Java命名和目录接口——JNDI
JNDI即Java命名和目录接口(JavaNaming and Directory Interface),它属于J2EE规范范畴,是J2EE的核心技术之一,提供了一组接口、类和关于命名空间的概念。JDNI是provider-based技术,它暴露一个API和一个服务供应接口(SPI)。它将名称和对象联系起来,使我们可以用名称访问对象。我们可以把JNDI简单地看成是里面封装了一个name到实体对象的映射,通过字符串可以方便得到想要的对象资源,例如JDBC、JMail、JMS、EJB等。这意味着任何基于名字的技术都能通过JNDI而提供服务,现在它支持的技术包含了LDAP、RMI、CORBA、NDS、NIS、DNS、Windows注册表等等。
竟然我们都可以直接各种服务,为什么还要在封装一层JNDI?总的来说,JNDI的出现就是为了分布式开发服务,用一条线把责任任务分成两边,一边的人负责开发这些分布式对象,一边的人只要使用这些分布式对象即可。两边的人不必是同属一个公司,并且两边的人开发通常不是并行的,也不必同属一个项目,就像一个应用服务器的JNDI中注册了一个数据源,不管在哪个项目中,只要有需要就可以通过JNDI使用这个数据源。总结起来就是随着分布式应用的发展,远程访问对象成为常用方法,尽管我们通过socket可以实现远程通信,但要关心每一个远程访问的具体细节并实现,这样局限性还是比较大,效率低下。而伴随着JNDI技术的出现,将大大简化远程调用,方便查找远程或本地的对象。
JNDI包含了很多的服务接口,如图3-1-8-1,JNDIAPI提供了访问不同JNDI服务的一个标准的统一的实现,其具体实现可由不同的Service Provider来完成,具体调用类及通信过程对用户来说是透明的。从架构层面上可以把JNDI分成五个层次,第一层是java编码层,通过它调用第二层的JNDI接口,第三层是JNDI管理器,第四层是JNDI互联网服务提供商接口层,用于规范各个厂商的实现,第五层就是各个厂商具体实现的细节了。
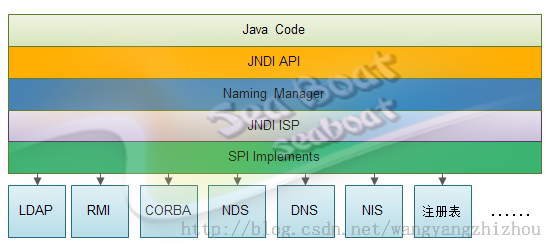
图3-1-8-1
JNDI接口在JDK中包含了5个包,这里有必要稍微介绍一下,
① javax.naming:这个包下面主要是用于访问命名服务的类和接口。比如说里面定义了Context接口,该接口是执行查找时命名服务的入口点。
② javax.naming.directory:这个包主要包含提供用访问目录服务的类和接口的扩展命名类和接口。例如,它增加了新的属性类,提供代表一个目录上下文的DirContext 接口,并且定义了用于检查和更新与目录对象相关的属性的方法。
③ javax.naming.event:这个包主要为访问命名和目录服务时提供事件通知以达到监控功能。例如,它定义了一个NamingEvent类,用于表示由命名/目录服务生成的事件,以及一个监视NamingEvents 类的NamingListener 接口。
④ javax.naming.ldap:这个包为LDAP 版本 3 扩展操作和空间提供特定的支持,而普通的javax.naming.directory 包没有提供这些支持。
⑤ javax.naming.spi:这个包提供方法以动态插入对通过javax.naming及其相关包访问命名和目录服务的支持。只有那些对创建服务提供程序有着浓厚兴趣的开发人员才对这个包感兴趣,例如本书主角Tomcat的开发者就必须跟这个包的类打交道。
上面我们了解了JNDI的大体结构,接着主要看看JNDI的运行机制,那么它的结构到底是怎样的,设计又是如何巧妙的呢?可以说jndi的主要工作就是维护操作两个对象:命名上下文和命名对象。他们的关系可以用下图3-1-8-2简单表示,其中圆圈表示命名上下文,星形表示命名上下文所绑定的命名对象。初始上下文为入口,假如你查找的对象的url是“A/C/O3”那么命名上下文将对这个url进行分拆,先找到名字为A的上下文,接着再找到C上下文,最后找到名字为O3的命名对象。类似的其他对象也是如此查找。这便是JNDI树,所有的命名对象和命名上下文都被绑定到树上,一般说来,命名上下文是树上的节点,而命名对象是树上的树叶,不管是命名对象还是命名上下文都有自己的名字。
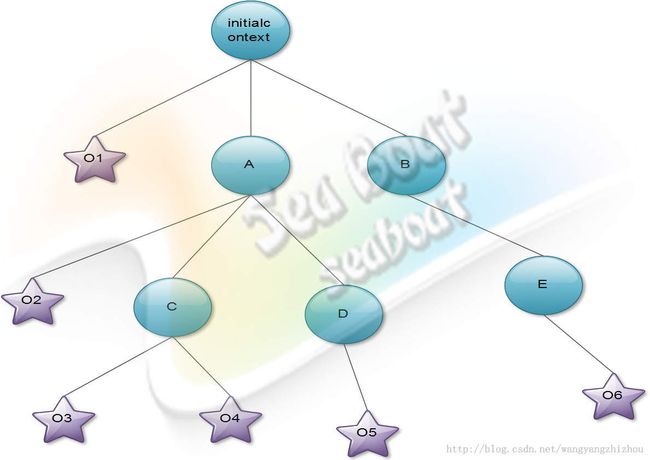
图3-1-8-2
