Git Tutorial
Version 5.2
Copyright © 2009, 2010, 2011, 2012, 2013 Lars Vogel
18.02.2013
| Revision History | |||
|---|---|---|---|
| Revision 0.1 | 13.09.2009 | Lars Vogel |
Created |
| Revision 0.2 - 5.2 | 21.11.2009 - 18.02.2013 | Lars Vogel |
bug fixes and improvements |
Git Tutorial
This tutorial explains the usage of the distributed version control system Git via the command line. The examples were done on Linux (Ubuntu) but should also work on other operating systems like Microsoft Windows.
Table of Contents
- 1. Git
-
- 1.1. What is a version control system?
- 1.2. What is a distributed version control system?
- 1.3. What is Git?
- 1.4. Local repository and operations
- 1.5. Remote repositories
- 1.6. Branching and merging
- 1.7. Working tree
- 1.8. How to add changes to your Git repository
- 1.9. Committing and commit objects
- 2. Tools
- 3. Terminology
- 4. Installation
-
- 4.1. Ubuntu, Debian and derived systems
- 4.2. Fedora, Redhat and derived systems
- 4.3. Other Linux systems
- 4.4. Windows
- 4.5. Mac OS
- 5. Git Setup
-
- 5.1. Global configuration file
- 5.2. User Configuration
- 5.3. Push configuration
- 5.4. Avoid merge commits for pulling
- 5.5. Color Highlighting
- 5.6. Setting the default editor
- 5.7. Query existing global Git settings
- 6. Ignore certain files
- 7. Tracking empty directories with .gitkeep
- 8. Getting started with Git
-
- 8.1. Target of this chapter
- 8.2. Create directory
- 8.3. Create Git repository
- 8.4. Create content
- 8.5. See the current status of your repository
- 8.6. Add files to Git index
- 8.7. Commit to Git repository
- 9. Looking at the result
-
- 9.1. Results
- 9.2. Directory structure
- 10. Remove files and adjust the last commit
-
- 10.1. Remove files
- 10.2. Remove a file from the staging area
- 10.3. Correction of the last commit with git amend
- 11. Remote repositories
-
- 11.1. What are remote repositories?
- 11.2. Bare repositories
- 11.3. Setting up a remote (bare) Git repository
- 11.4. Cloning and the remote repository called "origin"
- 11.5. Adding more remote repositories
- 11.6. Show the existing remote repositories
- 12. Cloning remote repositories and push and pull
-
- 12.1. Clone your repository
- 12.2. Push changes to another repository
- 12.3. Pull changes
- 13. Online remote repositories
-
- 13.1. Cloning remote repositories
- 13.2. Add more remote repositories
- 13.3. Remote operations via http and a proxy
- 14. Whats are tags?
-
- 14.1. Whats are tags?
- 14.2. Lightweight and annotated tags
- 15. Tagging in Git
-
- 15.1. List existing tags
- 15.2. Creating annotated tags
- 15.3. Signed tags
- 15.4. Creating lightweight tags
- 15.5. Checkout tags
- 15.6. Push tags
- 15.7. Delete tags
- 16. What are branches?
- 17. Working with branches
-
- 17.1. List available branches
- 17.2. Create new branch
- 17.3. Rename a branch
- 17.4. Delete a branch
- 17.5. Push a branch to remote repository
- 18. Differences between branches
- 19. Remote and local tracking branches
-
- 19.1. Remote tracking branches
- 19.2. Delete a remote branch in your local repository
- 19.3. Delete a branch in a remote repository
- 19.4. Local tracking branches
- 19.5. See the branch information for a remote
- 20. Updating your remote branches with git fetch
-
- 20.1. Fetch
- 20.2. Fetch from all remote repositories
- 20.3. Compare remote tracking branch with local branch
- 20.4. Rebase your local branch based on the remote tracking branch
- 20.5. Fetch compared with pull
- 21. Merging branches
-
- 21.1. Merging
- 21.2. Fast-forward merge
- 21.3. Merge commit
- 21.4. Commands to merge two branches
- 22. Solving merge conflicts
-
- 22.1. What is a merge conflict
- 22.2. Example process for solving a merge conflict
- 23. Rebase
-
- 23.1. Rebasing branches
- 23.2. Rebasing commits in the same branch
- 23.3. Best practice for rebase
- 24. Selecting individual commits with git cherry-pick
-
- 24.1. Applying a single commit
- 24.2. Using cherry-pick
- 25. Stashing committed changes with git stash
-
- 25.1. Git stash definition
- 25.2.
- 26. Retrieving individual files
-
- 26.1. View file in different revision without checkout
- 26.2. See which commit deleted a file
- 27. Revert Changes
-
- 27.1. Revert changes in your working tree with git clean
- 27.2. Checkout existing versions from the index
- 27.3. Checkout commits versions
- 27.4. Remove staged changes for new files
- 27.5. Remove staged changes for previously committed files
- 27.6. Reverting a commit
- 27.7. Remove files based on .gitignore changes
- 28. Resetting commits
-
- 28.1. git reset to move the HEAD pointer
- 28.2. Finding commits which you have reset
- 28.3. git reset and deleting all unstaged files
- 29. Recovering lost commits
-
- 29.1. Detached HEAD
- 29.2. git reflog
- 29.3. Example
- 30. Define alias
-
- 30.1. What is an alias
- 30.2. Example alias
- 31. Error search with git bisect
-
- 31.1. What is git bisect
- 31.2. git bisect example
- 32. Submodules - Repos inside other Git repos
-
- 32.1. Why use submodules
- 32.2. Cloning submodules
- 33. Rewriting commit history with git filter-branch
-
- 33.1. Using git filter-branch
- 33.2. filter-branch example
- 34. Create and apply patches
-
- 34.1. What is a patch?
- 34.2. Create and apply patches
- 35. Git commit hooks
-
- 35.1. What are Git commit hooks
- 35.2. Client and server side commit hooks
- 36. Line endings on different platforms
- 37. Own Git server
-
- 37.1. Installing a Git server
- 37.2. Give write access to a Git repository
- 37.3. Security setup for the git user
- 38. Viewing changes in the working tree with git status
-
- 38.1. Viewing the status of the working tree with git status
- 38.2. Example
- 39. Viewing deltas (differences)
-
- 39.1. See unstaged changes since the last commit
- 39.2. See differences between index and last commit
- 39.3. See the difference between two commits
- 40. Analyzing changes in the repository
-
- 40.1. Repository history with Git log
- 40.2. See the files changed by a commit
- 40.3. View the change history of a file
- 40.4. Find out which commit deleted a file or directory
- 40.5. Analyzing line changes with git blame
- 41. Git Hosting Provider
-
- 41.1. ssh key
- 41.2. GitHub
- 41.3. Bitbucket
- 42. Typical Git workflow using separate repositories
-
- 42.1. Providing a patch
- 42.2. Working with two repositories
- 42.3. Using pull requests
- 43. Typical Git workflows with shared repositories
-
- 43.1. Working with a shared remote
- 44. Get the Kindle edition
- 45. Questions and Discussion
- 46. Links and Literature
1. Git
1.1. What is a version control system?
A version control system allows you to track the history of a collection of files and includes the functionality to revert the collection of files to another version. Each version captures a snapshot of the file system at a certain point in time. The collection of files is usually source code for a programming language but a typical version control system can put any type of file under version control.
The collection of files and their complete history are stored in a repository.
The process of creating different versions (snapshots) in the repository is depicted in the following graphic. Please note that this picture fits primarily to Git, another version control systems like CVS don't create snapshots but store deltas.
These snapshots can be used to change your collection of files. You may, for example, revert the collection of files to a state from 2 days ago. Or you may switch between versions for experimental features.
1.2. What is a distributed version control system?
A distributed version control system has not necessary a central server which stores the data.
The user can copy an existing repository. This copying process is typically called cloning in a distributed version control system.
Typically there is a central server for keeping a repository but each cloned repository is a full copy of this repository. The decision which of the copies is considered to be the central server repository is a pure convention and not tied to the capabilities of the distributed version control itself.
Every local copy contains the full history of the collection of files and a cloned repository has the same functionality as the original repository.
Every repository can exchange versions of the files with other repositories by transporting these changes. This is typically done via the selected central server repository.
1.3. What is Git?
Git is a distributed version control system.
Git originates from the Linux kernel development and is used by many popular Open Source projects, e.g. the Android or the Eclipse Open Source projects, as well as by many commercial organizations.
The core of Git was originally written in the programming language C but Git has also been re-implemented in other languages, e.g. Java and Python.
1.4. Local repository and operations
After cloning or creating a repository the user has a complete copy of the repository. The user performs version control operations against this local repository, e.g. create new versions, revert changes, etc.
There are two types of Git repositories:
-
bare repositories used on servers to share changes coming from different developers
-
working repositories which allow you to create new changes through modification of files and to create new versions in the repository
If you want to delete a Git repository, you can simply delete the folder which contains the repository.
1.5. Remote repositories
Git allows the user to synchronize the local repository with other (remote) repositories.
Users with sufficient authorization can push changes from their local repository to remote repositories. They can also fetch or pull changes from other repositories to their local Git repository.
1.6. Branching and merging
Git supports branching which means that you can work on different versions of your collection of files in parallel. For example if you want to develop a new feature, you can create a branch and make the changes in this branch without affecting the state of your files in another branch.
