HBase Memstore Flush
我之前一直以为HBase 只会对那些达到了阈值的Memstore进行flush,虽然知道有个配置参数hbase.hregion.memstore.flush.size是控制这个阈值的,但是没想到level是HRegion,但是所有这些理解在读了Visualizing HBase Flushes And Compactions给出的测试结果后才发现当初自己理解错了,于是google一下,发现apache jire上有这样一个ticket,提出的问题如下:
Today, the flush decision is made using the aggregate size of all column families. When large and small column families co-exist, this causes many small flushes of the smaller CF. We need to make per-CF flush decisions.
下面列出两个比较有意思的comments供大家考:
Nicolas Spiegelberg
This is a substantial refactoring effort. My current development strategy is to break this down into 4 parts. Each one will have a diff + review board so you guys don't get overwhelmed...
1. move flushcache() from Region -> Store. have Region.flushcache loop through Store API
2. move locks from Region -> Store. figure out flush/compact/split locking strategy
3. refactor HLog to store per-CF seqnum info
4. refactor MemStoreFlusher from regionsInQueue to storesInQueue
Schubert Zhang
This jira is very useful in practice.
In HBase, the horizontal partitions by rowkey-ranges make regions, and the vertical partitions by column-family make stores. These horizontal and vertical partitoning schema make a data tetragonum — the store in hbase.
The memstore is base on the store, so the flush and compaction need also be based on store. The memstoreSize in HRegion should be in HStore.
For flexible configuration, I think we shlould be able to configure memstoresize (i.e. hbase.hregion.memstore.flush.size) in Column-Family level (when create table). And if possaible, I want the maxStoreSize also be configurable for different Column-Family.
可以看出hbase owner还是在Improvement这个问题,希望他们早日解决这个问题。当然我会再测试一下最新版本0.90的情况并结合代码给一些分析出来。
https://issues.apache.org/jira/browse/HBASE-3149
---------------------------------------分割线----------------------------------------
经过测试hbase 0.90发现,Memstore flush的确是按照上述分析去做的,下面上传的两张图都可以得出这个结论:
1)首先创建两个CF: edp1, edp2
2 )向edp1插入一条记录,因为hbase.hregion.memstore.flush.size设置为64M,所以肯定不会发生flush,而且通过admin web去查看,的确如此。
3 )向edp2插入大量记录,足以会让MemStore的大小超过设定的阈值,通过admin web去查看,有两个storefiles存在了,说明edp2的memstore超过阈值会导致其他的memstore也会被flush到disk。
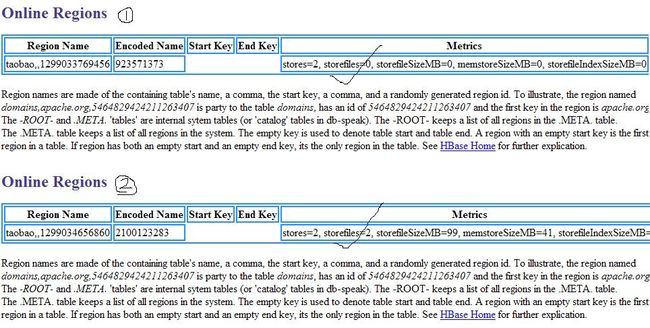
注:为什么edp2会有两个文件,因为关闭hbase一会,它会将memstore中的数据flush到新的storefile中!注意文件创建的时间,说明flush是在不同时间发生的。(疑问:为什么edp2的storefile大小>64M呢?原因很简单因为storefile除了要保存memstore里面的KeyValue,还要保存meta block, data block index, meta block index, file info and fixed file trailer,额外的这些信息占用了其他部分的空间)

-------------------------------------第二次更新该知识点----------------------
1)Within one region, if the sum of the memstores of the column families reaches hbase.hregion.memstore.flush.size, then the memstores of that region will be flushed.
But within one region server, there can be many (hundreds, thousands) of regions active, and thus hbase.hregion.memstore.flush.size applies to each of these regions individually, not to the sum of them. That is where hbase.regionserver.global.memstore.upperLimit comes into play.
2)Hbase memstore flush目前是使用单线程去干活,这是一个系统瓶颈,所以不可避免的将会实现多线程flush来解决这个问题,下面是jira上面的一个ticket,有兴趣仔细阅读一下:
Priorities and multi-threading for MemStore flushing
Flushes are currently triggered when:
1. MemStore size of an HRegion is > hbase.hregion.memstore.flush.size (checked after every memstore insertion)
2. Sum of MemStores of an HRegionServer are > total.memstore.heap (checked after every memstore insertion)
3. Number of HLogs of an HRegionServer are > max.hlogs (checked after every hlog roll?) TODO: Verify
4. HRegion is being closed (when receiving message from master)
5. HRegionServer is being quiesced (when receiving message from master)
6. Client manually triggers flush of an HRegion (when receiving message from master)
7. MemStore size of an HRegion is > memstore.flush.size * hbase.hregion.memstore.multiplier (checked before every memstore insertion)
There are 3 different types of flushes that correspond to these 6 events:
1. Low Priority Flush This occurs in response to #1. This is the lowest priority flush and does not need any tricks. All other flush types should be completed before any of this type are done. The one optimization it has is that if it determines that a compaction would be triggered after the flush finished, it should cancel the flush and instead trigger a CompactAndFlush.
2. High Priority Flush This occurs in response to #2, #3, #6, and #7. High priority flushes occur in response to memory pressure, WAL pressure, or because a user has asked for the flush. These flushes should occur before any low priority flushes are processed. They are only special because of their priority, otherwise the implementation of the flush is identical to a low priority flush. This flush type explicitly does not contain the CompactAndFlush check because it wants to flush as fast as possible.
3. High Priority Double Flush TODO: Region closing currently does flushing in-band rather than through the flush queue. Should move those into using handlers once we have blocking call. Therefore, double-flush priority is not currently used. TODO: Do we want a separate priority here once we do use this for closes? Or are they just high priority flushes? The first one is even a low priority flush, second one high priority? This occurs in response to #4. When an HRegion is being closed (but not when a cluster is being quiesced) we want to minimize the amount of time the region is unavailable. To do this we do a double flush. A flush is done, then the region is closed, then an additional flush is done before the region is available to be re-opened. This should happen when the Master asks a region to close because of reassignment. This may also occur before splits to reduce the amount of time the parent is offline before the daughters come back online.