文本去重之MinHash算法
1.概述
![]()

![]()
跟SimHash一样,MinHash也是LSH的一种,可以用来快速估算两个集合的相似度。MinHash由Andrei Broder提出,最初用于在搜索引擎中检测重复网页。它也可以应用于大规模聚类问题。
2.Jaccard index
在介绍MinHash之前,我们先介绍下Jaccard index。
Jaccard index是用来计算相似性,也就是距离的一种度量标准。假如有集合A、B,那么,
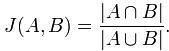
也就是说,集合A,B的Jaccard系数等于A,B中共同拥有的元素数与A,B总共拥有的元素数的比例。很显然,Jaccard系数值区间为[0,1]。
3.MinHash
先定义几个符号术语:
h(x): 把x映射成一个整数的哈希函数。
hmin(S):集合S中的元素经过h(x)哈希后,具有最小哈希值的元素。
那么对集合A、B,hmin(A) = hmin(B)成立的条件是A ∪ B 中具有最小哈希值的元素也在 ∩ B中。这里
有一个假设,h(x)是一个良好的哈希函数,它具有很好的均匀性,能够把不同元素映射成不同的整数。
所以有,Pr[hmin(A) = hmin(B)] = J(A,B),即集合A和B的相似度为集合A、B经过hash后最小哈希值相
等的概率。
有了上面的结论,我们便可以根据MinHash来计算两个集合的相似度了。一般有两种方法:
第一种:使用多个hash函数
为了计算集合A、B具有最小哈希值的概率,我们可以选择一定数量的hash函数,比如K个。然后用这K个hash函数分别对集合A、B求哈希值,对
每个集合都得到K个最小值。比如Min(A)k={a1,a2,...,ak},Min(B)k={b1,b2,...,bk}。
那么,集合A、B的相似度为|Min(A)k ∩ Min(B)k| / |Min(A)k ∪ Min(B)k|,及Min(A)k和Min(B)k中相同元素个数与总的元素个数的比例。
第二种:使用单个hash函数
第一种方法有一个很明显的缺陷,那就是计算复杂度高。使用单个hash函数是怎么解决这个问题的呢?请看:
前面我们定义过 hmin(S)为集合S中具有最小哈希值的一个元素,那么我们也可以定义hmink(S)为集合S中具有最小哈希值的K个元素。这样一来,
我们就只需要对每个集合求一次哈希,然后取最小的K个元素。计算两个集合A、B的相似度,就是集合A中最小的K个元素与集合B中最小的K个元素
的交集个数与并集个数的比例。
看完上面的,你应该大概清楚MinHash是怎么回事了。但是,MinHash的好处到底在哪里呢?计算两篇文档的相似度,就直接统计相同的词数和总的
次数,然后就Jaccard index不就可以了吗?
对,如果仅仅对两篇文档计算相似度而言,MinHash没有什么优势,反而把问题复杂化了。但是如果有海量的文档需要求相似度,比如在推荐系统
中计算物品的相似度,如果两两计算相似度,计算量过于庞大。下面我们看看MinHash是怎么解决问题的。
比如
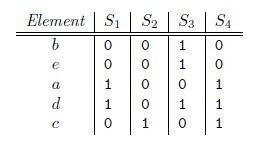
元素集合{a,b,c,d,e},其中s1={a,d},s2={c},s3={b,d,e},s4={a,c,d}
那么这四个集合的矩阵表示为:
如果要对某一个集合做MinHash,则可以从上面矩阵的任意一个行排列中选取一个,然后MinHash值是排列中第一个1的行号。
例如,对上述矩阵,我们选取排列
beadc,那么对应的矩阵为
那么,
h(S1) = a,同样可以得到h(S2) = c, h(S3) = b, h(S4) = a。
如果只对其中一个行排列做MinHash,不用说,计算相似度当然是不可靠的。因此,我们要选择多个行排列来计算MinHash,最后根据Jaccard index公式
来计算相似度。但是求排列本身的复杂度比较高,特别是针对很大的矩阵来说。因此,我们可以设计一个随机哈希函数去模拟排列,能够把行号0~n随机映射到0~n上。比如
H(0)=100,H(1)=3...。当然,冲突是不可避免的,冲突后可以二次散列。并且如果选取的随机哈希函数够均匀,并且当n较大时,冲突发生的概率还是比较低的。
说到这里,只是讨论了用MinHash对海量文档求相似度的具体过程,但是它到底是怎么减少复杂度的呢?
比如有n个文档,每个文档的维度为m,我们可以选取其中k个排列求MinHash,由于每个对每个排列而言,MinHash把一篇文档映射成一个整数,所以对k个排列计算MinHash就得到k个整数。那么所求的MinHash矩阵为n*k维,而原矩阵为n*m维。n>>m时,计算量就降了下来。
4.参考文献
(1) http://en.wikipedia.org/wiki/MinHash
(2) http://fuliang.iteye.com/blog/1025638