谈谈命名对象,一般来说在JNDI中存在两种命名对象形态:①直接存在内存中的命名对象;②使用时再根据指定类及属性信息创建命名对象。第一种形态,将实例化好的对象通过Context.bind()绑定到上下文,当需要命名对象时通过Context.lookup()查找,这种情况是直接从内存中查找相应的对象,上下文会在内存中维护所有绑定了的命名对象。这种方式存在几个缺点,首先,内存大小限制了绑定到上下文的对象的数量;其次,一些未持久保存的对象在命名服务重启后不可恢复;最后,有些对象根本就不适合这种方式,例如数据库连接对象;第二种形态,将生成命名对象需要的类位置信息及一些属性信息进行绑定,那么在查找时就可以使用这些信息创建适合Java应用使用的Java对象,这种情况下,在绑定时可能需要额外做一些处理,例如将Java对象转化为对应的类位置信息及一些属性信息,绑定跟查找这两个相反的过程通过ObjectFactory和StateFactory两个工厂的getObjectInstance和getStateToBind方法进行实现。一般来说JNDI提供Reference类作为存储类位置信息及属性信息的标准方式,并鼓励命名对象实现这个类而不是自己另起炉灶,同时Serializable也可作为作为JNDI存储对象类型,表示可序列化的对象,另外Referenceable对象可通过Referenceable.getReference()返回Reference对象进行存储。
JNDI整个框架能正常运转起来,主要是对命名上下文和命名对象的处理进行了巧妙合理设计,我们对其进行解析研究,把大概的骨架摸清楚了后面整体看起来就清晰了。由于涉及到JNDI的源码,这里给出主要的一些类,如图3-1-8-3:

图3-1-8-3
从类图可以看到不管是命名上下文相关的类还是命名对象相关的类都围绕着NamingManager这个类,命名上下文相关的类则提供了上下文实现的一些策略;命名对象相关的类则提供了命名对象存储及创建的一些策略。这些交互总的可以分为两大部分,①通过FactoryBuilder模式、URL模式、环境变量模式三种机制确定初始上下文,相关接口类分别为InitialContextFactoryBuilder接口、xxxURLContextFactory类、InitialContext类;②通过工厂模式定义上下文中绑定和查找对象的转化策略,相关接口类为StateFactory接口、ObjectFactory接口。
围绕着NamingManager的这些类跟接口是JNDI能正常运行的基础,所有的上下文都要实现Context接口,这个接口主要的方法是lookup、bind,分别用于查找对象跟绑定对象。我们熟知的InitialContext即是JNDI的入口,NamingManager包含很多操作上下文方法,有两个方法有必要提一下,getStateToBind及getObjectInstance这两个方法将任意类型的对象转变成适合在命名空间存储的形式及将存储在命名空间中的信息转换成对象,两者是相反的过程,详细的转换策略可以在自定义的xxxFactory工厂类里面自己定义具体的转换策略的实现。另外定义了几个接口,用于约束在整个JNDI机制实现中特定的方法。为了让大家更好理解JNDI的运行机制,下面分步进行说明:
① 实例化InitialContext作为入口。
② 调用InitialContext的lookup或bind等方法。
③ lookup、bind等方法实际是getURLOrDefaultInitialCtx返回的上下文的lookup或bind方法。
④ getURLOrDefaultInitialCtx方法会判断是否用NamingManager的setInitialContextFactorybuilder方法设置了InitialContextFactorybuilder,即判断NamingManager里面的InitialContextFactorybuilder变量是否为空。
⑤ 根据④,如果设置了,则会调用InitialContextFactorybuilder的createInitialContextFactory方法返回一个InitialContextFactory,再调用这个工厂类的getInitialContext返回Context,至此得到了上下文。
⑥ 根据④,如果没设置,则获取url的scheme,例如“java:/comp/env”中java即为这个url的scheme,接着根据scheme继续判断怎么生产上下文。
