java虚拟机(四)探秘Java虚拟机——内存管理与垃圾回收(补充说明)
说明:以下大部分文字均摘自网络上的某些“童鞋”的优秀文章。
一、对于GC的性能其实主要考虑以下两个方面:
1、吞吐率throughput【工作时间(不包括GC的时间)占总运行的时间比】
2、暂停pause(GC发生时应用程序无法响应用户的请求)
二、对于GC的性能可以从以下方面考虑:
1、整个堆空间
对于Server端的应用程序,有以下最佳实践:
1)对于JVM分配尽可能多的内存空间。
2)固定堆空间的大小,将Xms和Xmx设为一样的值。如果让JVM自行控制堆空间大小的话,虚拟机启动时分配的堆空间比较小,如果在程序运行过程中还需要初始化很多对象,虚拟
机就必须重复地增加内存,造成GC频率的增加。
3)横向增加服务器的数量,为程序服务的JVM内存总量也随着增大。
2、新生代
从整体上看,新生代越大,minor GC就会越少。但由于我们一般是固定的堆内存空间,因此更大的新生代也就意味着更小的老生代,更小的老生代会带来更多的Full GC(Full GC会伴随
有minor GC)。
参数NewRatio反映的是新生代和老生代的大小比例。NewSize和MaxNewSize反映的是新生代空间的下限和上限,将这两个值设为一样就固定了新生代的大小(或者直接通过指定
Xms、Xmx和Xmn的大小来固定新生代的大小)。SurvivorRatio可以指定survivor区的大小,SurvivorRatio是eden区和survior区的大小比例。
一般而言,server端的app会有以下最佳实践:
1)首先固定heap空间的大小,然后设定最佳的新生代空间的大小;
2)如果堆空间固定后,增加新生代的大小就意味着减小老生代的大小。因此在调节时应特别留意,让老生代至少能够保留10%-20%的空余空间,并能够容纳所有live的对象。
三、最佳实践:
1)年轻代大小的选择
响应时间优先的应用:尽可能增大新生代的大小,直到接近系统的最低响应时间限制(根据实际情况选择)。在此种情况下,新生代收集发生的频率也是最小的。同时,减少到达年老代
的对象,从而减少Full GC的发生几率。
吞吐量优先的应用:尽可能增大新生代的大小,可能到达Gbit的程度。因为对响应时间没有要求,垃圾收集可以并行进行,一般适合8CPU以上的应用系统。
避免设置过小:当新生代设置过小时会导致:1、minor GC的次数更加频繁 2、可能导致minor GC对象直接进入老生代,如果此时老生代满了,会触发Full GC.
2)年老代大小选择
响应时间优先的应用:老生代使用并发收集器(CMS GC),所以其大小需要小心设置,一般要考虑并发会话率和会话持续时间等一些参数。如果堆设置小了,可以会形成内存碎片,高
回收频率以及应用暂停。而使用传统的标记清除方式,如果堆设置大了,则需要较长的收集时间。最优化的方案,一般需要参考以下数据获得:并发垃圾收集信息、永久代并发收集次数、传
统GC信息、花在新生代和老生代回收上的时间比例。
吞吐量优先的应用:一般吞吐量优先的应用都有一个很大的新生代和一个较小的老生代。原因是这样可以尽可能回收掉大部分短期对象,减少中期的对象,而老生代尽存放长期存活对象。
3)其他
较小堆引起的碎片问题:因为老生代的并发收集器使用标记清除算法,所以不会对堆进行压缩。当收集器回收时,它会把相邻的空间进行合并,这样可以分配给较大的对象。但是,当
堆空间较小时,运行一段时间以后,就会出现"碎片",如果并发收集器找不到足够的空间,那么并发收集器将会停止,然后使用传统的标记清除方式进行回收。如果出现"碎片",可能需要
进行如下配置:
-XX:+UseCMSCompactAtFullCollection:使用并发收集器时,开启对年老代的压缩。
-XX:CMSFullGCsBeforeCompaction=0:上面配置开启的情况下,这里设置多少次Full GC后,对年老代进行压缩。
用64位操作系统。Linux下64位的jdk比32位jdk要慢一些,但是吃得内存更多,吞吐量更大。
XMX和XMS设置一样大,MaxPermSize和MinPermSize设置一样大,这样可以减轻伸缩堆大小带来的压力 。
使用CMS GC的好处是用尽量少的新生代,经验值是128M-256M, 然后老生代利用CMS并行收集, 这样能保证系统低延迟的吞吐效率。 实际上CMS GC的收集停顿时间非常的短,
2G的内存大约20-80ms的应用程序停顿时间。
减少程序停顿时间:系统停顿的时间可能是GC的问题也可能是程序的问题,多用jmap和jstack查看或者killall -3 java,然后查看java控制台日志,能看出很多问题。有一次,网站突然
很慢,利用jstack一看,原来是自己写的URLConnection连接太多没有释放造成的。
程序应用缓存的问题:如果程序应用了缓存,那么老生代应该设置的大一些,缓存的HashMap不应该无限制增长,建议采用LRU算法的Map做缓存,LRU Map(例如Jakarta
Commons中提供的org.apache.commons.collections.map.LRUMap)的最大长度也要根据实际情况设定。
采用并发回收时,新生代小一点,老生代要大,因为老生代用的是并发回收,即使时间长点也不会影响其他程序继续运行,网站不会停顿。
JVM 参数的设置(特别是 –Xmx –Xms –Xmn -XX:SurvivorRatio -XX:MaxTenuringThreshold等参数的设置没有一个固定的公式,需要根据PV、老生代实际数据、新生代GC次数等
多方面来衡量。为了避免promotion faild,可能会导致xmn设置偏小,也意味着新生代GC的次数会增多,处理并发访问的能力下降等问题。每个参数的调整都需要经过详细的性能测试,
才能找到特定应用的最佳配置。
打印GC日志:调试的时候设置一些打印参数,如-XX:+PrintClassHistogram -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:log/gc.log,这样可
以从gc.log里看出一些问题出来。