Branches in Git are local. A branch created in a local repository, which was cloned from another repository, does not need to have a counterpart in the remote repository. Local branches can be compared with remote tracking branches which proxy the state of branches in another remote repository.
Git supports that changes from different branches can be combined. This allows the developer for example to work independently on a branch called production for bugfixes and another branch calledfeature_123 for implementing a new feature. The developer can use Git commands to combine the changes at a later point in time.
For example the Linux kernel community used to share code corrections (patches) via mailing lists to combine changes coming from different developers. Git is a system which allows developers to automate such a process.
1.7. Working tree
The user works on a collection of files which may originate from a certain point in time of the repository. The user may also create new files or change and delete existing ones. The current collection of files is called the working tree.
A standard Git repository contains the working tree (single checkout of one version of the project) and the full history of the repository. You can work in this working tree by modifying content and committing the changes to the Git repository.
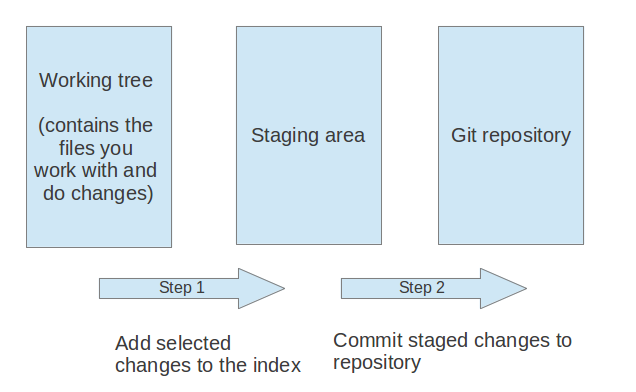
1.8. How to add changes to your Git repository
If you modify your working tree,e.g. by adding a new file or by changing an existing file, you need to perform two steps in Git to persist the changes in the Git repository.
First you need to mark them to be relevant for Git. Marking changes as relevant for the version control is called staging or to add them to the staging area.
Note
The staging area term is currently preferred by the Git community over the old index term. Both terms mean the same thing.
By adding a file to the staging area you store a snapshot of this file in the Git repository. After adding the selected files to the staging area, you store this change in the Git repository.
Storing the changes in the Git repository is called committing. You commit the staged changes to create a new snapshot (commit) of the complete relevant files in the Git repository.
So while adding a file to the staging area stores a snapshot of the file in the repository, a commit stores a snapshot of the complete relevant files.
For example, if you change a file you can stores a snapshot of this file in the staging area with the git add command. This allows you to incrementally modify files, stage them, modify and stage them again until you are satisfied with your changes. Afterwards you commit the staged changes in order to capture a new snapshot of the complete relevant files. For this you use the git commit command.
This process is depicted in the following graphic.
1.9. Committing and commit objects
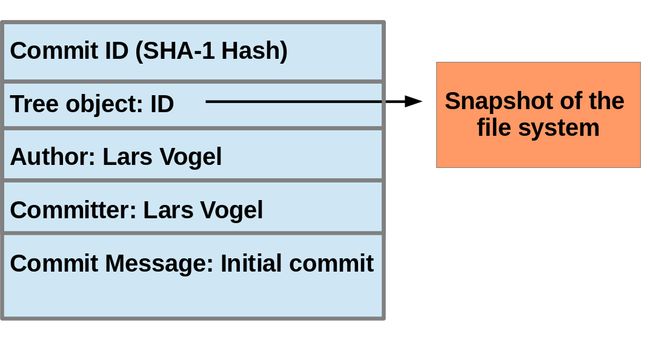
If you commit changes to your Git repository, you create a new commit object in the Git repository. This commit object is addressable via a SHA-1 checksum. This checksum is 40 character long and is a secure hash of the content of the files, the content of the directories, the complete history of up to the new commit, the committer and several other factors.
This means that Git is safe, you cannot manipulate a file in the Git repository without Git noticing thatSHA-1 checksum does not fit anymore to the content.
The commit object points via a tree object to the individual files in this commit. The files are stored in the Git repository as blob objects and might be compressed by Git for better performance.
Such a commit object is depicted in the following picture.
2. Tools
The tooling for Git is originally based on the command line. These days there is a huge variety of available Git tools.
You can use graphical tools, for example EGit for the Eclipse IDE.
3. Terminology
The following table provides a summary of important Git terminology.
Table 1. Git Terminology
| Term | Definition |
|---|---|
| Repository | A repository contains the history, the different versions over time and all different branches and tags. In Git each copy of the repository is a complete repository. If the repository is not a not a bare repository, it allows you to checkout revisions into your working tree. |
| Working tree | The working tree contains the content of a commit which you can checkout from the Git repository. You can modify the content and commit the changes again to the Git repository. |
| Branches | A branch is a named pointer to a commit. Selecting a branch in Git terminology is called to checkout a branch. If you working in a certain branch, the creation of a new commit advances this pointer to the newly created commit. Each commit knows its successor or successors. This way a branch defines it's own line of descents in the overall version graph formed by all commits in the repository. You can create a new branch from an existing one and change the code independently from other branches. One of the branches is the default (typically named master). |
| Tags | A tag points to a commit which uniquely identifies a version of the Git repository. With a tag, you can have a named point to which you can always revert, e.g. the coding of 25.01.2009 in the branch "testing". Branches and tags are named pointers, the difference is that branches move when a new commit is created while tags always point to the same commit. |
| Commit | You commit your changes into a repository. This creates a new commit object in the Git repository which uniquely identifies a new revision of the content of the repository. This revision can be retrieved later, for example if you want to see the source code of an older version. Each commit object contains the author and the committer, thus making it possible to identify the source of the change. The author and committer might be different people. |
| URL | A URL in Git determines the location of the repository. |
| Revision | Represents a version of the source code. Git implements revisions as commit objects (or shortcommits). These are identified by a SHA1 secure hash. SHA1 ids are 160 bits long and are represented in hexadecimal. |
| HEAD | HEAD is a symbolic link most often pointing to the currently checked out branch. Sometimes, e.g. when directly checking out a commit HEAD points to a commit, this is called detached HEAD mode. In that state creation of a commit will not move any branch. The versions before that can be addressed via HEAD~1, HEAD~2 and so on. If you switch branches the HEAD pointer moves to the last commit in the branch. If you checkout a specific commit the HEAD points to this commit. |
| Staging area | The staging area is the place to store changes in the working tree before the commit. It contains the set of changes relevant for the next commit. |
| Index | Index is an alternative term for the staging area |
4. Installation
4.1. Ubuntu, Debian and derived systems
On Ubuntu and similar systems you can install the Git command line tool via the following command:
yum install git
4.2. Fedora, Redhat and derived systems
On Ubuntu and similar systems you can install the Git command line tool via the following command:
yum install git
4.3. Other Linux systems
To install Git on other Linux distributions please check the documentation of your distribution.
4.4. Windows
A windows version of Git can be found on the msysgit Project site. The URL to this webpage is listed below. This website also describes the installation process.
http://code.google.com/p/msysgit/
4.5. Mac OS
The easiest way to install Git on a Mac is via a graphical installer. This installer can be found under the following URL.
http://code.google.com/p/git-osx-installer
As this procedure it not an official Apple one, it may change from time to time. The easiest way to find the current procedure is to Google for the "How to install Git on a Mac" search term.
5. Git Setup
5.1. Global configuration file
Git allows you to store global settings in the .gitconfig file. This file is located in the user home directory. Git stores the committer and author of a change in each commit. This and additional information can be stored in the global settings.
In each Git repository you can also configure the settings for this repository. Global configuration is done if you include the --global flag, otherwise your configuration is specific for the current Git repository.
You can also setup system wide configuration. Git stores theses values is in the /etc/gitconfig file, which contains the configuration for every user and repository on the system. To setup this up, ensure you have sufficient rights, i.e. root rights, in your OS and use the --system option.
The following configures Git so that a certain user and email address is used, enable color coding and tell Git to ignore certain files.
5.2. User Configuration
Configure your user and email for Git via the following command.
# configure the user which will be used by git # Of course you should use your name git config --global user.name "Example Surname" # Same for the email address git config --global user.email "[email protected]"
5.3. Push configuration
The following command configure Git so that the git push command pushes always all branches which are connected to a remote branch (configured as remote tracking branches) to your Git remote repository. This makes is typical easier to ensure that all relevant branches are pushed.
# set default so that all changes are always pushed to the repository git config --global push.default "matching"
5.4. Avoid merge commits for pulling
If you pull in changes from a remote repository, Git by default creates merge commits. This typically undesired and you can avoid this via the following setting.
# set default so that you avoid unnecessary commits git config --global branch.autosetuprebase always
5.5. Color Highlighting
The following commands enables color highlighting for Git in the console.
git config --global color.ui true git config --global color.status auto git config --global color.branch auto
5.6. Setting the default editor
By default Git uses the system default editor. You can configure this via the following setting.
git config --global core.editor vim
5.7. Query existing global Git settings
To query your Git settings, execute the following command:
git config --list
6. Ignore certain files
Git can be configured to ignore certain files and directories. This is configured via the .gitignore file. This file can be in any directory and can contain patterns for files. For example, you can tell Git to ignore thebin directory via the following .gitignore file in the main directory.