⑦ 根据⑥,如果scheme不为空时,则根据Context.URL_PKG_PREFIXES变量的值作为工厂的前缀,然后指定上下文工厂类路径,规则为:前缀.scheme.schmeURLContextFactory,例如前缀值为com.sun.jndi,scheme为java,则工厂类的路径为com.sun.jndi.java.javaURLContextFactory,接着调用工厂类的getObjectInstance返回上下文。如果按照上面获取上下文失败则根据Context.INITIAL_CONTEXT_FACTOR变量指定的工厂类生成上下文。
⑧ 根据⑥,如果scheme为空时,则根据实例化InitialContext时传入的Context.INITIAL_CONTEXT_FACTORY变量指定的工厂类,调用其getInitialContext方法生成上下文。
⑨ 经过上面8个步骤,已经把真正执行bind跟lookup的上下文实例确定出来了,此时如果调用bind方法就会间接调用getStateToBind把即将被绑定的对象进行转换成JNDI鼓励的存储类型,而如果调用lookup方法则会间接调用getObjectInstance把JNDI鼓励的存储类型数据转化为Java程序使用的Java对象。
⑩ 调用bind时,NamingManager.getStateToBind(Object obj, Name name, ContextnameCtx,Hashtable<?,?> environment)根据环境尝试获取StateFactory,如果设置了StateFactory则使用这个工厂的getStateToBind方法实现具体转化策略。
⑪ 调用lookup时,NamingManager.getObjectInstance(Object refInfo,Name name, Context nameCtx,Hashtable<?,?> environment)根据refInfo对象的getFactoryClassName方法得到资源的工厂类,再由这个工厂类的getObjectInstance方法实现具体转化策略。例如Tocmat中,用ResourceRef作为JNDI鼓励的存储类型,当把一个ResourceRef对象传进NamingManager.getObjectInstance方法中,将会调用ResourceRef对象指定的资源工厂类ResourceFactory的getObjectInstance方法生成Java对象。
总的来说优先级最高的是InitialContextFactorybuilder,如果存在则直接根据builder返回上下文了,其它工厂类相关变量失效,例如Context.INITIAL_CONTEXT_FACTORY和Context.URL_PKG_PREFIXES;接着根据有无scheme分别利用Context.URL_PKG_PREFIXES和Context.INITIAL_CONTEXT_FACTORY变量指定的工厂类创建上下文。
在了解了以上JNDI运行机制再看看下面我们常见程序,其实就是JNDI的使用,先设置变量,再传进InitialContext进行实例化,最后获取数据源。根据上面对jndi框架的剖析,从下面三段代码你能想象到内部的运行逻辑是怎样的了吗?他们之间分别有什么不同的呢?
①
Hashtable<String, String> env = new Hashtable<String,String>();
env.put(Context.INITIAL_CONTEXT_FACTORY,"org.apache.naming.factory. DataSourceLinkFactory");
env.put(Context.URL_PKG_PREFIXES,"org.apache.naming");
Context context = new InitialContext(env);
DataSource ds = (DataSource)context.lookup("jdbc/MyDB");
②
Context context = new InitialContext();
DataSource ds = (DataSource)context.lookup("java:comp/evn/jdbc/myDB");
③
Hashtable<String, String> env = new Hashtable<String,String>();
NamingManager.setInitialContextFactoryBuilder(new XxxInitialContextFactoryBuilder());
Context context = new InitialContext(env);
喜欢研究java的同学可以交个朋友,下面是本人的微信号:
