Java代码的编译、执行
JVM的标准结构如下所示:
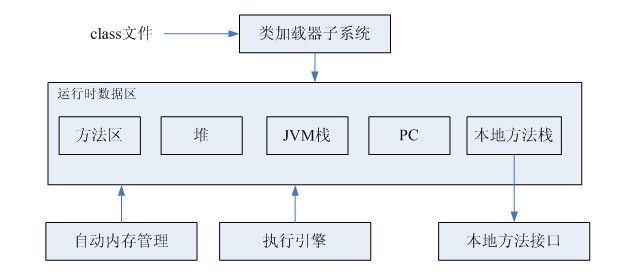
JVM负责装载class文件并执行。
1.编译机制
JVM规范中定义了class文件的格式,但并未定义Java源码如何编译为class文件,各厂商在实现JDK时通常会将符合Java语言规范的源码编译为class文件的编译器,例如在Sun JDK中就是javac,Eclipse中也有自带的编译器。主要步骤如下:
源码文件->分析和输入到符号表(Parse and Enter)->注解处理(Annotation Processing)->语义分析和生成class文件(Analyse and Generate)->class文件
下面简单介绍以上三个步骤:
1.1 分析和输入到符号表(Parse and Enter)
Parse过程所做的为词法和语法分析。词法分析(com.sun.tools.javac.parser.Scanner)要完成的是将代码字符串转变为token序列(例如Token.EQ(name:=));语法分析(com.sun.tools.javac.parser.Parser)要完成的是根据语法由token序列生成抽象语法树 。
Enter(com.sun.tools.javac.comp.Enter)过程为将符号输入到符号表,通常包括确定类的超类型和接口、根据需要添加默认构造器、将类中出现的符号输入类自身的符号表中等。
1.2 注解处理(Annotation Processing)
该步骤主要用于处理用户自定义的annotation,可能带来的好处是基于annotation来生成附加的代码或进行一些特殊的检查,从而节省一些共用的代码的编写,例如当采用Lombok 时,可编写如下代码:
- public class User{
- private @Getter String username;
- }
编译时引入Lombok对User.java进行编译后,再通过javap查看class文件可看到自动生成了public String getUsername()方法。
此功能基于JSR 269 ,在Sun JDK 6中提供了支持,在Annotation Processing进行后,再次进入Parse and Enter步骤。
1.3 语义分析和生成class文件(Analyse and Generate)
Analyse步骤基于抽象语法树进行一系列的语义分析,包括将语法树中的名字、表达式等元素与变量、方法、类型等联系到一起;检查变量使用前是否已声明;推导泛型方法的类型参数;检查类型匹配性;进行常量折叠;检查所有语句都可到达;检查所有checked exception都被捕获或抛出;检查变量的确定性赋值(例如有返回值的方法必须确定有返回值);检查变量的确定性不重复赋值(例如声明为final的变量等);解除语法糖(消除if(false) {…} 形式的无用代码;将泛型Java转为普通Java;将含有语法糖的语法树改为含有简单语言结构的语法树,例如foreach循环、自动装箱/拆箱等)等。
在完成了语义分析后,开始生成class文件(com.sun.tools.javac.jvm.Gen),生成的步骤为:首先将实例成员初始化器收集到构造器中,将静态成员初始化器收集为<clinit>();接着将抽象语法树生成字节码,采用的方法为后序遍历语法树,并进行最后的少量代码转换(例如String相加转变为StringBuilder操作);最后从符号表生成class文件。
上面简单介绍了基于javac如何将java源码编译为class文件 ,除javac外,还可通过ECJ(Eclipse Compiler for Java) 或Jikes 等编译器来将Java源码编译为class文件。
class文件中并不仅仅存放了字节码,还存放了很多辅助jvm来执行class的附加信息,一个class文件包含了以下信息。
结构信息
包括class文件格式版本号及各部分的数量与大小的信息。
元数据
简单来说,可以认为元数据对应的就是Java源码中"声明"与"常量"的信息,主要有:类/继承的超类/实现的接口的声明信息、域(Field)与方法声明信息和常量池。
方法信息
简单来说,可以认为方法信息对应的就是Java源码中"语句"与"表达式"对应的信息,主要有:字节码、异常处理器表、求值栈与局部变量区大小、求值栈的类型记录、调试用符号信息。
以一段简单的代码来说明class文件格式。
public class Foo{
private static final int MAX_COUNT=1000;
private static int count=0;
public int bar() throws Exception{
if(++count >= MAX_COUNT){
