lucene 正排数据
当我们通过倒排,检索得到的是需要返回docid, 我们还需要根据id,从正排中得到具体的doc内容,再返回。
lucene中的正排是放到 fdx,fdt两个文件中,后者存放具体的数据,前者是对后者的一个索引(第n个doc数据在fdt中的位置)
我们来看看这两个文件如何建立的
一 首先建立两个文件
org/apache/lucene/index/FieldsWriter.java
FieldsWriter(Directory directory, String segment, FieldInfos fn) throws IOException { this.directory = directory; this.segment = segment; fieldInfos = fn; boolean success = false; try { //根据当前断和文件的扩展名,得到两个文件输出流 fieldsStream = directory.createOutput(IndexFileNames.segmentFileName(segment, IndexFileNames.FIELDS_EXTENSION)); indexStream = directory.createOutput(IndexFileNames.segmentFileName(segment, IndexFileNames.FIELDS_INDEX_EXTENSION)); //两个文件的开始都需要写入标志格式一个变量 fieldsStream.writeInt(FORMAT_CURRENT); indexStream.writeInt(FORMAT_CURRENT); success = true; } finally { if (!success) { abort(); } } }
二 添加文档的时候
org/apache/lucene/index/FieldsWriter.java
final void addDocument(Document doc) throws IOException { //往索引文件中写入当前文件的位置 indexStream.writeLong(fieldsStream.getFilePointer()); int storedCount = 0; List<Fieldable> fields = doc.getFields(); for (Fieldable field : fields) { if (field.isStored()) storedCount++; } //数据文件中写入字段的个数 fieldsStream.writeVInt(storedCount); //数据文件中写入需要存储字段的信息 for (Fieldable field : fields) { if (field.isStored()) writeField(fieldInfos.fieldInfo(field.name()), field); } }
从代码中可以很清楚看到:
1 在索引中加入doc开始的位置
2 往数据中写入一个doc具有多少个需要存储的field
3 循环存储这些field
我们在来看看 writeField 函数
final void writeField(FieldInfo fi, Fieldable field) throws IOException { //写字段的序号 fieldsStream.writeVInt(fi.number); //8个标志位信息 byte bits = 0; if (field.isTokenized()) bits |= FieldsWriter.FIELD_IS_TOKENIZED; if (field.isBinary()) bits |= FieldsWriter.FIELD_IS_BINARY; fieldsStream.writeByte(bits); //具体的值 if (field.isBinary()) { final byte[] data; final int len; final int offset; data = field.getBinaryValue(); len = field.getBinaryLength(); offset = field.getBinaryOffset(); fieldsStream.writeVInt(len); fieldsStream.writeBytes(data, offset, len); } else { fieldsStream.writeString(field.stringValue()); } }
同样,我们可以看出,存储一个field ,其实就是
1 这个field num ,也就是doc的第几个字段
2 字段的一个标志属性(是否二进制、是否分词等)
3 具体的值: 这里根据是否二进制进行区分,如果是二进制,那么是数据长度+内容,否则就是直接内容
整个结构很清晰,在借用 forfuture1978 的一张图,更明白:
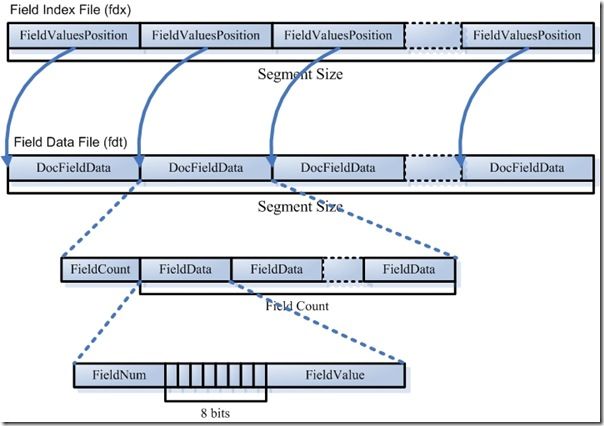
上面介绍了文件的写,现在我们介绍下文件的读入
当我们得到了一个doc id ,我们就可以从文件读入数据,来构建一个doc
org/apache/lucene/index/FieldsReader.java
final Document doc(int n, FieldSelector fieldSelector) throws CorruptIndexException, IOException { //根据id,从索引文件中得到doc数据的位置 seekIndex(n); long position = indexStream.readLong(); fieldsStream.seek(position); Document doc = new Document(); int numFields = fieldsStream.readVInt(); //遍历所有的字段 for (int i = 0; i < numFields; i++) { //字段的id int fieldNumber = fieldsStream.readVInt(); //得到字段的信息 FieldInfo fi = fieldInfos.fieldInfo(fieldNumber); FieldSelectorResult acceptField = fieldSelector == null ? FieldSelectorResult.LOAD : fieldSelector.accept(fi.name); byte bits = fieldsStream.readByte(); assert bits <= FieldsWriter.FIELD_IS_COMPRESSED + FieldsWriter.FIELD_IS_TOKENIZED + FieldsWriter.FIELD_IS_BINARY; boolean compressed = (bits & FieldsWriter.FIELD_IS_COMPRESSED) != 0; assert (compressed ? (format < FieldsWriter.FORMAT_LUCENE_3_0_NO_COMPRESSED_FIELDS) : true) : "compressed fields are only allowed in indexes of version <= 2.9"; boolean tokenize = (bits & FieldsWriter.FIELD_IS_TOKENIZED) != 0; boolean binary = (bits & FieldsWriter.FIELD_IS_BINARY) != 0; //TODO: Find an alternative approach here if this list continues to grow beyond the //list of 5 or 6 currently here. See Lucene 762 for discussion if (acceptField.equals(FieldSelectorResult.LOAD)) { addField(doc, fi, binary, compressed, tokenize); } else if (acceptField.equals(FieldSelectorResult.LOAD_AND_BREAK)){ addField(doc, fi, binary, compressed, tokenize); break;//Get out of this loop } else if (acceptField.equals(FieldSelectorResult.LAZY_LOAD)) { addFieldLazy(doc, fi, binary, compressed, tokenize, true); } else if (acceptField.equals(FieldSelectorResult.LATENT)) { addFieldLazy(doc, fi, binary, compressed, tokenize, false); } else if (acceptField.equals(FieldSelectorResult.SIZE)){ skipField(binary, compressed, addFieldSize(doc, fi, binary, compressed)); } else if (acceptField.equals(FieldSelectorResult.SIZE_AND_BREAK)){ addFieldSize(doc, fi, binary, compressed); break; } else { skipField(binary, compressed); } } return doc; }
上面过程:
一 根据id在fdx 文件中找到doc数据的位置
二 在doc文件中,得到字段的个数,再循环的处理每个字段: 字段的序号,字段的标志位以及字段的值
其中根据字段的序号可以得到一些字段的信息,这个会影响后面读字段值的行为,字段值读取调用了 addField函数,暂时不介绍了。
参考资料:
http://forfuture1978.iteye.com/blog/546832 lucene 索引结构
http://blog.csdn.net/a276202460/archive/2010/06/05/5650026.aspx lucene 索引结构四 _N.fdt _N.fdx