.9294 * 0.76 = 0.7063
wo1 = 原wo1 + change1 * 0.5 = 0.1 + 0.7063 * 0.5 = 0.4532
change2 = -0.0764 * 0.76 = -0.0581
wo2 = 原wo2 + change2 * 0.5 = 0.1 - 0.0571 * 0.5 = 0.0419
同理,wo3 = 0.0419
更新隐藏层输入的权重
change1 = 0.1839 * 1 = 0.1839
wi1 = 原wi1 + change1 * 0.5 = 0.5 + 0.09195 = 0.5920
同理,wi2 = 0.5920
在更新了权重之后,示例中的神经网络(带权重)变为:
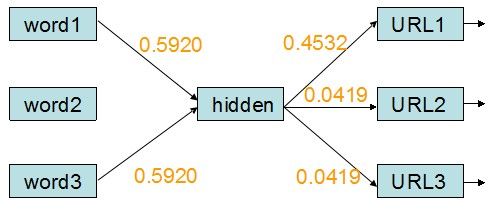
图9 更新权重后的神经网络
现在,我们再重新输入word1和word3,则神经网络的反应为:
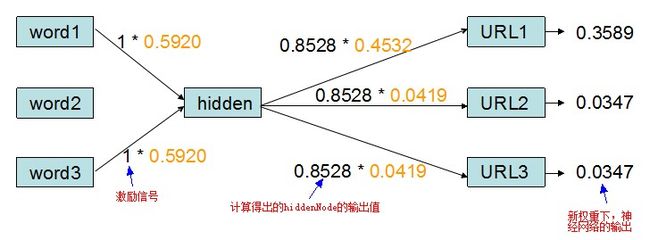
图10 新权重下神经网络的输出值
可以看到在经过训练以后,神经网络的权重自动调整到适应样本的状态。
在反向传播这里,书中还是有一个错误的地方,即dtanh函数的定义,应该为1/(1-y*y),而不是1-y*y。原因如下:
“The formulas to calculate output_deltas and hidden_deltas are wrong. According to the Delta Rule (http://en.wikipedia.org/wiki/Delta_rule), either these formulas should be error divided by dtanh, or the dtanh itself should be 1/(1-y*y).”
关于delta Rule可以看看wikipedia的介绍,我也在学习中。
本书的勘误表见此处:
http://oreilly.com/catalog/errataunconfirmed.csp?isbn=9780596529321