理解PVLAN技术 ( by quqi99 )
理解PVLAN技术 ( by quqi99 )
作者:张华 发表于:2013-08-11
版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本版权声明
( http://blog.csdn.net/quqi99)
为了隔离用户之间的报文,传统的办法是给每个用户分配一个VLAN。但缺点很多:
-
为每一个客户提供一个VLAN,ISP的设备必须有大量的接口。
-
随着用户的增多,生成树越来越复杂
-
维护多个VLAN意味着也要维护多个ACL,增加了网络配置的复杂度
-
VLAN的可用资源(1-4094)受到挑战,同时造成IP资源浪费
而PVLAN可以有效地保障用户数据安全,抑制病毒泛滥,并节省IP资源,有助于网络的优化,带给用户一个安全的网络。
尤其对于某些应用场景,如数据中心,一般虚机之间横向很少通信,主要是纵向和网关的通信,所以要求每个虚机属于一个VLAN降低洪泛时的广播流量。
这样它能将不同的用户放在隔离VLAN中实现客户的二层隔离,这样只需要一个隔离VLAN就可以保证接入网络的数据通信的安全性,这节省了VLAN的数目。
通过给主VLAN配置SVI(在cisco交换机中,SVI就是VLAN接口),所以PVLAN共享主VLAN的IP地址,实现了所有用户与默认网关的连接,而与PVLAN内的其他用户没有任何访问,这样就不用再划分子网了,一个FLAT子网足够。所以说PVLAN也能节省IP地址。一个PVLAN也只能有一个主VLAN,未同主VLAN建立关联的辅VLAN不支持ARP报文的学习以及路由转发。
如果一个用户内的多个虚机需要通信的话,可以用群体VLAN(Community VLAN)加以解决。
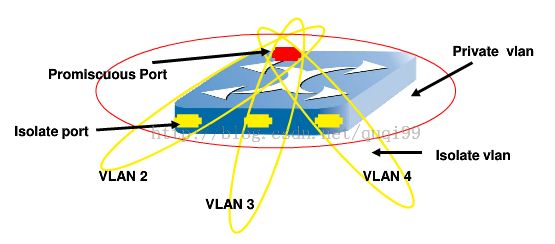
-
PVLAN中将VLAN中的端口分为两类,与用户相连的端口为隔离端口(Isolatedport),上行与路由器相连的为混杂端口(PromiscuousPort),隔离端口相互之间不能通信,只能与混杂端口通信。
-
这种两层VLAN隔离方法的,只有上层VLAN全局可见,相互于在一个VLAN内部又实现了用户隔离。这样即使同一VLAN中的用户,相互之间也不会受到广播的影响。
-
PVLAN将一个VLAN的二层广播域划分成多个子域,每个子域由一个PVLAN对组成:主VLAN(PrimaryVLAN)和辅助VLAN(SecondaryVLAN)。
硬件交换机配置PVLAN
在Cisco硬件交换机上的配置方法,配置一个隔离组,port2与port3为隔离端口,port1为混杂端口。
vlan private-map session-id <id>[community<port-list>][isolate <port-list>][promis<port-list>][vlan <vlan-list>]
vlan private-map session-id 1 isolate port2 port3 promisport1
show vlan private-map

OpenvSwitch中配置PVLAN
RFC 5517 (http://tools.ietf.org/html/rfc5517)
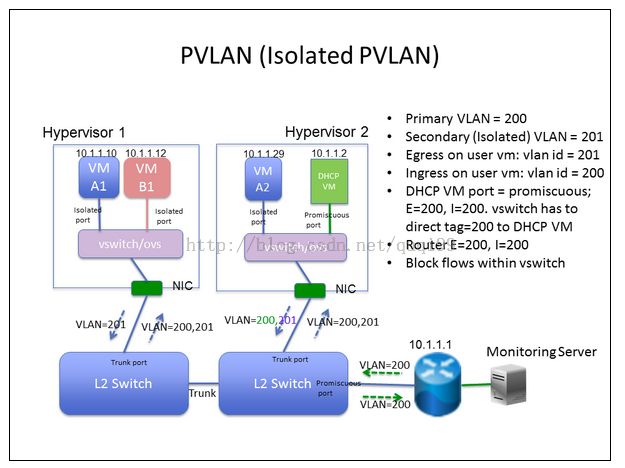
-
每一个和用户虚机相连的port设置成isolatedport,让它们之间不互访
-
Dhcp与gateway的port设置成promiscuous port
因为OVS没有实现PVLAN,所以可以按下列方式修改流表实现上述PVLAN需求:
-
1. For every traffic leave user VM, tagged with secondary isolate vlan tag.
-
2. Allow secondary isolated vlan tagged traffic reach DHCP server, by change the vlan tag to primary vlan tag.
-
3. The gateway should know nothing about PVLAN, and the switch connect to the gateway should translate allthe secondary vlan to primary vlan for communicating with gateway.
dl_vlan=0xffff代表没有打vlan的包,sec_iso_vlan=201
For OVS, flow table need following modifications:
-
1. For each VM:
-
<a> Tagged isolated vlan and go through flow-table again(for DHCP serverspecify handling):
-
priority=50,dl_vlan=0xffff,dl_src=$vm_mac,actions=mod_vlan_vid:$sec_iso_vlan,resubmit:$trunk_port
-
-
<b> Ifthere is no other process in the flow table, then output to trunkport:
-
priority=60,dl_vlan=$sec_iso_vlan,dl_src=$vm_mac,actions=output:$trunk_port
-
-
-
2. For each hosthas DHCP server:
-
<a> ARPfor DHCP server from other hosts:
-
priority=200,arp,dl_vlan=$sec_iso_vlan,nw_dst=$dhcp_ip,actions=strip_vlan,output:$dhcp_port
-
-
<b> Accept packets from outside(e.g. DNS):
-
priority=150,dl_vlan=$sec_iso_vlan,dl_dst=$dhcp_mac,actions=strip_vlan,output:$dhcp_port
-
-
<c> AcceptDHCP request from other hosts:
-
priority=100,udp,dl_vlan=$sec_iso_vlan,nw_dst=255.255.255.255,tp_dst=67,actions=strip_vlan,output:$dhcp_port
-
-
-
The VM migration and host restart would affect the rules, need to be reprogrammed.
下图是OpenStack中使用resubmit的场景:
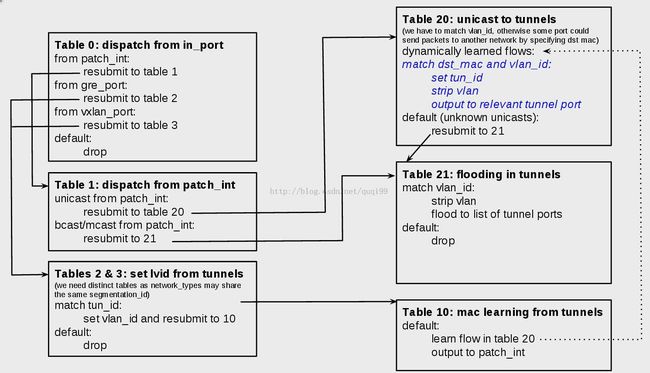
如果在一个OVS桥如br-tun里同时用了GRE和VXLAN这些遂道,且遂道端口也一样的话,就会现隔离安全问题。
之前Neutron的tunnel拓扑实现中,在br-tun里使用了流规则:
if network_type in constants.TUNNEL_NETWORK_TYPES:
if self.enable_tunneling:
# inbound unicast
self.tun_br.add_flow(priority=3, tun_id=segmentation_id,
dl_dst=port.vif_mac,
actions="mod_vlan_vid:%s,normal" %
lvm.vlan)
self.int_br.set_db_attribute("Port", port.port_name, "tag",
str(lvm.vlan))
# outbound
self.tun_br.add_flow(priority=4, in_port=self.patch_int_ofport,
dl_vlan=lvid,
actions="set_tunnel:%s,normal" %
segmentation_id)
# inbound bcast/mcast
self.tun_br.add_flow(
priority=3,
tun_id=segmentation_id,
dl_dst="01:00:00:00:00:00/01:00:00:00:00:00",