You can use certain wildcards in this file. * matches several characters. The . (Dot) parameter matches one character.
# Ignore all bin directories bin # Ignore all files ending with ~ *~ # Ignore the target directory # Matches "target" in any subfolder target/
You can also setup a global .gitignore file valid for all Git repositories via the core.excludesfilesetting.
# Create a ~/.gitignore in your user directory cd ~/ touch .gitignore # Exclude bin and .metadata directories echo "bin" >> .gitignore echo ".metadata" >> .gitignore echo "*~" >> .gitignore echo "target/" >> .gitignore # Configure Git to use this file # as global .gitignore git config --global core.excludesfile ~/.gitignore
The local .gitignore file can be committed into the Git repository and therefore is visible to everyone who clones the repository. The global .gitignore file is only locally visible.
Note
Files which are committed to the Git repository are not automatically removed if you add them to a .gitignore file. See Section 27.7, “Remove files based on .gitignore changes ” to see how to remove these files.
7. Tracking empty directories with .gitkeep
Git ignores empty directories, i.e. it does not put them under version control.
If you want to track such a directory, it is a common practice to put a file called .gitkeep in the directory. The file could be called anything; Git assigns no special significance to this name. As the directory now contains a file, Git includes it into its version control mechanism.
8. Getting started with Git
8.1. Target of this chapter
In this chapter you create a few files, create a local Git repository and commit your files into this repository. The comments (marked with #) before the commands explain the specific actions.
Open a command shell for the operations.
8.2. Create directory
The following commands create an empty directory which you will use as Git repository.
# switch to home cd ~/ # create a directory and switch into it mkdir ~/repo01 cd repo01 # create a new directory mkdir datafiles
8.3. Create Git repository
Every Git repository is stored in the .git folder of the directory in which the Git repository has been created. This directory contains the complete history of the repository. The .git/config file contains the local configuration for the repository.
The following command creates a Git repository in the current directory.
# Initialize the Git repository # for the current directory git init
8.4. Create content
The following commands create some files with some content that will be placed under version control.
# switch to your new repository cd ~/repo01 # create another directory # and create a few files touch test01 touch test02 touch test03 touch datafiles/data.txt # Put a little text into the first file ls >test01
8.5. See the current status of your repository
The git status command shows the working tree status, i.e. which files have changed, which are staged and which are not part of the index. It also shows which files have merge conflicts and gives an indication what the user can do with these changes, e.g. add them to the index or remove them, etc.
Run it via the following command.
git status
8.6. Add files to Git index
Before committing to a Git repository you need to mark which changes should be committed by adding the new and changed files to the Git index. i.e. the staging area. This creates a snapshop of the affected files, if you afterwards change one of the files before committing, you need to add it again to the index to commit the new changes.
# add all files to the index of the # Git repository git add .
Afterwards run the git status command again to see the current status.
8.7. Commit to Git repository
After adding the files to the Git index, you can commit them to the Git repository. This creates a new snapshot of all your files in your Git repository. The <paramater>-m</paramater> allows you to define the commit message, if you leave this parameter out, your default editor is started and you can enter the message in the editor.
# commit your file to the local repository git commit -m "Initial commit"
9. Looking at the result
9.1. Results
The Git operations you performed have created a local Git repository in the .git folder and added all files to this repository via one commit. Run the git log command
# show the Git log for the change git log
You see an output similar to the following.
commit e744d6b22afe12ce75cbd1b671b58d6703ab83f5 Author: Lars Vogel <[email protected]> Date: Mon Feb 25 11:48:50 2013 +0100 Initial commit
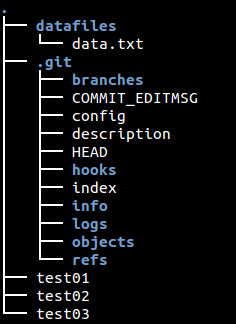
9.2. Directory structure
Your directory contains the Git repository as well as the Git working tree for your files. This directory structure is depicted in the following screenshot.
10. Remove files and adjust the last commit
10.1. Remove files
If you delete a file which is under version control git add . will not pick this file up.
You can use the git rm command to delete the file from your working tree and mark it for the next commit.
# Create a file and commit it touch nonsense2.txt git add . && git commit -m "more nonsense" # remove the file via Git git rm nonsense2.txt # commit the removal git commit -m "Removes nonsense2.txt file"
Alternatively you can use the git commit command with the -a flag or the -A flag in the git addcommand.
For this test, commit a new file and remove it afterwards.
# Create a file and put it under version control touch nonsense.txt git add . && git commit -m "a new file has been created" # Remove the file rm nonsense.txt # Try standard way of committing -> will NOT work git add . && git commit -m "a new file has been created"
Now remove it from the Git repository.
# commit the remove with the -a flag git commit -a -m "File nonsense.txt is now removed" # alternatively you could add deleted files to the staging index via # git add -A . # git commit -m "File nonsense.txt is now removed"
10.2. Remove a file from the staging area
You can use the git reset [filename] command to remove a file from the index, which you added with git add [filename] .
# create a file and add to index touch unwantedstaged.txt git add unwantedstaged.txt # remove it from the index git reset unwantedstaged.txt # to cleanup, delete it rm unwantedstaged.txt
10.3. Correction of the last commit with git amend
The git --amend command makes it possible to change the last commit including the commit message.
Assume the last commit message was incorrect as it contained a typo. The following command corrects this via the --amend parameter.
Assume you had a typo in your commit message.
# assume you have something to commit git commit -m "message with a tpyo here"
git commit --amend -m "More changes - now correct"
You should use the git --amend command only for commits which have not been shared with others. The git --amend command creates a new commit ID and people may have based their work already on the existing commit. In this case they would need to migrate their work based on the new commit.
11. Remote repositories
11.1. What are remote repositories?
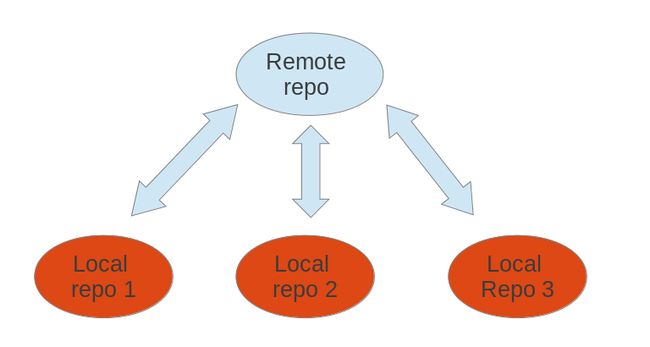
Remote repositories are repositories that are hosted on the Internet or network. Such remote repositories can be use to synchronize the changes of several Git repositories. A local Git repository can be connected to multiple remote repositories and you can synchronize your local repository with them via Git operations.
I is possible that users connect their individual repositories directly, but a typically Git workflow involve one or more remote repositories which are used to synchronize the individual repository.
11.2. Bare repositories
A remote repository on a server typically does not require a working tree. A Git repository without working tree is called a bare repository. You can create such a repository with the --bare option. The command to create a new empty bare remote repository is displayed below.
# create a bare repository git init --bare
By convention a bare repository should end with the .git extension.
11.3. Setting up a remote (bare) Git repository
In this section you create a bare remote Git repository. In order to simplify the following examples, the Git repository is hosted locally in the filesystem and not in the Internet.
Execute the following commands to create a bare repository based on your existing Git repository.
# switch to the first repository cd ~/repo01 # create a new bare repository by cloning the first one git clone --bare . ../remote-repository.git # check the content, it is identical to the .git directory in repo01 ls ~/remote-repository.git
11.4. Cloning and the remote repository called "origin"
You can always connect to a remote repository if you know its URL and if you have access to it. If you clone (copy) a repository from another repository, a connection to this original repository is automatically created under the name origin. You can use this name to retrieve data from the remote repository.
11.5. Adding more remote repositories
You can always synchronize with another Git repository via its full URL.
You can also add a shortname for a URL to a repository via the git remote add command. origin is a special name which is created automatically by Git, if you clone a Git repository. The origin remote indicates the repository from which you original cloned. If you created a Git repository from scratch, this name is still available.
Use the following commands to connect to your remote repository.
# Add ../remote-repository.git with the name origin git remote add origin ../remote-repository.git
You can synchronize your local Git repository with remote repositories. These commands are covered in detail in later sections but the following command shows already how you can send changes to your remote repository.
# do some changes echo "I added a remote repo" > test02 # commit git commit -a -m "This is a test for the new remote origin" # to push use the command: # git push [target] # default for [target] is origin git push origin
11.6. Show the existing remote repositories
To see the existing definitions of the remote repositories, use the following command.
# show the details of the remote repo called origin git remote show origin
To see the details of the remote repository, e.g. the URL from which it was cloned you can use the following command.
# show the existing defined remote repositories git remote # show details about the remote repos git remote -v
12. Cloning remote repositories and push and pull
12.1. Clone your repository
Clone a repository and checkout a working tree in a new directory via the following commands.
# Switch to home cd ~ # Make new directory mkdir repo02 # Switch to new directory cd ~/repo02 # Clone git clone ../remote-repository.git .
12.2. Push changes to another repository
The git push command allows you to send data to other repositories. By default it sends data from your current branch to the master branch of the remote repository called origin.
Make some changes in your local repository and push them from your first repository to the remote repository via the following commands.
