现代信息检索2-----布尔检索(Boolean Retrieval)
下面我们进入正式的学习,希望这个系列会对自己有用,同样对你也有用!加油……
布尔检索(Boolean Retrieval),布尔对于我们来说对比较熟悉,就是不是0就是1。顾名思义,布尔检索肯定跟0,1分不开了。剩下的我还是按照ppt顺序,娓娓道来吧。
1.信息检索:
Information Retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers).
信息检索是从大规模非结构化数据(通常是文本)的集合(通常保存在计算机上)中找出满足用户信息需求的资料(通常是文档)的过程。
这是中英文的定义。之前在第一节也说过这个定义。现在我们就按照高中的学习方法对这个定义深究下。
关键词一--------非结构化数据。结构化数据是什么呢?即我们经常看的表格中分类好的数据。如下:
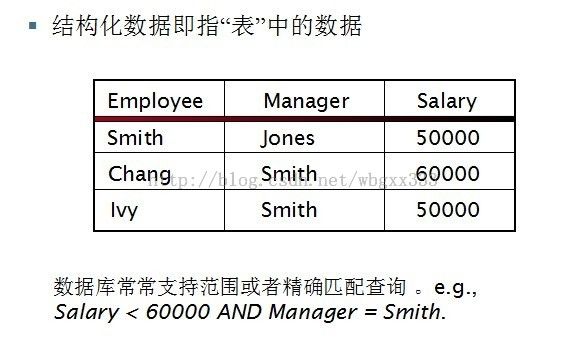
根据表中我们可以很容易的查到Salary < 60000 AND Manager 就是smith这个人。但现实是复杂的,往往我们见到的都是非结构化数据。通常指的是自由文本。比如:关键词加上操作符号的查询。或者是更复杂的概念性查询:找出所有的有关药物滥用(drug abuse)的网页。我们应该怎么办?还有,经典的检索模型一般都针对自由文本进行处理。这里。还提到一个半结构化数据的概念。比如:<title>李甲主页</title>和 <body>…</body> …。半结构化查询:Title contains data AND Bullets contain search。等等……
最后需要提出的是,现实生活中这三种数据都是存在的,而且可能大量存在。
2布尔检索
针对布尔查询的检索,布尔查询是指利用 AND, OR 或者 NOT操作符将词项 连接起来的查询。
3 一个例子
问题:莎士比亚的哪部剧本包含Brutus及Caesar但是不包含Calpurnia? 布尔表达式为 Brutus AND Caesar AND NOT Calpurnia。
笨方法: 从头到尾扫描所有剧本,对每部剧本判断它是否包含Brutus AND Caesar ,同时又不包含Calpurnia
这个方法为什么不好呢?速度超慢 (特别是大型文档集)、处理NOT Calpurnia 并不容易(一旦包含即可停止判断)、不太容易支持其他操作 (e.g., find the word Romans near countrymen) 、不支持检索结果的排序 (即只返回较好的结果)。
关联矩阵:

这个矩阵很重要,也许是使自然语言处理迈入新的阶段吧。也许你现在看起来是那么顺其自然。我们继续说关联向量吧,关联矩阵的每一列都是 0/1向量,每个0/1都对应一个词项。给定查询Brutus AND Caesar AND NOT Calpurnia,取出三个列向量 ,并对Calpurnia 的列向量求补,最后按位进行与操作。110100 AND 110111 AND 101111 = 100100。这样最后的1对应的剧本就是我们所要找到的。相信你应该可以明白的。
4.IR的一些问题
基本假设:
文档集Collection: 由固定数目的文档组成
目标: 返回与用户需求相关的文档并辅助用户来完成某项任务
相关性Relevance
主观的概念
反映对象的匹配程度
不同应用相关性不同
检索过程:

