Android Audio System
之一:AudioTrack如何与AudioFlinger交换音频数据
引子
Android Framework的音频子系统中,每一个音频流对应着一个AudioTrack类的一个实例,每个AudioTrack会在创建时注册到AudioFlinger中,由AudioFlinger把所有的AudioTrack进行混合(Mixer),然后输送到AudioHardware中进行播放,目前Android的Froyo版本设定了同时最多可以创建32个音频流,也就是说,Mixer最多会同时处理32个AudioTrack的数据流。
如何使用AudioTrack
AudioTrack的主要代码位于 frameworks/base/media/libmedia/audiotrack.cpp中。现在先通过一个例子来了解一下如何使用AudioTrack,ToneGenerator是android中产生电话拨号音和其他音调波形的一个实现,我们就以它为例子:
ToneGenerator的初始化函数:
- bool ToneGenerator::initAudioTrack() {
- // Open audio track in mono, PCM 16bit, default sampling rate, default buffer size
- mpAudioTrack = new AudioTrack();
- mpAudioTrack->set(mStreamType,
- 0,
- AudioSystem::PCM_16_BIT,
- AudioSystem::CHANNEL_OUT_MONO,
- 0,
- 0,
- audioCallback,
- this,
- 0,
- 0,
- mThreadCanCallJava);
- if (mpAudioTrack->initCheck() != NO_ERROR) {
- LOGE("AudioTrack->initCheck failed");
- goto initAudioTrack_exit;
- }
- mpAudioTrack->setVolume(mVolume, mVolume);
- mState = TONE_INIT;
- ......
- }
可见,创建步骤很简单,先new一个AudioTrack的实例,然后调用set成员函数完成参数的设置并注册到AudioFlinger中,然后可以调用其他诸如设置音量等函数进一步设置音频参数。其中,一个重要的参数是audioCallback,audioCallback是一个回调函数,负责响应AudioTrack的通知,例如填充数据、循环播放、播放位置触发等等。回调函数的写法通常像这样:
- void ToneGenerator::audioCallback(int event, void* user, void *info) {
- if (event != AudioTrack::EVENT_MORE_DATA) return;
- AudioTrack::Buffer *buffer = static_cast<AudioTrack::Buffer *>(info);
- ToneGenerator *lpToneGen = static_cast<ToneGenerator *>(user);
- short *lpOut = buffer->i16;
- unsigned int lNumSmp = buffer->size/sizeof(short);
- const ToneDescriptor *lpToneDesc = lpToneGen->mpToneDesc;
- if (buffer->size == 0) return;
- // Clear output buffer: WaveGenerator accumulates into lpOut buffer
- memset(lpOut, 0, buffer->size);
- ......
- // 以下是产生音调数据的代码,略....
- }
该函数首先判断事件的类型是否是EVENT_MORE_DATA,如果是,则后续的代码会填充相应的音频数据后返回,当然你可以处理其他事件,以下是可用的事件类型:
- enum event_type {
- EVENT_MORE_DATA = 0, // Request to write more data to PCM buffer.
- EVENT_UNDERRUN = 1, // PCM buffer underrun occured.
- EVENT_LOOP_END = 2, // Sample loop end was reached; playback restarted from loop start if loop count was not 0.
- EVENT_MARKER = 3, // Playback head is at the specified marker position (See setMarkerPosition()).
- EVENT_NEW_POS = 4, // Playback head is at a new position (See setPositionUpdatePeriod()).
- EVENT_BUFFER_END = 5 // Playback head is at the end of the buffer.
- };
开始播放:
- mpAudioTrack->start();
停止播放:
- mpAudioTrack->stop();
只要简单地调用成员函数start()和stop()即可。
AudioTrack和AudioFlinger的通信机制
通常,AudioTrack和AudioFlinger并不在同一个进程中,它们通过android中的binder机制建立联系。
AudioFlinger是android中的一个service,在android启动时就已经被加载。下面这张图展示了他们两个的关系:
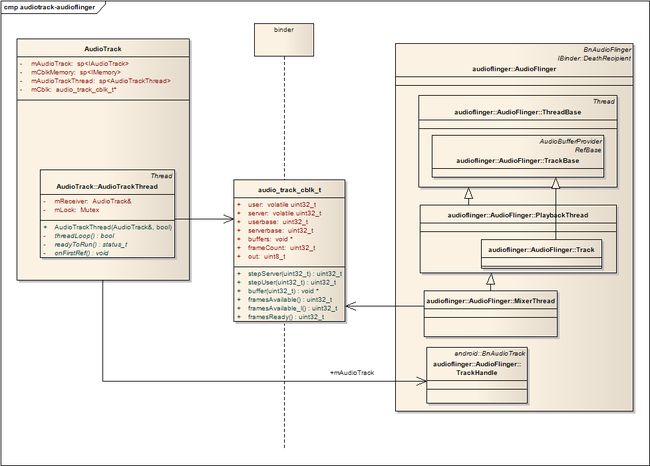
图一 AudioTrack和AudioFlinger的关系
我们可以这样理解这张图的含义:
- audio_track_cblk_t实现了一个环形FIFO;
- AudioTrack是FIFO的数据生产者;
- AudioFlinger是FIFO的数据消费者。
建立联系的过程
下面的序列图展示了AudioTrack和AudioFlinger建立联系的过程:

图二 AudioTrack和AudioFlinger建立联系
解释一下过程:
- Framework或者Java层通过JNI,new AudioTrack();
- 根据StreamType等参数,通过一系列的调用getOutput();
- 如有必要,AudioFlinger根据StreamType打开不同硬件设备;
- AudioFlinger为该输出设备创建混音线程: MixerThread(),并把该线程的id作为getOutput()的返回值返回给AudioTrack;
- AudioTrack通过binder机制调用AudioFlinger的createTrack();
- AudioFlinger注册该AudioTrack到MixerThread中;
- AudioFlinger创建一个用于控制的TrackHandle,并以IAudioTrack这一接口作为createTrack()的返回值;
- AudioTrack通过IAudioTrack接口,得到在AudioFlinger中创建的FIFO(audio_track_cblk_t);
- AudioTrack创建自己的监控线程:AudioTrackThread;
自此,AudioTrack建立了和AudioFlinger的全部联系工作,接下来,AudioTrack可以:
- 通过IAudioTrack接口控制该音轨的状态,例如start,stop,pause等等;
- 通过对FIFO的写入,实现连续的音频播放;
- 监控线程监控事件的发生,并通过audioCallback回调函数与用户程序进行交互;
FIFO的管理
audio_track_cblk_t
audio_track_cblk_t这个结构是FIFO实现的关键,该结构是在createTrack的时候,由AudioFlinger申请相应的内存,然后通过IMemory接口返回AudioTrack的,这样AudioTrack和AudioFlinger管理着同一个audio_track_cblk_t,通过它实现了环形FIFO,AudioTrack向FIFO中写入音频数据,AudioFlinger从FIFO中读取音频数据,经Mixer后送给AudioHardware进行播放。
audio_track_cblk_t的主要数据成员:
user -- AudioTrack当前的写位置的偏移
userBase -- AudioTrack写偏移的基准位置,结合user的值方可确定真实的FIFO地址指针
server -- AudioFlinger当前的读位置的偏移
serverBase -- AudioFlinger读偏移的基准位置,结合server的值方可确定真实的FIFO地址指针
frameCount -- FIFO的大小,以音频数据的帧为单位,16bit的音频每帧的大小是2字节
buffers -- 指向FIFO的起始地址
out -- 音频流的方向,对于AudioTrack,out=1,对于AudioRecord,out=0
audio_track_cblk_t的主要成员函数:
framesAvailable_l()和framesAvailable()用于获取FIFO中可写的空闲空间的大小,只是加锁和不加锁的区别。
- uint32_t audio_track_cblk_t::framesAvailable_l()
- {
- uint32_t u = this->user;
- uint32_t s = this->server;
- if (out) {
- uint32_t limit = (s < loopStart) ? s : loopStart;
- return limit + frameCount - u;
- } else {
- return frameCount + u - s;
- }
- }
framesReady()用于获取FIFO中可读取的空间大小。
- uint32_t audio_track_cblk_t::framesReady()
- {
- uint32_t u = this->user;
- uint32_t s = this->server;
- if (out) {
- if (u < loopEnd) {
- return u - s;
- } else {
- Mutex::Autolock _l(lock);
- if (loopCount >= 0) {
- return (loopEnd - loopStart)*loopCount + u - s;
- } else {
- return UINT_MAX;
- }
- }
- } else {
- return s - u;
- }
- }
我们看看下面的示意图:
_____________________________________________
^ ^ ^ ^
buffer_start server(s) user(u) buffer_end
很明显,frameReady = u - s,frameAvalible = frameCount - frameReady = frameCount - u + s
可能有人会问,应为这是一个环形的buffer,一旦user越过了buffer_end以后,应该会发生下面的情况:
_____________________________________________
^ ^ ^ ^
buffer_start user(u) server(s) buffer_end
这时候u在s的前面,用上面的公式计算就会错误,但是android使用了一些技巧,保证了上述公式一直成立。我们先看完下面三个函数的代码再分析:
- uint32_t audio_track_cblk_t::stepUser(uint32_t frameCount)
- {
- uint32_t u = this->user;
- u += frameCount;
- ......
- if (u >= userBase + this->frameCount) {
- userBase += this->frameCount;
- }
- this->user = u;
- ......
- return u;
- }
- bool audio_track_cblk_t::stepServer(uint32_t frameCount)
- {
- // the code below simulates lock-with-timeout
- // we MUST do this to protect the AudioFlinger server
- // as this lock is shared with the client.
- status_t err;
- err = lock.tryLock();
- if (err == -EBUSY) { // just wait a bit
- usleep(1000);
- err = lock.tryLock();
- }
- if (err != NO_ERROR) {
- // probably, the client just died.
- return false;
- }
- uint32_t s = this->server;
- s += frameCount;
- // 省略部分代码
- // ......
- if (s >= serverBase + this->frameCount) {
- serverBase += this->frameCount;
- }
- this->server = s;
- cv.signal();
- lock.unlock();
- return true;
- }
- void* audio_track_cblk_t::buffer(uint32_t offset) const
- {
- return (int8_t *)this->buffers + (offset - userBase) * this->frameSize;
- }
stepUser()和stepServer的作用是调整当前偏移的位置,可以看到,他们仅仅是把成员变量user或server的值加上需要移动的数量,user和server的值并不考虑FIFO的边界问题,随着数据的不停写入和读出,user和server的值不断增加,只要处理得当,user总是出现在server的后面,因此frameAvalible()和frameReady()中的算法才会一直成立。根据这种算法,user和server的值都可能大于FIFO的大小:framCount,那么,如何确定真正的写指针的位置呢?这里需要用到userBase这一成员变量,在stepUser()中,每当user的值越过(userBase+frameCount),userBase就会增加frameCount,这样,映射到FIFO中的偏移总是可以通过(user-userBase)获得。因此,获得当前FIFO的写地址指针可以通过成员函数buffer()返回:
p = mClbk->buffer(mclbk->user);
在AudioTrack中,封装了两个函数:obtainBuffer()和releaseBuffer()操作FIFO,obtainBuffer()获得当前可写的数量和写指针的位置,releaseBuffer()则在写入数据后被调用,它其实就是简单地调用stepUser()来调整偏移的位置。
IMemory接口
在createTrack的过程中,AudioFlinger会根据传入的frameCount参数,申请一块内存,AudioTrack可以通过IAudioTrack接口的getCblk()函数获得指向该内存块的IMemory接口,然后AudioTrack通过该IMemory接口的pointer()函数获得指向该内存块的指针,这块内存的开始部分就是audio_track_cblk_t结构,紧接着是大小为frameSize的FIFO内存。
IMemory->pointer() ---->|_______________________________________________________
|__audio_track_cblk_t__|_______buffer of FIFO(size==frameCount)____|
看看AudioTrack的createTrack()的代码就明白了:
- sp<IAudioTrack> track = audioFlinger->createTrack(getpid(),
- streamType,
- sampleRate,
- format,
- channelCount,
- frameCount,
- ((uint16_t)flags) << 16,
- sharedBuffer,
- output,
- &status);
- // 得到IMemory接口
- sp<IMemory> cblk = track->getCblk();
- mAudioTrack.clear();
- mAudioTrack = track;
- mCblkMemory.clear();
- mCblkMemory = cblk;
- // 得到audio_track_cblk_t结构
- mCblk = static_cast<audio_track_cblk_t*>(cblk->pointer());
- // 该FIFO用于输出
- mCblk->out = 1;
- // Update buffer size in case it has been limited by AudioFlinger during track creation
- mFrameCount = mCblk->frameCount;
- if (sharedBuffer == 0) {
- // 给FIFO的起始地址赋值
- mCblk->buffers = (char*)mCblk + sizeof(audio_track_cblk_t);
- } else {
- ..........
- }
之二:AudioFlinger
引言
AudioFlinger是Android音频系统的两大服务之一,另一个服务是AudioPolicyService,这两大服务都在系统启动时有MediaSever加载,加载的代码位于:frameworks/base/media/mediaserver/main_mediaserver.cpp。
本文主要介绍AudioFlinger,AudioFlinger向下访问AudioHardware,实现输出音频数据,控制音频参数。同时,AudioFlinger向上通过IAudioFinger接口提供服务。所以,AudioFlinger在Android的音频系统框架中起着承上启下的作用,地位相当重要。AudioFlinger的相关代码主要在:frameworks/base/libs/audioflinger,也有部分相关的代码在frameworks/base/media/libmedia里。
AudioFlinger的类结构
下面的图示描述了AudioFlinger类的内部结构和关系:
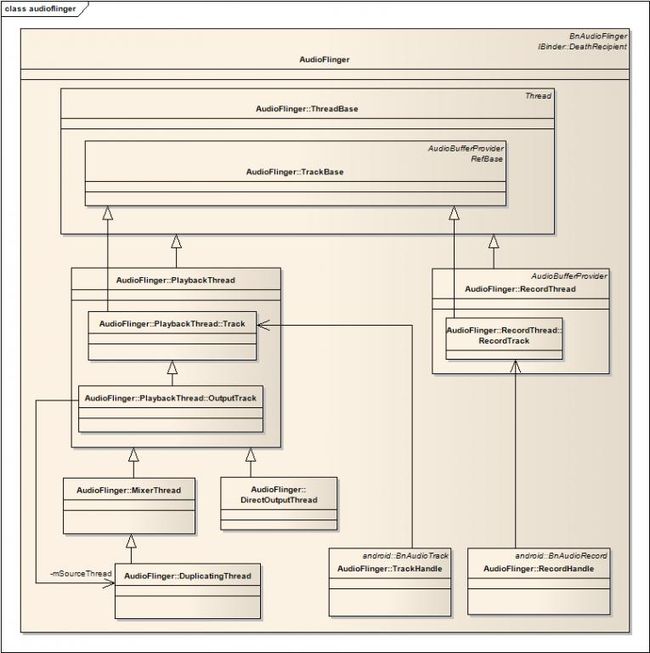
图一 AudioFlinger的类结构
不知道各位是否和我一样,第一次看到AudioFlinger类的定义的时候都很郁闷--这个类实在是庞大和臃肿,可是当你理清他的关系以后,你会觉得相当合理。下面我们一一展开讨论。
-
IAudioFlinger接口
这是AudioFlinger向外提供服务的接口,例如openOutput,openInput,createTrack,openRecord等等,应用程序或者其他service通过ServiceManager可以获得该接口。该接口通过继承BnAudioFlinger得到。
-
ThreadBase
在AudioFlinger中,Android为每一个放音/录音设备均创建一个处理线程,负责音频数据的I/O和合成,ThreadBase是这些线程的基类,所有的播放和录音线程都派生自ThreadBase
-
TrackBase
应用程序每创建一个音轨(AudioTrack/AudioRecord),在AudioFlinger中都会创建一个对应的Track实例,TrackBase就是这些Track的基类,他的派生类有:
-
- PlaybackTread::Track // 用于普通播放,对应于应用层的AudioTrack
- PlaybackThread::OutputTrack // 用于多重设备输出,当蓝牙播放开启时使用
- RecordThread::RecordTrack // 用于录音,对应于应用层的AudioRecord
-
播放
默认的播放线程是MixerThread,它由AudioPolicyManager创建,在AudioPolicyManager的构造函数中,有以下代码:
- mHardwareOutput = mpClientInterface->openOutput(&outputDesc->mDevice,
- &outputDesc->mSamplingRate,
- &outputDesc->mFormat,
- &outputDesc->mChannels,
- &outputDesc->mLatency,
- outputDesc->mFlags);
最终会进入AudioFlinger的openOut函数:
- ......
- thread = new MixerThread(this, output, ++mNextThreadId);
- ......
- mPlaybackThreads.add(mNextThreadId, thread);
- ......
- return mNextThreadId;
可以看到,创建好的线程会把该线程和它的Id保存在AudioFlinger的成员变量mPlaybackThreads中,mPlaybackThreads是一个Vector,AudioFlinger创建的线程都会保存在里面,最后,openOutput返回该线程的Id,该Id也就是所谓的audio_io_handle_t,AudioFlinger的调用者这能看到这个audio_io_handle_t,当需要访问时传入该audio_io_handle_t,AudioFlinger会通过mPlaybackThreads,得到该线程的指针。
要播放声音,应用程序首先要通过IAudioFlinger接口,调用createTrack(),createTrack会调用PlaybackThread类的createTrack_l函数:
- track = thread->createTrack_l(client, streamType, sampleRate, format,
- channelCount, frameCount, sharedBuffer, &lStatus);
再跟入createTrack_l函数中,可以看到创建了PlaybackThread::Track类,然后加入播放线程的track列表mTracks中。
- track = thread->createTrack_l(client, streamType, sampleRate, format,
- channelCount, frameCount, sharedBuffer, &lStatus);
- ......
- mTracks.add(track);
在createTrack的最后,创建了TrackHandle类并返回,TrackHandle继承了IAudioTrack接口,以后,createTrack的调用者可以通过IAudioTrack接口与AudioFlinger中对应的Track实例交互。
- trackHandle = new TrackHandle(track);
- ......
- return trackHandle;
最后,在系统运行时,AudioFlinger中的线程和Track的结构大致如下图所示:它会拥有多个工作线程,每个线程拥有多个Track。
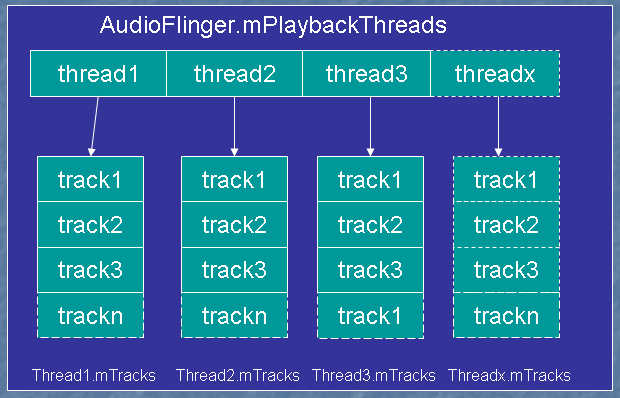
图二 AudioFlinger的线程结构
播放线程实际上是MixerThread的一个实例,MixerThread的threadLoop()中,会把该线程中的各个Track进行混合,必要时还要进行ReSample(重采样)的动作,转换为统一的采样率(44.1K),然后通过音频系统的AudioHardware层输出音频数据。
-
录音
录音的流程和放音差不多,只不过数据流动的方向相反,录音线程变成RecordThread,Track变成了RecordTrack,openRecord返回RecordHandle,详细的暂且不表。
-
DuplicatingThread
AudioFlinger中有一个特殊的线程类:DuplicatingThread,从图一可以知道,它是MixerThread的子类。当系统中有两个设备要同时输出时,DuplicatingThread将被创建,通过IAudioFlinger的openDuplicateOutput方法创建DuplicatingThread。
- int AudioFlinger::openDuplicateOutput(int output1, int output2)
- {
- Mutex::Autolock _l(mLock);
- MixerThread *thread1 = checkMixerThread_l(output1);
- MixerThread *thread2 = checkMixerThread_l(output2);
- ......
- DuplicatingThread *thread = new DuplicatingThread(this, thread1, ++mNextThreadId);
- thread->addOutputTrack(thread2);
- mPlaybackThreads.add(mNextThreadId, thread);
- return mNextThreadId;
- }
创建 DuplicatingThread时,传入2个需要同时输出的目标线程Id,openDuplicateOutput先从mPlaybackThreads中根据Id取得相应输出线程的实例,然后为每个线程创建一个虚拟的AudioTrack----OutputTrack,然后把这个虚拟的AudioTrack加入到目标线程的mTracks列表中,DuplicatingThread在它的threadLoop()中,把Mixer好的数据同时写入两个虚拟的OutputTrack中,因为这两个OutputTrack已经加入到目标线程的mTracks列表,所以,两个目标线程会同时输出DuplicatingThread的声音。
实际上,创建DuplicatingThread的工作是有AudioPolicyService中的AudioPolicyManager里发起的。主要是当蓝牙耳机和本机输出都开启时,AudioPolicyManager会做出以下动作:
- 首先打开(或创建)蓝牙输出线程A2dpOutput
- 以HardwareOutput和A2dpOutput作为参数,调用openDuplicateOutput,创建DuplicatingThread
- 把属于STRATEGY_MEDIA类型的Track移到A2dpOutput中
- 把属于STRATEGY_DTMF类型的Track移到A2dpOutput中
- 把属于STRATEGY_SONIFICATION类型的Track移到DuplicateOutput中
结果是,音乐和DTMF只会在蓝牙耳机中输出,而按键音和铃声等提示音会同时在本机和蓝牙耳机中输出。

图三 本机播放时的Thread和Track
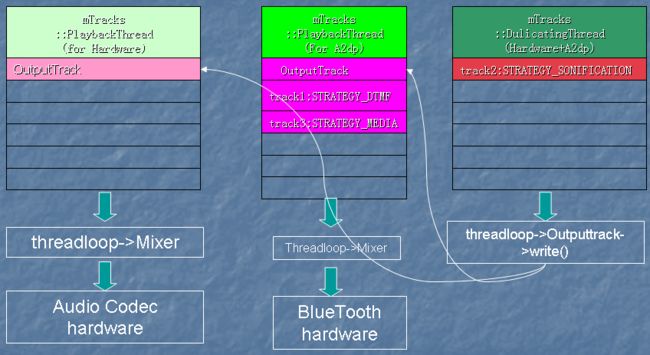
图四 蓝牙播放时的Thread和Track
之三: AudioPolicyService 和 AudioPolicyManager
引言
AudioPolicyService是Android音频系统的两大服务之一,另一个服务是AudioFlinger,这两大服务都在系统启动时有MediaSever加载,加载的代码位于:frameworks/base/media/mediaserver/main_mediaserver.cpp。AudioFlinger主要负责管理音频数据处理以及和硬件抽象层相关的工作。本文主要介绍AudioPolicyService。
AudioPolicyService
AudioPolicyService主要完成以下任务:
- JAVA应用层通过JNI,经由IAudioPolicyService接口,访问AudioPolicyService提供的服务
- 输入输出设备的连接状态
- 系统的音频策略(strategy)的切换
- 音量/音频参数的设置
AudioPolicyService的构成
下面这张图描述了AudioPolicyService的静态结构:

进一步说明:
1. AudioPolicyService继承了IAudioPolicyService接口,这样AudioPolicyService就可以基于Android的Binder机制,向外部提供服务;
2. AudioPolicyService同时也继承了AudioPolicyClientInterface类,他有一个AudioPolicyInterface类的成员指针mpPolicyManager,实际上就是指向了AudioPolicyManager;
3. AudioPolicyManager类继承了AudioPolicyInterface类以便向AudioPolicyService提供服务,反过来同时还有一个AudioPolicyClientInterface指针,该指针在构造函数中被初始化,指向了AudioPolicyService,实际上,AudioPolicyService是通过成员指针mpPolicyManager访问AudioPolicyManager,而AudioPolicyManager则通过AudioPolicyClientInterface(mpClientInterface)访问AudioPolicyService;
4. AudioPolicyService有一个内部线程类AudioCommandThread,顾名思义,所有的命令(音量控制,输入、输出的切换等)最终都会在该线程中排队执行;
AudioPolicyManager
AudioPolicyService的很大一部分管理工作都是在AudioPolicyManager中完成的。包括音量管理,音频策略(strategy)管理,输入输出设备管理。
输入输出设备管理
音频系统为音频设备定义了一个枚举:AudioSystem::audio_devices,例如:DEVICE_OUT_SPEAKER,DEVICE_OUT_WIRED_HEADPHONE,DEVICE_OUT_BLUETOOTH_A2DP,DEVICE_IN_BUILTIN_MIC,DEVICE_IN_VOICE_CALL等等,每一个枚举值其实对应一个32bit整数的某一个位,所以这些值是可以进行位或操作的,例如我希望同时打开扬声器和耳机,那么可以这样:
- newDevice = DEVICE_OUT_SPEAKER | DEVICE_OUT_WIRED_HEADPHONE;
- setOutputDevice(mHardwareOutput, newDevice);
AudioPolicyManager中有两个成员变量:mAvailableOutputDevices和mAvailableInputDevices,他们记录了当前可用的输入和输出设备,当系统检测到耳机或者蓝牙已连接好时,会调用AudioPolicyManager的成员函数:
- status_t AudioPolicyManager::setDeviceConnectionState(AudioSystem::audio_devices device,
- AudioSystem::device_connection_state state,
- const char *device_address)
该函数根据传入的device值和state(DEVICE_STATE_AVAILABLE/DEVICE_STATE_UNAVAILABLE)设置mAvailableOutputDevices或者mAvailableInputDevices,然后选择相应的输入或者输出设备。
其他一些相关的函数:
- setForceUse() 设置某种场合强制使用某一设备,例如setForceUse(FOR_MEDIA, FORCE_SPEAKER)会在播放音乐时打开扬声器
- startOutput()/stopOutput()
- startInput()/stopInput()
音量管理
AudioPolicyManager提供了一下几个与音量相关的函数:
- initStreamVolume(AudioSystem::stream_type stream, int indexMin, int indexMax)
- setStreamVolumeIndex(AudioSystem::stream_type stream, int index)
- getStreamVolumeIndex(AudioSystem::stream_type stream)
AudioService.java中定义了每一种音频流的最大音量级别:
- /** @hide Maximum volume index values for audio streams */
- private int[] MAX_STREAM_VOLUME = new int[] {
- 5, // STREAM_VOICE_CALL
- 7, // STREAM_SYSTEM
- 7, // STREAM_RING
- 15, // STREAM_MUSIC
- 7, // STREAM_ALARM
- 7, // STREAM_NOTIFICATION
- 15, // STREAM_BLUETOOTH_SCO
- 7, // STREAM_SYSTEM_ENFORCED
- 15, // STREAM_DTMF
- 15 // STREAM_TTS
- };
由此可见,电话铃声可以有7个级别的音量,而音乐则可以有15个音量级别,java的代码通过jni,最后调用AudioPolicyManager的initStreamVolume(),把这个数组的内容传入AudioPolicyManager中,这样AudioPolicyManager也就记住了每一个音频流的音量级别。应用程序可以调用setStreamVolumeIndex设置各个音频流的音量级别,setStreamVolumeIndex会把这个整数的音量级别转化为适合人耳的对数级别,然后通过AudioPolicyService的AudioCommandThread,最终会将设置应用到AudioFlinger的相应的Track中。
音频策略管理
我想首先要搞清楚stream_type,device,strategy三者之间的关系:
- AudioSystem::stream_type 音频流的类型,一共有10种类型
- AudioSystem::audio_devices 音频输入输出设备,每一个bit代表一种设备,见前面的说明
- AudioPolicyManager::routing_strategy 音频路由策略,可以有4种策略
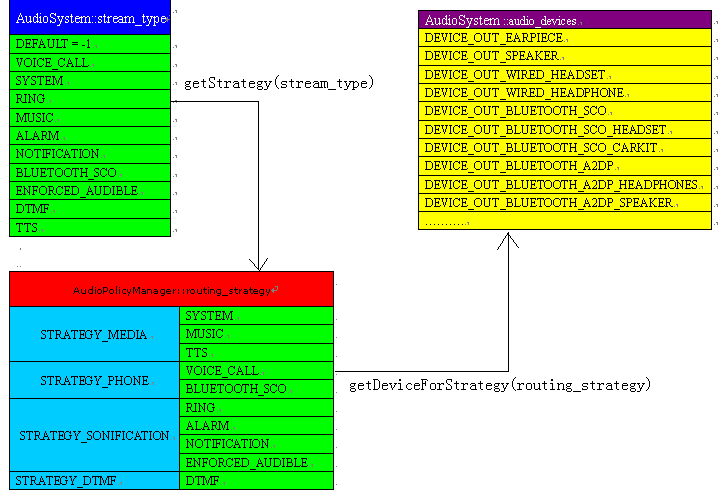
getStrategy(stream_type)根据stream type,返回对应的routing strategy值,getDeviceForStrategy()则是根据routing strategy,返回可用的device。Android把10种stream type归纳为4种路由策略,然后根据路由策略决定具体的输出设备。
成员变量mOutputs
- KeyedVector<audio_io_handle_t, AudioOutputDescriptor *> mOutputs; // list of output descriptors
这是AudioPolocyManager用管理输出的键值对向量(数组),通常AudioPolocyManager会打开3个输出句柄(audio_io_handle_t),它实际上就是AudioFlinger中某个PlaybackTread的ID。这3个句柄分别是:
- mHardwareOutput // hardware output handler
- mA2dpOutput // A2DP output handler
- mDuplicatedOutput // duplicated output handler: outputs to hardware and A2DP
可以通过startOutput()把某一个stream type放入到相应的输出中。
popCount()
这个函数主要用来计算device变量中有多少个非0位(计算32位数种1的个数),例如该函数返回2,代表同时有两个device要处理。之所以特别介绍它,是因为这个函数的实现很有意思:
- uint32_t AudioSystem::popCount(uint32_t u)
- {
- u = ((u&0x55555555) + ((u>>1)&0x55555555));
- u = ((u&0x33333333) + ((u>>2)&0x33333333));
- u = ((u&0x0f0f0f0f) + ((u>>4)&0x0f0f0f0f));
- u = ((u&0x00ff00ff) + ((u>>8)&0x00ff00ff));
- u = ( u&0x0000ffff) + (u>>16);
- return u;
- }
不知道各位看懂了么?
AudioCommandThread
这是AudioPolicyService中的一个线程,主要用于处理音频设置相关的命令。包括:
- START_TONE
- STOP_TONE
- SET_VOLUME
- SET_PARAMETERS
- SET_VOICE_VOLUME
每种命令的参数有相应的包装:
- class ToneData
- class VolumeData
- class ParametersData
- class VoiceVolumeData
START_TONE/STOP_TONE:播放电话系统中常用的特殊音调,例如:TONE_DTMF_0,TONE_SUP_BUSY等等。
SET_VOLUME:最终会调用AudioFlinger进行音量设置
SET_VOICE_VOLUME:最终会调用AudioFlinger进行电话音量设置
SET_PARAMETERS:通过一个KeyValuePairs形式的字符串进行参数设置,KeyValuePairs的格式可以这样:
- "sampling_rate=44100"
- "channels=2"
- "sampling_rate=44100;channels=2" // 组合形式
这些KeyValuePairs可以通过AudioPolicyService的成员函数setParameters()传入。