# Make some changes in the first repository cd ~/repo01 # Make some changes in the file echo "Hello, hello. Turn your radio on" > test01 echo "Bye, bye. Turn your radio off" > test02 # Commit the changes, -a will commit changes for modified files # but will not add automatically new files git commit -a -m "Some changes" # Push the changes git push ../remote-repository.git
By default you can only push to bare repositories (repositories without working tree). Also you can only push a change to a remote repository which results in a fast-forward merge. See Section 21.1, “Merging” to learn about fast-forward merges.
12.3. Pull changes
The git pull command allows you to get the latest changes from another repository. In your second repository, pull in the recent changes in the remote repository, make some changes, push them to your remote repository.
# switch to second directory cd ~/repo02 # pull in the latest changes of your remote repository git pull # make changes echo "A change" > test01 # commit the changes git commit -a -m "A change" # push changes to remote repository # origin is automatically created as we cloned original from this repository git push origin
You can pull in the changes in your first repository.
# switch to the first repository and pull in the changes cd ~/repo01 git pull ../remote-repository.git/ # check the changes git status
13. Online remote repositories
13.1. Cloning remote repositories
Git support remote operations with other Git repositories. For communication with these repositories Git supports several transport types; the native protocol for Git is also called git.
The following will clone an existing repository via the Git protocol.
# switch to a new directory mkdir ~/online cd ~/online # clone online repository git clone [email protected]:vogella/gitbook.git
Alternatively you could clone the same repository via the http protocol.
# The following will clone via HTTP git clone http://[email protected]/vogella/gitbook.git
13.2. Add more remote repositories
If you clone a remote repository, the original repository will automatically be called origin.
You can push changes to this origin repository via git push as Git uses origin as default. Of course, pushing to a remote repository requires write access to this repository.
You can add more remote repositories to your repository via the git remote add name [URL_to_Git_repo] command. For example if you cloned the repository from above via the Git protocol, you could add the http protocol via:
// Add the https protocol git remote add githttp https://[email protected]/vogella/gitbook.git
13.3. Remote operations via http and a proxy
It is possible to use the HTTP protocol to clone Git repositories. This is especially helpful, if your firewall blocks everything except http.
Git also provides support for http access via a proxy server. The following Git command could, for example, clone a repository via http and a proxy. You can either set the proxy variable in general for all applications or set it only for Git.
This example uses environment variables.
# Linux export http_proxy=http://proxy:8080 # On Windows # Set http_proxy=http://proxy:8080 git clone http://dev.eclipse.org/git/org.eclipse.jface/org.eclipse.jface.snippets.git # Push back to the origin using http git push origin
This example uses the Git config settings.
// Set proxy for git globally git config --global http.proxy http://proxy:8080 // To check the proxy settings git config --get http.proxy // Just in case you need to you can also revoke the proxy settings git config --global --unset http.proxy
14. Whats are tags?
14.1. Whats are tags?
Git has the option to tag a commit in the repository history so that you find them more easily at a later point in time. Most commonly, this is used to tag a certain version which has been released.
14.2. Lightweight and annotated tags
Git supported two different types of tags, lightweight and annotated tags.
A lightweight tag is a pointer to a commit, without any additional information about the tag. An annotated tag contain additional information about the tag, e.g. the name and email of the person who created the tag, a tagging message and the date of the tagging. Annotated tags can also be signed and verified withGNU Privacy Guard (GPG).
15. Tagging in Git
15.1. List existing tags
You can list the available tags via the following command:
git tag
15.2. Creating annotated tags
You can create a new annotated tag via the git tag -a command. An annotated tag is also created with you use the -m . Via the -m parameter, you specify the description of this tag. The following command tags the current active HEAD.
# create tag git tag version1.6 -m 'version 1.6' # See the tag git show version1.6
You can also create tags for a certain commit id.
git tag version1.5 -m 'version 1.5' [commit id]
15.3. Signed tags
You can use the option -s to create a signed tag. These tags are signed with GNU Privacy Guard (GPG)and can also be verified with GPG. For details on this please see the man page of git for tags which can be accessed via the man git-tag command.
15.4. Creating lightweight tags
To create a lightweight tag don't use the -m, -a or -s option.
# delete tag git tag -d version1.7 # push the deleted tag to origin git push origin :refs/tags/version1.7
15.5. Checkout tags
If you want to use the code associated with the tag, use:
git checkout <tag_name>
Warning
If you checkout a tag, you are in the detached head model and commits in this mode are harder to find after you checkout a branch again. . See Section 29.1, “Detached HEAD ”for details.
15.6. Push tags
By default the git push command does not transfer tags to remote repositories. You explicitly have to push the tag with the following command.
git push origin [tagname]
15.7. Delete tags
You can delete tags with the -d parameter. This deletes the tag from your local repository. By default Git does not push deleted tags to a remote repository, you have to trigger that explicitly.
# create lightweight tag git tag version1.7 # See the tag git show version1.7
16. What are branches?
Git allows you to create branches, i.e. copies of the files from a certain commit. These branches can be changed independently from each other. The default branch is called master.
Git allows you to create branches very fast and cheaply in terms of resource consumption. Developers are encouraged to use branches frequently.
If you decide to work on a branch, you checkout this branch. This means that Git moves the HEADpointer to the latest commit of the branch and populates the working tree with the content of this commit.
Untracked files remain unchanged and are available in the new branch. This allows you to create a branch for unstaged and uncommited changes at any point in time.
17. Working with branches
17.1. List available branches
The git branch command lists all locally available branches. The currently active branch is marked with*.
# lists available branches git branch
If you want to see all branches (including remote tracking branches), use the -a for the git branchcommand.
# lists all branches including the remote branches git branch -a
17.2. Create new branch
You can create a new branch via the git branch [newname] command. This command allows optionally to specify the starting point (commit id, tag, remote or local branch). If not specified the currently checked out commit will be used to create the branch.
# Syntax: git branch <name> <hash> # <hash> in the above is optional git branch testing # Switch to your new branch git checkout testing # Some changes echo "Cool new feature in this branch" > test01 git commit -a -m "new feature" # Switch to the master branch git checkout master # Check that the content of test01 is the old one cat test01
To create a branch and to switch to it at the same time you can use the git checkout command with the -b parameter.
# Create branch and switch to it git checkout -b bugreport12 # Creates a new branch based on the master branch # without the last commit git checkout -b mybranch master~1
17.3. Rename a branch
Renaming a branch can be done with the following command.
# rename branch git branch -m [old_name] [new_name]
17.4. Delete a branch
To delete a branch which is not needed anymore, you can use the following command.
# delete branch testing git branch -d testing # check if branch has been deleted git branch
17.5. Push a branch to remote repository
By default Git will only push matching branches to a remote repository. That means that you have to manually push a new branch once. Afterwards "git push" will also push the new branch.
# Push testing branch to remote repository git push origin testing # Switch to the testing branch git checkout testing # Some changes echo "News for you" > test01 git commit -a -m "new feature in branch" # Push all including branch git push
This way you can decide which branches should be visible to other repositories and which should be local branches.
18. Differences between branches
To see the difference between two branches you can use the following command.
# shows the differences in your # branch based on the common # ancestor for both branches git diff master...your_branch
If you want to see the different in a branch since you diverted from another branch you can use the ... shortcut. For example if you compare a branch called your_branch with the master branch the following command does only show the changes in your_branch since it diverted from the master branch.
# shows the differences between # current head of master and your_branch git diff master your_branch
19. Remote and local tracking branches
19.1. Remote tracking branches
Your local Git repository contains references to the state of the branches on the remote repositories to which it is connected. These local references are called remote tracking branches.
You can see your remote tracking branches with the following command.
# list all remote branches git branch -r
To see all branches or only the local branches you can use the following commands.
# list all local branches git branch # list local and remote braches git branch -a
The -v option lists also more information about the branch.
19.2. Delete a remote branch in your local repository
It is also safe to delete a remote branch in your local Git repository. You can use the following command for that.
# delete remote branch from origin git branch -d -r origin/<remote branch>
The next time you run the git fetch command the remote branch is recreated.
19.3. Delete a branch in a remote repository
To delete the branch in a remote repository use the following command.
# delete branch in a remote repository git push [remote] --delete [branch]
19.4. Local tracking branches
Local tracking branches are local branches which are directly connected to a remote tracking branch. These local tracking branches allow you to use the git pull and git push command directly without specifying the branch and repository.
# list all local branches git branch # list local and remote braches git branch -a
If you clone a Git repository, your local master branch is created as a tracking branches for origin/masterby Git.
You can create new tracking branches by specifying the remote branch during the creation of a branch. The following example demonstrates that.
# setup a tracking branch called newbrach # which tracks origin/newbranch git checkout -b newbranch origin/newbranch
To update remote branches without changing local branches you use the git fetch command which is covered in Section 20, “Updating your remote branches with git fetch ”.
19.5. See the branch information for a remote
To see the tracking branches for a remote you can use the following command.
# show all remote and tracking branches for origin git remote show origin
An example output of this might look like the following.