4)promotion failed(晋升失败):第一个原因是担保空间不够,担保空间里的对象还不应该被移动到老生代,但新生代又有很多对象需要放入担保空间;第二个原因是老生代没有足够的空间接纳来自新生代的对象;这两种情况都会转向Full GC,网站停顿时间较长。
解决方方案一:
第一个原因我的最终解决办法是去掉担保空间,设置-XX:SurvivorRatio=65536 -XX:MaxTenuringThreshold=0即可,第二个原因我的解决办法是设置
CMSInitiatingOccupancyFraction为某个值(假设70),这样老生代空间到70%时就开始执行CMS,老生代有足够的空间接纳来自新生代的对象。
方案一的改进方案:
方案一中没有用到担保空间,所以老生代容易满,CMS执行会比较频繁。我改善了一下,还是用担保空间,但是把担保空间加大,这样也不会有promotion failed。具体操作上,32位Linux和64位Linux好像不一样,64位系统似乎只要配置MaxTenuringThreshold参数,CMS还是有暂停。为了解决暂停问题和promotion failed问题,最后我设置-
XX:SurvivorRatio=1 ,并把MaxTenuringThreshold去掉,这样即没有暂停又不会有promotoin failed,而且更重要的是,老生代和永久代上升非常慢(因为好多对象到不了年老代就
被回收了),所以CMS执行频率非常低,好几个小时才执行一次,这样,服务器都不用重启了。
-Xmx4000M -Xms4000M -Xmn600M -XX:PermSize=500M -XX:MaxPermSize=500M -Xss256K -XX:+DisableExplicitGC -XX:SurvivorRatio=1
-XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0
-XX:+CMSClassUnloadingEnabled -XX:LargePageSizeInBytes=128M -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+PrintClassHistogram -XX:+PrintGCDetails -XX:+PrintGCTimeStamps
-XX:+PrintHeapAtGC -Xloggc:log/gc.log
5)CMSInitiatingOccupancyFraction值与Xmn的关系公式
上面介绍了promontion faild产生的原因是Eden空间不足的情况下将Eden与From survivor中的存活对象存入To survivor区时,To survivor区的空间不足,再次晋升到old gen区,
而old gen区内存也不够的情况下产生了promontion faild从而导致full gc。那可以推断出:eden+from survivor < old gen区剩余内存时,不会出现promontion faild的情况,即:
(Xmx-Xmn)*(1-CMSInitiatingOccupancyFraction/100)>=[Xmn-Xmn/(SurvivorRatior+2)] 进而推断出:
CMSInitiatingOccupancyFraction <={(Xmx-Xmn)-[Xmn-Xmn/(SurvivorRatior+2)]}/(Xmx-Xmn)*100
例如:
当Xmx=128 Xmn=36 SurvivorRatior=1时 CMSInitiatingOccupancyFraction<=((128.0-36)-(36-36/(1+2)))/(128-36)*100 =73.913
当Xmx=128 Xmn=24 SurvivorRatior=1时 CMSInitiatingOccupancyFraction<=((128.0-24)-(24-24/(1+2)))/(128-24)*100=84.615…
当Xmx=3000 Xmn=600 SurvivorRatior=1时 CMSInitiatingOccupancyFraction<=((3000.0-600)-(600-600/(1+2)))/(3000-600)*100=83.33
当CMSInitiatingOccupancyFraction低于70% 需要调整Xmn或SurvivorRatior值。
四、内存泄露的分析
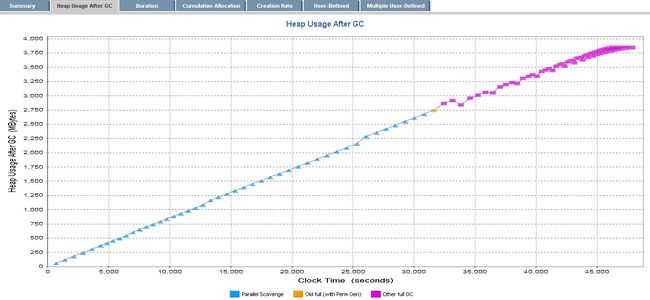
HPjmeter是一个GC的图形化分析工具,由上图可以看出GC始终无法回收heap内存空间,以使heap内存空间的使用量持续升高,明显存在内存泄露的可能性。定位内存泄露,可以生
成dump文件,并利用MAT进行分析,查找原因。
内存分析工具:
详细信息可参考文章http://qa.taobao.com/?p=14264。
JVM内存状况查看方案及工具:http://www.51testing.com/html/58/n-237858.html
使用 Eclipse Memory Analyzer 进行堆转储文件分析:http://www.ibm.com/developerworks/cn/opensource/os-cn-ecl-ma/index.html?ca=drs-
参考文献:
1、JVM系列三:JVM参数设置、分析 http://www.cnblogs.com/redcreen/archive/2011/05/04/2037057.html
2、一个典型的OutOfMemory分析过程 http://hbase.iteye.com/blog/1356450
3、使用MAT分析内存泄露 http://qa.taobao.com/?p=14264
4、JVM内存状况查看方法和分析工具 http://www.51testing.com/html/58/n-237858.html
5、使用 Eclipse Memory Analyzer 进行堆转储文件分析:http://www.ibm.com/developerworks/cn/opensource/os-cn-ecl-ma/index.html?ca=drs-