检索效果的评价:
正确率:返回结果文档中正确的比例。如返回80篇文档,其中20篇相关,正确率1/4
召回率:全部相关文档中被返回的比例。如返回80篇文档,其中20篇相关,但是总的应该相关的文档是100篇,召回率1/5
正确率和召回率反映检索效果的两个方面,缺一不可。
假定N = 1 百万篇文档(1M), 每篇有1000个词(1K),假定每个词平均有6个字节(包括空格和标点符号), 那么所有文档将约占6GB 空间。假定词汇表的大小(即词项个数) M = 500K
,那么词项-文档矩阵将非常大,是 500K x 1M=500G。但是但是该矩阵中最多有10亿(1G)个1,所以词项-文档矩阵高度稀疏(sparse)。有没有更好的办法呢?比如仅仅记录所有1的位置。这或许是个好的方法。
5.倒排索引(Inverted index)
对每个词项t, 记录所有包含t的文档列表。每篇文档用一个唯一的docID来表示,通常是正整数,如1,2,3…
通常采用变长表方式来存储docID列表,磁盘上,顺序存储方式比较好,便于快速读取;内存中,采用链表或者可变长数组方式,存储空间/易插入之间需要平衡。
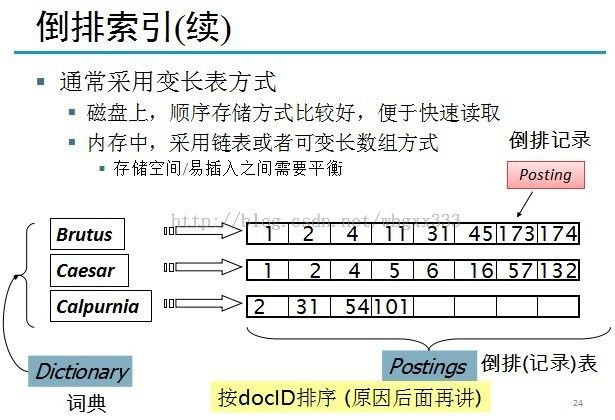
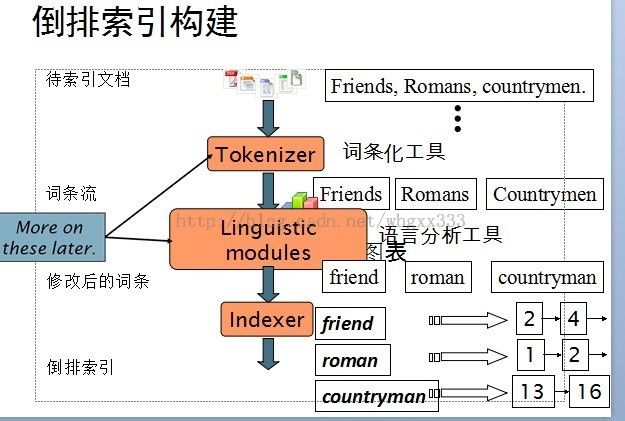
左边的倒排记录表就是我们最后统计到的结果,也就是经过右图的一系列步骤就可以写出这个倒排表。
下面着重介绍索引构建过程。第一步是词条序列。我们从文档中读出<词条,docID>二元组。第二步是排序。按词项排序,然后每个词项按docID排序。这步是核心步骤。第三步是词典和倒排记录表。某个词项在单篇文档中的多次出现会被合并,拆分成词典和倒排记录表两部分,每个词项出现的文档数目(doc. frequency, DF)会被加入。
具体过程见下图:

这样的存储开销是非常大的。如何快速构建索引?如何减少存储开销?这两个问题我们需要去思考。
6 布尔检索
之前,我们已经建立了索引,现在我们怎么利用这个来处理查询。首先,我们需要定位某个词项,然后返回倒排记录表,在根据交还是并来处理我们的倒排记录表。
and是交集,or是并集,not是减。比如:killed and brutus。由于brutus在二个文档都出现了,而killed只在第一个文档出现,我们求交集就知道是第一个文档。当然我举的例子比较简单了。实际上,是很复杂的。
下面我们来看看这个优化:
1.合并过程。即求交集或者并集的时候,这个需要遍历所有的docID。每个倒排记录表都有一个定位指针,两个指针同时从前往后扫描, 每次比较当前指针对应倒排记录,然后移动某个或两个指针。合并时间为两个表长之和的线性时间。假定表长分别为x 和y, 那么上述合并算法的复杂度为 O(x+y),关键原因: 倒排记录表按照docID排序。
2.查询过程:如果有n个词项的and?我们通常按照表从小到大(即df从小到大)的顺序进行处理(每次从最小的开始合并),这个就是为什么保存df的原因。
更通用的优化策略:
e.g., (madding OR crowd) AND (ignoble OR strife)。每个布尔表达式都能转换成上述形式(合取范式),获得每个词项的df。(保守)通过将词项的df相加,估计每个OR表达式对应的倒排记录表的大小,按照上述估计从小到大依次处理每个OR表达式。
布尔检索的优点:
构建简单,或许是构建IR系统的一种最简单方式
在30多年中是最主要的检索工具
当前许多搜索系统仍然使用布尔检索模型:电子邮件、文献编目、Mac OS X Spotlight工具。布尔检索例子: WestLaw http://www.westlaw.com/
这里有两个例子,想看的可以去看下ppt。
布尔检索的缺点
布尔查询构建复杂,不适合普通用户。构建不当,检索结果过多或者过少
没有充分利用词项的频率信息
通常出现的越多越好,需要利用词项在文档中的词项频率(term frequency, tf)信息
不能对检索结果进行排序
至此,第二节的布尔检索的内容结束。欢迎指正……