* remote origin Fetch URL: ssh://test@git.eclipse.org/gitroot/e4/org.eclipse.e4.tools.git Push URL: ssh://test@git.eclipse.org/gitroot/e4/org.eclipse.e4.tools.git HEAD branch: master Remote branches: integration tracked interm_rc2 tracked master tracked smcela/HandlerAddonUpdates tracked Local branches configured for 'git pull': integration rebases onto remote integration master rebases onto remote master testing rebases onto remote master Local refs configured for 'git push': integration pushes to integration (up to date) master pushes to master (up to date)
20. Updating your remote branches with git fetch
20.1. Fetch
You can update your remote branches with the git fetch command.
The git fetch command updates your remote branches, i.e. it updates the local copy of branches stored in a remote repository.
The fetch command only updates the remote branches and none of the local branches and it does not change the working tree of the Git repository. Therefore you can run the git fetch command at any point in time.
After reviewing the changes in the remote tracking branch you can merge or rebase these changes onto your local branches. Alternatively you can also use the git cherry-pick "sha" command to take over only selected commits.
20.2. Fetch from all remote repositories
Use the following command to update all remote tracking branches from your remote repositories.
# run fetch for every remote repository git remote update # the same but remove all stale branches which # are not in the remote anymore git remote update --prune
20.3. Compare remote tracking branch with local branch
The following code shows a few options how you can compare your branches.
# show the long entries between the last local commit and the # remote branch git log HEAD..origin # show the diff for each patch git log -p HEAD..origin # show a single diff git diff HEAD...origin
The above commands shows the changes introduced in HEAD compared to origin. If you want to see the changes in origin compared to HEAD you can switch the arguments.
20.4. Rebase your local branch based on the remote tracking branch
You can apply the changes of the remote branches on your current local branch for example with the following command.
# assume you want to rebase master based on the latest fetch # therefore check it out git checkout master # update your remote tracking branch git fetch # rebase your master onto origin/master git rebase origin/master
20.5. Fetch compared with pull
The git pull command performs a git fetch and git merge (or git rebase based on your Git settings). The git fetch does not perform any operations on your local branches. I can always run the fetch command and review the incoming changes.
21. Merging branches
21.1. Merging
Git allows to combine the changes of two branches. This process is called merging. The git mergecommand performs a merge.
21.2. Fast-forward merge
If the commits which are merged are direct successors of the HEAD pointer of the currentbranch, Git simplifies things by performing a so-called fast forward merge. This fast forward merge simply moves theHEAD pointer of the current branch to the last commit which is being merged.
This process is depicted in the following graphics. Assume you want to merge the changes of branch into your master branch. Each commits points to its successor.
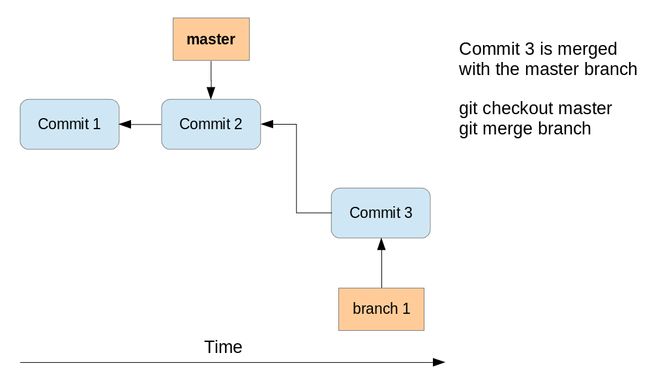
After the fast forward merge the HEAD pointer of master simple points to the existing commit.
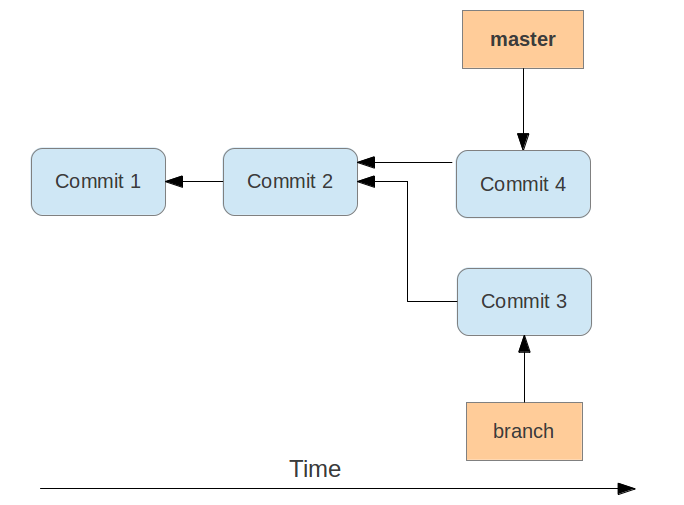
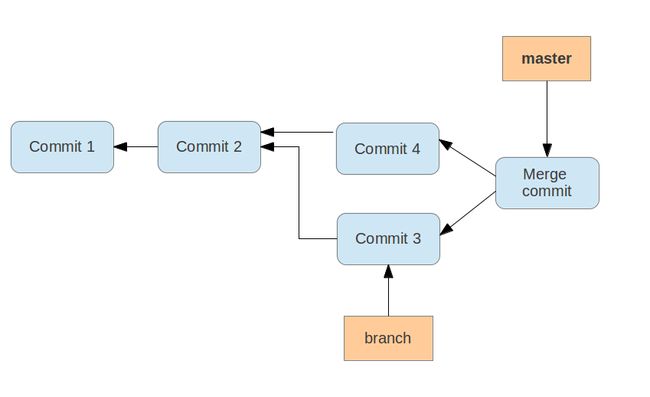
21.3. Merge commit
If different work needs to be merged, Git performs a so-called three-way-merge between the latest snapshot of two branches, based on the most recent common ancestor of both.
As a result, you have a new commit in the branch onto which you merged the changes of the other branch. This commit is called merge commit and is special as it points to both its successors.
21.4. Commands to merge two branches
You can merge changes from one branch to the current active one via the following command.
# syntax: git merge <branch-name> # merges into your current selected branch git merge testing
22. Solving merge conflicts
22.1. What is a merge conflict
A merge conflicts occurs, if two people have modified the same content and Git cannot automatically determine how both changes should be applied.
If a merge conflict occurs Git will mark the conflict in the file and the programmer has to resolve the conflict manually. After resolving it, he can add the file to the staging index and commit the change.
22.2. Example process for solving a merge conflict
In the following example you first create a merge conflict and afterwards you resolve the conflict and apply the change to the Git repository.
The following code creates a merge conflict.
# Switch to the first directory cd ~/repo01 # Make changes echo "Change in the first repository" > mergeconflict.txt # Stage and commit git add . && git commit -a -m "Will create merge conflict 1" # Switch to the second directory cd ~/repo02 # Make changes touch mergeconflict.txt echo "Change in the second repository" > mergeconflict.txt # Stage and commit git add . && git commit -a -m "Will create merge conflict 2" # Push to the master repository git push # Now try to push from the first directory # Switch to the first directory cd ~/repo01 # Try to push --> you will get an error message git push # Get the changes via a pull # this creates the merge conflict in your # local repository git pull origin master
Git marks the conflict in the affected file. This file looks like the following.
<<<<<<< HEAD Change in the first repository ======= Change in the second repository >>>>>>> b29196692f5ebfd10d8a9ca1911c8b08127c85f8
The above is the part from your repository and the below one from the remote repository. You can edit the file manually and afterwards commit the changes.
Alternatively, you could use the git mergetool command. git mergetool starts a configurable merge tool that displays the changes in a split screen. git mergetool is not always available but it is safe to edit the file with merge conflicts by hand.
# Either edit the file manually or use git mergetool # You will be prompted to select which merge tool you want to use # For example on Ubuntu you can use the tool "meld" # After merging the changes manually, commit them git commit -m "merged changes"
Instead of using the -m option in the above example you can also use the git commit command without this option. In this case the command opens your default editor with a default commit messages about the merged conflicts. It is good practice to use this message.
23. Rebase
23.1. Rebasing branches
You can use Git to rebase one branches on another one. As described the merge command combines the changes of two branches. If you rebase a branch called A onto another, the git command takes the changes introduced by the commits of branch A and applies them based on the HEAD of the other branch. This way the changes in the other branch are also available in branch A.
The processes is displayed in the following picture. We want to rebase the branch onto master.
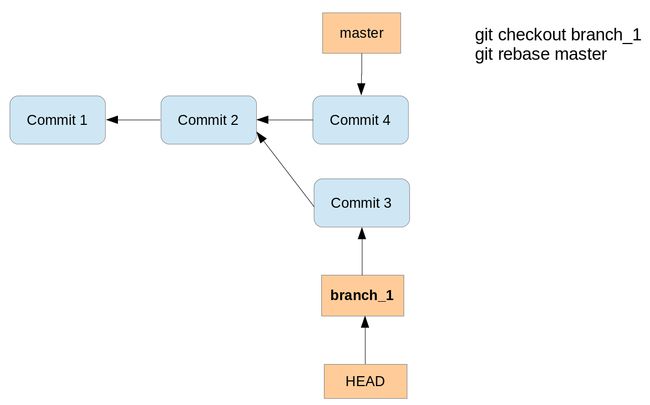
Running the rebase command creates a new commit with the changes of the branch on top of the master branch.
Performing a rebase from one branch to another branch does not create a merge commit.
The final result for the source code is the same as with merge but the commit history is cleaner; the history appears to be linear.