actions="mod_vlan_vid:%s,output:%s" %
(lvid, self.patch_int_ofport))
上面使用了"normal"作为action,这将引发安全问题,如会接受不清楚的广播。
所以从安全上讲的话任何时候都不应该用normal作为action,所以对于从遂道端口(tunnel ports)接收到的包应该动态地从OVS的20号表中学习MAC地址创建流规则,这样对于不清楚的广播再重发到表21,
代码见:https://review.openstack.org/#/c/41239/2/neutron/plugins/openvswitch/agent/ovs_neutron_agent.py,我解释一下:
在Neutron的遂道有两个网桥,br-int与br-tun,它们之间通过ovs的peer接口级联:
1) inbound, 从gre_port或vxlan_port进入br-tun的即入口流量,要转到表2&3, 匹配到遂道流量了打上本地标签,然后转到表10学习遂道远端的MAC地址然后输出到patch_int
2) outbound, 从patch_int 进入br-tun的即为出口流量,转到表1,单播转表20,多播或组播转表21
在表20中的单播中,要记录学习发消息的虚机的MAC地址,同时去掉tag,打上遂道号。默认是转到21。
在表21中的多播和广播中,去本地vlan,去洪泛到遂道端口,其他的就不转发了。
这块很难理解,核心思想就是:
之前的做法,进出的广播均无限制,现在是进来的广播就不让了(因为已经通过MAC学习到了),出去的广播只充许本机有的vlan的流量到相应同类型(指GRE或VXLAN)的端口。见代码:
ofports = ','.join(self.tun_br_ofports[tunnel_type])
for network_id, vlan_mapping in self.local_vlan_map.iteritems():
if vlan_mapping.network_type == tunnel_type:
self.tun_br.mod_flow(table=21,
priority=1,
dl_vlan=vlan_mapping.vlan,
actions="strip_vlan,"
"set_tunnel:%s,output:%s" %
(vlan_mapping.segmentation_id,
ofports))
2013.9.22添加:
今天发现社区有一个类似的patch,但又不完全相同,它能指定某些patch隔离:
https://review.openstack.org/#/c/30274/
1,虚机出来的流量受ovs的两条流规则只允许虚机到它的网关和dhcp的流量,https://review.openstack.org/#/c/30274/8/neutron/plugins/openvswitch/agent/ovs_neutron_agent.py:
priority=5, in_port=port.ofport, dl_src=$port.vif_mac, dl_dst="ff:ff:ff:ff:ff:ff", proto="arp", actions="mod_dl_dst:$gateway_mac,normal
priority=3, in_port=port.ofport, dl_src=$port.vif_mac, dl_dst="ff:ff:ff:ff:ff:ff", nw_src="0.0.0.0", nw_dst="255.255.255.255", proto="udp", tp_src="68", tp_dst="67", actions=$dhcp_mac
2,在l3-agent端,通过设置net.ipv4.conf.<gw-vm>.proxy_arp_pvlan只让流量从进来的那个网关接口出。
https://review.openstack.org/#/c/30274/8/neutron/agent/l3_agent.py
http://patchwork.ozlabs.org/patch/42132/
目前,虚机不支持vlan, 只有物理网络可以通过provider network来支持一层vlan, 所以当使用vlan模式时(不包括flat及tunnel)如果物理网络只有一个vlan的话, 那虚机里也只能用这一个, 所以这些时候pvlan就有用了, 可以物理是物理的vlan, 虚机是虚机的vlan, 但目前还不支持.
Linux Bridge中配置PVLAN
待研究
Reference
http://blog.ine.com/2008/07/14/private-vlans-revisited/
https://cwiki.apache.org/confluence/display/CLOUDSTACK/PVLAN+for+isolation+within+a+VLAN
地