# create new branch git checkout -b rebasetest # To some changes touch rebase1.txt git add . && git commit -m "work in branch" # do changes in master git checkout master # make some changes and commit into testing echo "This will be rebased to rebasetest" > rebasefile.txt git add rebasefile.txt git commit -m "New file created" # rebase the rebasetest onto master git checkout rebasetest git rebase master # now you can fast forward your branch onto master git checkout master git merge rebasetest
Rebase is also useful to apply the changes of the master branch to feature branches to ensure that the feature branch still works with the latest developments from the master branch.
23.2. Rebasing commits in the same branch
The rebase command allows you to combine several commits into one commit. This is useful as it allows the user to rewrite some of the commit history (cleaning it up) before pushing your changes to a remote repository.
The following will create several commits which should be combined at a later point in time.
# Create a new file touch rebase.txt # Add it to git git add . && git commit -m "rebase.txt added to index" # Do some silly changes and commit echo "content" >> rebase.txt git add . && git commit -m "added content" echo " more content" >> rebase.txt git add . && git commit -m "this is just a test" echo " more content" >> rebase.txt git add . && git commit -m "ups" echo " more content" >> rebase.txt git add . && git commit -m "yes" echo " more content" >> rebase.txt git add . && git commit -m "added more content" echo " more content" >> rebase.txt git add . && git commit -m "creation of important configuration file" # Check the git log message git log
We will combine the last seven commits. You can do this interactively via the following command.
git rebase -i HEAD~7
This will open your editor of choice and let you configure the rebase operation by defining which commits to pick,a squash or fixup.
Pick includes the selected commit. Squash combines the commit messages while fixup will disregard the commit message. The following shows an example of the selection, we pick the last commit, squash 5 commits and fix the sixth commit.
p 7c6472e added more content f 4f73e68 added content f bc9ec3f this is just a test f 701cbb5 ups f 910f38b yes f 31d447d added more content s e08d5c3 creation of important configuration file # Rebase 06e7464..e08d5c3 onto 06e7464 # # Commands: # p, pick = use commit # r, reword = use commit, but edit the commit message # e, edit = use commit, but stop for amending # s, squash = use commit, but meld into previous commit # f, fixup = like "squash", but discard this commit's log message # x, exec = run command (the rest of the line) using shell # # These lines can be re-ordered; they are executed from top to bottom. # # If you remove a line here THAT COMMIT WILL BE LOST. # However, if you remove everything, the rebase will be aborted.
23.3. Best practice for rebase
You should always check your local branch history before pushing changes to another Git repository or review system.
Git allows you to do local commits. This feature is frequently used to have commits to which you can go back, if something should go wrong during a feature development. If you do so you, before pushing, should look at your local branch history and validate, whether or not these commits are relevant for others.
If they all belong to the implementation of the same feature you, most likely, want to summarize them in one single commit before pushing.
The interactive rebase is basically rewriting the history. It is safe to do this as long as the commits have not been pushed to another repository. This means commits should only be rewritten as long as they have not been pushed.
If you rewrite and push a commit that is already present in other Git repositories, it will look as if you implemented something that somebody had already implemented.
For example assume that a user has a local feature branch and wants to push it onto a branch on the remote repository. However, the branch has evolved and therefore pushing is not possible. Now the best practice is to first fetch the latest state of the branch from the remote repository. Afterwards it is better to rebase the local feature branch onto the remote tracking branch than to create an unnecessary merge commit. This rebasing of a local feature branch is also useful to incorporate the latest changes from remote into the local development, even if the user does not want to push right away.
24. Selecting individual commits with git cherry-pick
24.1. Applying a single commit
The git cherry-pick command allows you to select the patch which was introduced with an individual commit and apply this patch on another branch. The patch is captured as a new commit on the other branch.
This way you can select individual changes from one branch and transfer them to another branch.
24.2. Using cherry-pick
In the following example you create a new branch and commit two changes.
# create new branch git checkout -b picktest # create some data and commit touch pickfile.txt git add pickfile.txt git commit -m "adds new file" # create second commit echo "changes to file" > pickfile.txt git commit -a -m "changes in file"
You can check the commit history for example with the git log --oneline command.
# see change commit history
git log --oneline
# results in the following output
2fc2e55 changes in file
ebb46b7 adds new file
[MORE COMMITS]
330b6a3 initial commit
The following command selects the first commit based on the commit id and applies its changes to the master branch. This creates a new commit on the master branch.
git checkout master git cherry-pick ebb46b7
The cherry-pick command can be used to change the order of commits. git cherry-pick also accepts ranges for example in the following command.
git checkout master
# pick both commits
git cherry-pick picktest~..picktest~1
25. Stashing committed changes with git stash
25.1. Git stash definition
Git provides the stash command which allows you to save the current uncommitted changes and checkout the last committed revision.
This allows you to pull in the latest changes or to develop an urgent fix. Afterwards you can restore the stashed changes, which will reapply the changes to the current version of the source code.
In general using the stash command should be the exception in using Git. Typically you would create new branches for new features and switch between branches. You can also commit frequently in your local Git repository and use interactive rebase to combine these commits later before pushing them to another Git repository.
25.2.1. Git stash example
The following commands will save a stash and reapply them after some changes.
# Create a stash with uncommited changes git stash # TODO do changes to the source, e.g. by pulling # new changes from a remove repo # Afterwards reapply the stashed changes # and delete the stash from the list of stashes git stash pop
It is also possible to keep a list of stashes.
# Create a stash with uncommited changes git stash save # See the list of available stashes git stash list # Result might be something like: stash@{0}: WIP on master: 273e4a0 Resize issue in Dialog stash@{1}: WIP on master: 273e4a0 Silly typo in Classname # You can use the ID to apply a stash git stash apply stash@{0} # Also you can remove a stashed change git stash drop stash@{0} # Or delete all stashes git stash clear # Or apply the latest stash and delete it afterwards git stash pop # Afterwards reapply the stashed changes # and delete the stash from the list of stashes git stash pop
25.2.2. Create branch from stash
You can also create a branch for your stash. You might want to do this because the branch from which you stashed has changed the same files and your want to have better control cover your changes or because you want to select individual changes from your stack.
# create a new branch from your stack and # switch to it git stash branch newbranchforstash
26. Retrieving individual files
26.1. View file in different revision without checkout
The git show command allows to see and retrieve files from branches, commits and tags. It allows to see the status of these files in the selected branch, commit or tag without checking them out into your working tree.
The following commands demonstrate that. You can also make a copy of the file.
# [reference] can be a branch, tag, HEAD or commit ID # [filename] is the filename including path git show [reference]:[filename] # To make a copy to copiedfile.txt git show [reference]:[filename] > copiedfile.txt
26.2. See which commit deleted a file
You can use the -- option in git log to see the commit history for file, even if you have deleted the file.
# See the commit which delete a file or directory # -1 to see only the last commit # use 2 to see the last 2 commits etc git log -1 -- [file path]
27. Revert Changes
27.1. Revert changes in your working tree with git clean
If you create files in your working tree which you do not want to commit, you can discard them with thegit clean command.
# Create a new file with content echo "this is trash to be deleted" > test04 # Make a dry-run to see what would happen # -n is the same as --dry-run git clean -n # delete, -f is required if # variable clean.requireForce is not set to false # git clean -f # use -d flag to delete new directories # use -x to delete hidden files, e.g. ".example" git clean -fdx
27.2. Checkout existing versions from the index
If you delete or change a file but you have not yet added it to the index or committed the change, you can check out the file again.
# Delete a file rm test01 # Revert the deletion git checkout test01 # Change a file echo "override" > test01 # Restore the file git checkout test01
27.3. Checkout commits versions
You can check out older revisions of your source code via the commit ID. The commit ID is shown if you enter the git log command. It is displayed behind the commit word.
# Switch to home cd ~/repo01 # Get the log git log # Checkout the older revision via git checkout commit_id
Warning
If you checkout a commit, you are in the detached head mode and commits in this mode are harder to find after you checkout another branch. Before committing it is good practice to create a new branch to leave the detached head mode. . See Section 29.1, “Detached HEAD ” for details.
27.4. Remove staged changes for new files
If you add a file to the index but do not want to commit the file, you can remove it from the index via thegit reset file command.
# create a file and # accidently add it to the index touch incorrect.txt git add . # remove it from the index git reset incorrect.txt # to clean up, delete the file # not neccessary, maybe you want to add it later to the index rm incorrect.txt
27.5. Remove staged changes for previously committed files
If you have added the changes of a file to the staging index, you can also revert the changes in the index and checkout the file from the index.
# some nonsense change echo "change which should be removed later" > test01 # add the file to the staging index git add test01 # restore the file in the staging index git reset HEAD test01 # get the version from the staging index # into the working tree git checkout test01
If you deleted a directory and you have not yet committed the changes, you can restore the directory via the following command:
git checkout HEAD -- your_dir_to_restore
27.6. Reverting a commit
You can revert commits via the git revert command. git revert will revert the changes of a commit and record a new commit which documents that the other commit was reverted.
# Revert a commit git revert commit_id
27.7. Remove files based on .gitignore changes
Sometimes you change your .gitignore file. Git will stop tracking the new entries from this moment. The last version is still in the Git repository.
If you want to remove the related files from your Git repository you need to do this explicitely via the following command. use.
# Remove directory .metadata from git repo git rm -r --cached .metadata # Remove file test.txt from repo git rm --cached test.txt
This does not remove the file from the repository history. If the file should also be removed from the history, have a look at git filter-branch which allows you to rewrite the commit history.
28. Resetting commits
28.1. git reset to move the HEAD pointer
The git reset command also allow you to set the current HEAD to a specified state, e.g. commit. This way you can continue your work from another commit.
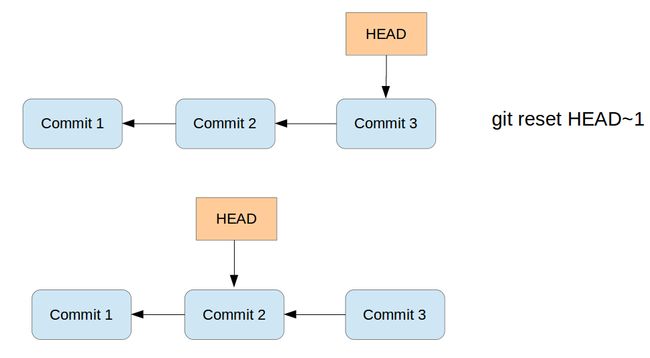
Via parameter you can define how the index and the working tree is updated.
Table 2. git reset
| Reset | Working tree | Index |
|---|---|---|
| soft | No | No |
| mixed (default) | No | Yes |
| hard | Yes | Yes |
The git reset command does not remove files which are not staged or committed.
28.2. Finding commits which you have reset
The commits which were above the commit to which you resetted, can be reached via the git reflogcommand. See Section 29, “Recovering lost commits”.
28.3. git reset and deleting all unstaged files
The git reset --hard command does not delete new files in your working tree. If you want to delete them too, you need to use the git clean -f command too.
# removes staged and working tree changes # of commited files git reset --hard # the above does not remove untracked files therefore # the next command is needed # removes new files which are still untracked git clean -f -d
29. Recovering lost commits
29.1. Detached HEAD
If you checkout a commit or a tag you are in the so-called detached HEAD mode . If you commit changes in this mode, you have no branch which points to this commit. After you checkout a branch you cannot see the commit you did in detached head mode in the git log command.
To find such commits you can use the git reflog command.
29.2. git reflog
Reflog is a mechanism to record the movements of the HEAD pointer. HEAD is a pointer to the currently selected commit object.
The Git reflog command gives a history of the complete changes of the HEAD pointer.
git reflog # Output # ... snip ... 1f1a73a HEAD@{2}: commit: More chaanges - typo in the commit message 45ca204 HEAD@{3}: commit: These are new changes cf616d4 HEAD@{4}: commit (initial): Initial commit
The git reflog command also list commits which you have removed.
29.3. Example
The following example shows how you can use git reflog to revert to a commit which has been removed.
# Assume the ID for the second commit is # 45ca2045be3aeda054c5418ec3c4ce63b5f269f7 # Resets the head for your tree to the second commit git reset --hard 45ca2045be3aeda054c5418ec3c4ce63b5f269f7 # See the log git log # Output shows the history until the 45ca2045be commit # See all the history including the deletion git reflog # <Output> cf616d4 HEAD@{1}: reset: moving to 45ca2045be3aeda054c5418ec3c4ce63b5f269f7 # ...snip.... 1f1a73a HEAD@{2}: commit: More chaanges - typo in the commit message 45ca204 HEAD@{3}: commit: These are new changes cf616d4 HEAD@{4}: commit (initial): Initial commit git reset --hard 1f1a73a
30. Define alias
30.1. What is an alias
An alias in Git allows you to setup your own Git command. For example, you can define an alias which is a short form of your own favorite commands or you can combine several commands with an alias.
Unfortunately, defining an alias is at the time of writing not completely supported in msysGit for Windows. You can do single aliases, e.g. ca for ca = commit -a) but you can not do ones beginning with !.
30.2. Example alias
For example, the following defines the git add-commit command which combines git add . -Aand git commit -m. After defining this command, you can use it via the git add-commit -m "message" command.
git config --global alias.add-commit '!git add . -A && git commit'
31. Error search with git bisect
31.1. What is git bisect
The git bisect command allows you to run a binary search through the commit history to identify the commit which introduced an issue. You define a range or commits which bisect runs and a script which Git runs to identify if a commit is good or bad. This script must return 0 if the condition it checks is fulfilled and non-zero if the condition is not fulfilled.
31.2. git bisect example
Create a new Git repository, create the file1.txt and commit it to the repository. Do a few more changes, remove the file and again do a few more changes.
We use a simple shell script which checks the existence of a file. Ensure that this file is executable.
#!/bin/bash FILE=$1 if [ -f $FILE ]; then exit 0; else exit 1; fi
Now we use the git bisect command to find the bad commit. First you use the start to define the known bad commit and the known good commit.
# define the check range between # HEAD and HEAD minus 5 commits git bisect start HEAD HEAD~5
Afterwards run the bisect command using the shell script.
# assumes that the check script # is a directory above the current git bisect run ../check.sh test1.txt
32. Submodules - Repos inside other Git repos
32.1. Why use submodules
Git allows you to include other Git repositories into a Git repository. This is useful in case you want to include a certain library in another repository or in case you want to aggregate certain Git repositories.
Git calls these included Git repositories submodules.
Git allows you to commit, pull and push to these repositories independently.
You add a submodule to a Git repository via the git submodule add command.
# Add a submodule to your Git repo git submodule add [URL to Git repo]
32.2. Cloning submodules
To clone a Git repository which contains submodules you need to run in addition to the clone command the git submodule init and git submodule update command. The init command creates the local configuration file for the submodules if it does not yet exist and the update command clones the submodules.
33. Rewriting commit history with git filter-branch
33.1. Using git filter-branch
The git filter-branch command allows you to rewrite the Git commit history for selected branches, applying custom filters on each revision. This creates different hashes for all modified commits.
The commands allows to filter for several values, e.g. the author, the message, etc. For details please see the following link.
http://www.kernel.org/pub/software/scm/git/docs/git-filter-branch.html
Warning
Using filter-branch is dangerous as it changes the Git repository. It changes the commit id and if someone else is working on a cloned version of the repository as his references to the commit id are gone.
33.2. filter-branch example
The following show an example how to change the commit name and his email address via the git filter-branch command.
git filter-branch -f --env-filter \ "GIT_AUTHOR_NAME='Test Vogel'; GIT_AUTHOR_EMAIL='[email protected]'; \ GIT_COMMITTER_NAME='Lars Vogel'; \ GIT_COMMITTER_EMAIL='[email protected]';" HEAD
34. Create and apply patches
34.1. What is a patch?
A patch is a text file that contains changes to the source code. A patch created with the git format-patch command includes meta-information about the commit (committer, date, commit message, etc) and contains also the diff of binary data.
This file can be sent to someone else for example via email and this person can use this file to apply the changes to his/her local repository. The metadata is preserved.
Alternative you could create a diff file with the git diff command but this diff file does not contain the metadata information.
34.2. Create and apply patches
The following example creates a branch, changes the files and commits these changes into the branch.
# Create a new branch git branch mybranch # Use this new branch git checkout mybranch # Make some changes touch test05 # Change some content in an existing file echo "New content for test01" >test01 # Commit this to the branch git add . git commit -a -m "First commit in the branch"
The next example creates a patch for these changes.
# Create a patch --> git format-patch master git format-patch origin/master # This created the file: # patch 0001-First-commit-in-the-branch.patch
To apply this patch to your master branch, switch to it and use the git apply command.
# Switch to the master git checkout master # Apply the patch git apply 0001-First-commit-in-the-branch.patch
Afterwards you can commit the changes introduced by the patches and delete the patch file.
# Patch is applied to master # Change can be commited git add . git commit -a -m "Applied patch" # Delete the patch file rm 0001-First-commit-in-the-branch.patch
35. Git commit hooks
35.1. What are Git commit hooks
Git provides commit hooks, e.g. programs which can be executed at a pre-defined point during the work with the repository. For example you can ensure that the commit message has a certain format or trigger an action after a push to the server.
These programs are scripts and can be written in any language, e.g. as shell scripts or in Perl, Python etc. Git calls these scripts based on a naming convention.
35.2. Client and server side commit hooks
Git provides hooks for the client and for the server side. On the server side you can use the pre-receiveand post-receive script to check the input or to trigger actions after the commit.
If you create a new Git repository, Git create example scripts into the .git/hooks. The example scripts end with .sample. To activate them make them executable and remove the .sample from the filename.
The commits hooks are documented in the Git man pages, use man githooks to see the documentation.
36. Line endings on different platforms
Linux and Mac uses different line endings than Windows. Windows uses a carriage-return and a linefeed character (CRLF), while Linux and Mac only uses a linefeed character (LF)).
To avoid commits because of line ending differences in your Git repository you should configure all clients to write the same line ending to the Git repository.
On Windows systems you can tell Git to convert during a checkout to CRLF and during a commit convert back the LF format. Use the following setting for this.
git config --global core.autocrlf true
On Linux and Mac you can tell Git to convert CRLF during a checkout to LF with the following setting.
git config --global core.autocrlf input
37. Own Git server
37.1. Installing a Git server
As described before, you do not need a server. You can just use a file system or a public Git provider, such as Github or Bitbucket. Sometimes, however, it is convenient to have your own server, and installing it under Ubuntu is relatively easy.
First make sure you have installed ssh.
apt-get install ssh
If you have not yet installed Git on your server, you need to do this too.
sudo apt-get install git-core
Create a new user for git.
sudo adduser git
Now log on with your Git user and create a bare repository.
# Login to server # to test use localhost ssh git@IP_ADDRESS_OF_SERVER # Create repository git init --bare example.git
Now you can push to the remote repository.
mkdir gitexample cd gitexample git init touch README git add README git commit -m 'first commit' git remote add origin git@IP_ADDRESS_OF_SERVER:example.git git push origin master
37.2. Give write access to a Git repository
The typical setup based on the created "git" user from above is that the public SSH key of each user is added to the ~/.ssh/authorized_keys file of the "git" user. Afterwards everyone can access the system using the "git" user.
Alternatively you could use LDAP authentication or other special configurations.
37.3. Security setup for the git user
The Git installation provides a specialized shell, which can be assigned to the user. Typically this shell is located under in /usr/bin/git-shell and can be assigned to the user via the /etc/passwd configuration file to the Git user. If you assign this shell to the Git user, this user can also perform Git command which add safety to your Git setup.
38. Viewing changes in the working tree with git status
38.1. Viewing the status of the working tree with git status
The git status command shows the working tree status, i.e. which files have changed, which are staged and which are not part of the index. It also shows which files have merge conflicts and gives an indication what the user can do with these changes, e.g. add them to the index or remove them, etc.
38.2. Example
The following command show the current status of your repository.
# make some changes in the file echo "This is a new change" > test01 echo "and this is another new change" > test02 # see the current status of your repository # (which files are changed / new / deleted) git status
39. Viewing deltas (differences)
39.1. See unstaged changes since the last commit
The git diff command allows the user to see the changes made. In order to test this, make some changes to a file and check what the git diff command shows to you. Afterwards commit the changes to the repository.
# make some changes to the file echo "This is a change" > test01 echo "and this is another change" > test02 # check the changes via the diff command git diff # optional you can also specify a path to filter the displayed changes # path can be a file or directory # git diff [path]
39.2. See differences between index and last commit
To see which changes you have staged, i.e. you are going to commit with the next commit, use the following command.
# make some changes to the file git diff -cached
39.3. See the difference between two commits
To see the differences introduced between two commits you use the git diff command specifying the commits. For example the following command shows the differences introduced in the last commit.
git diff HEAD~1 HEAD
40. Analyzing changes in the repository
40.1. Repository history with Git log
The git log commands shows the history of your repository in the current branch, i.e. the list of commits.
# show the history of commits in the current branch git log # show the history of commits in one line # with a shortened version of the commit id git log --oneline --abbrev-commit # show the history as graph including branches git log --graph --pretty --oneline --abbrev-commit
40.2. See the files changed by a commit
To see the files which have been changed in a commit use the git diff-tree command. The name-only tells the command to show only the names of the files.
git diff-tree --name-only -r <commit_id>
To see the changes in a commit use the following command.
git show <commit_id>
40.3. View the change history of a file
To see changes in a file you can use the -p option in the git log command.
# git log filename shows the commits for this file git log [file path] # Use -p to see the diffs of each commit git log -p filename # --follow shows the entire history # including renames git log --follow -p file
40.4. Find out which commit deleted a file or directory
To see which commit deleted a file you can use the following command.
# See the commit which delete a file or directory # -1 to see only the last commit # use 2 to see the last 2 commits etc git log -1 -- [file path]
Note
The double hyphens (--) in Git separate flags from non-flags (usually filenames).
40.5. Analyzing line changes with git blame
The git blame command allows you to see which commit and author modified a file on a line by line basis.
# git blame shows the author and commit per # line of a file git blame [filename] # the -L option allows to limit the selection # for example by line number # only show line 1 and 2 in git blame git blame -L 1-2 [filename]
41. Git Hosting Provider
Instead of setting up your own server, you can also use a hosting service. The most popular Git hosting sites are GitHub and Bitbucket. Both offer free hosting with certain limitations.
41.1. ssh key
Most hosting provider allow to use the http protocol with manual user authentication or to use an ssh key for automatic authentication.
An ssh key has a public and private part. The public part is uploaded to the hosting provider. If you interact with the hosting provider via ssh, the public key will be validated based on the private key which is stored locally.
The ssh key is usually generated in the .ssh directory. Ensure that you backup existing keys in this directory before running the following commands.
To create an ssh key under Ubuntu switch to the command line and issue the following commands.
# Switch to your .ssh directory cd ~/.ssh # If the directory # does not exist, create it via: # mkdir .ssh # Manually backup all existing content of this dir!!! # Afterwards generate the ssh key ssh-keygen -t rsa -C "[email protected]" # Press enter to select the default directory # You will be prompted for an optional passphrase # A passphrase protects your private key # but you have to enter it manually during ssh operations
The result will be two files, id_rsa which is your private key and id_rsa.pub which is your public key.
You find more details for the generation of a SSH key on the following webpage.
# Link to ssh key creation on Github https://help.github.com/articles/generating-ssh-keys
41.2. GitHub
GitHub can be found under the following URL.
https://github.com/
GitHub allow free hosting for public repositories. If you want to have private repositories which are only visible for people you select, you have to pay a monthly fee to GitHub.
If you create an account at GitHub you can create a repository. After creating a repository at GitHub you will get a description of all the commands you need to execute to upload your project to GitHub. Follow the instructions.
These instructions will be similar to the following commands.
Global setup: Set up git git config --global user.name "Your Name" git config --global user.email [email protected] Next steps: mkdir gitbook cd gitbook git init touch README git add README git commit -m 'first commit' git remote add origin [email protected]:vogella/gitbook.git git push -u origin master Existing Git Repo? cd existing_git_repo git remote add origin [email protected]:vogella/gitbook.git git push -u origin master
41.3. Bitbucket
Bitbucket can be found under the following URL.
https://bitbucket.org/
Bitbucket allows unlimited public and private repositories. The number of participants for a free private repository is currently limited to 5 collaborators, i.e. if you have more than 5 developers which need access to a private repository you have to pay money to Bitbucket.
42. Typical Git workflow using separate repositories
The following description highlights typical Git workflows.
42.1. Providing a patch
Git emphasizes the creation of branches for feature development or to create bug fixes. The following description lists a typical Git workflow for fixing a bug in your source code (files) and providing a patch for it. This patch contains the changes and can be used by another person to apply the changes to his local Git repository.
This description assumes that the person which creates the changes cannot push changes directly to the remote repository. For example you may solve an issue in the source code of an Open Source project and want that the maintainer of the Open Source project integrates this into his project.
-
Clone the repository, in case you have not done that.
-
Create a new branch for the bug fix
-
Modify the files (source code)
-
Commit changes to your branch
-
Create patch
-
Send patch to another person or attach it to a bug report, so that is can be applied to the other Git repository
You may also want to commit several times during 3.) and 4.) and rebase your commits afterwards.
Even if you have commit rights, creating a local branch for every feature or bug fix is a good practice. Once your development is finished you merge your changes to your master and push the changes from master to your remote Git repository.
42.2. Working with two repositories
Sometimes you want to add another remote repository to your local Git repo and pull and push from and to both repositories. The following example describes how to add another remote repository and to pull and fetch from both repositories.
You can add another remote repository called remote_name via the following command.
# add remote git remote add <remote_name> <url_of_gitrepo> # see all repos git remote -v
For merging the changes in remote_name create a new branch called newbranch.
# create a new branch which will be used # to merge changes in repository 1 git checkout -b <newbranch>
Afterwards you can pull from your new repository called remote_name and push to your original repository.
# reminder: your active branch is newbranch # pull remote_name and merge git pull <remote_name> # or fetch and merge in two steps git fetch <remote_name> git merge <remote_name>/<newbranch> # afterwards push to first repository git push -u origin master
42.3. Using pull requests
Another very common Git workflow is the usage of pull requests. In this workflow a developer clones a repository and once he thinks he has something useful for another clone or the origin repository he sends the owner a pull request asking to merge his changes.
This workflow is also actively promoted by the Github.com hosting platform.
43. Typical Git workflows with shared repositories
43.1. Working with a shared remote
Git emphasizes the creation of branches for feature development or to create bug fixes. The following description contains a typical Git workflow for developing a new feature or bug fix and pushing it to the remote repository which is shared with other developers. After cloning the repository the developer would:
-
creates a new branch for the development
-
changes content in the working tree and add and commit his changes
-
if required he switches to other branches to do other work
-
once the development in the branch is complete he rebases (or merges) the commit history onto the relevant remote tracking branch to allow a fast-forward merge for this development
-
he pushes his changes to the remote repository, this results in a fast-forward merge in the remote repository
During this development he may fetch and merge or rebase the changes from the remote repository at any point in time. The developer may use the pull command instead of the fetch command.
44. Get the Kindle edition
This tutorial is available for your Kindle.
45. Questions and Discussion
Before posting questions, please see the vogella FAQ. If you have questions or find an error in this article please use the www.vogella.com Google Group. I have created a short list how to create good questions which might also help you.
46. Links and Literature
Git homepage
EGit - Teamprovider for Eclipse
Video with Linus Torvalds on Git
Git on Windows
Ref: http://www.vogella.com/articles/Git/article.html
学习git最好的方法是根据example走一边! 以前转过progit, 不过貌似链接失效了。