count=0;
throw new Exception("count overflow");
}
return count;
}
}
执行javac -g Foo.java(加上-g是为了生成所有的调试信息,包括局部变量名及行号信息,在不加-g的情况下默认只生成行号信息)编译此源码,之后通过javap -c -s -l -verbose Foo来查看编译后的class文件,结合class文件格式来看其中的关键内容。
// 类/继承的超类/实现的接口的声明信息
public class Foo extends java.lang.Object
SourceFile: "Foo.java"
// class文件格式版本号,major version: 50表示
为jdk 6,49为jdk 5,48为jdk 1.4,只有高版本能执行
低版本的class文件,这也是jdk 5不能执行jdk 6编译的代码的原因。
minor version: 0
major version: 50
// 常量池,存放了所有的Field名称、方法名、方法签名、
类型名、代码及class文件中的常量值。
Constant pool:
const #1 = Method #7.#27; // java/lang/Object."<init>":()V
const #2 = Field #6.#28; // Foo.count:I
const #3 = class #29; // java/lang/Exception
const #4 = String #30; // count overflow
const #5 = Method #3.#31; // java/lang/
Exception."<init>":(Ljava/lang/String;)V
…
const #34 = Asciz (Ljava/lang/String;)V;
{
// 将符号输入到符号表时生成的默认构造器方法
public Foo();
…
// bar方法的元数据信息
public int bar() throws java.lang.Exception;
Signature: ()I
// 对应字节码的源码行号信息,可在编译的时候通过
-g:none去掉行号信息,行号信息对于查找问题而言至关重要,
因此最好还是保留。
LineNumberTable:
line 9: 0
line 10: 15
line 11: 19
line 13: 29
// 局部变量信息,如生成的class文件中无局部变量信息,
则无法知道局部变量的名称,并且局部变量信息是和方法绑定的,
接口是没有方法体的,所以ASM之类的在获取接口方法时,
是拿不到方法中参数的信息的。
LocalVariableTable:
Start Length Slot Name Signature
0 33 0 this LFoo;
Code:
Stack=3, Locals=1, Args_size=1
// 方法对应的字节码
0: getstatic #2; //Field count:I
..
29: getstatic #2; //Field count:I
32: ireturn
…
// 记录有分支的情况(对应代码中if..、for、while等),
在下一节"类加载机制"中会讲解这个的作用
StackMapTable: number_of_entries = 1
frame_type = 29 /* same */
// 异常处理器表
Exceptions:
throws java.lang.Exception
..
}
从上可见,class文件是个完整的自描述文件,字节码在其中只占了很小的部分,源码编译为class文件后,即可放入jvm中执行。执行时jvm首先要做的是装载class文件,这个机制通常称为类加载机制。
2. 类加载机制
类加载机制是指.class文件加载到JVM,并形成Class对象的机制,之后应用就可对Class对象进行实例化并调用,类加载机制可在运行时动态加载外部的类、远程网络下载过来的class文件等。除了该动态化的优点外,还可通过JVM的类加载机制来达到类隔离的效果,例如Application Server中通常要避免两个应用的类互相干扰。
JVM将类加载过程划分为三个步骤:装载、链接和初始化。装载和链接过程完成后,即将二进制的字节码转换为Class对象;初始化过程不是加载类时必须触发的,但最迟必须在初次主动使用对象前执行,其所作的动作为给静态变量赋值、调用<clinit>()等。
加载的步骤如下所示:
装载(Load)->链接(Link)[校验(Verify)->准备(Prepare)->解析(Resolve)]->初始化(Initialize)
2.1 装载(Load)
装载过程负责找到二进制字节码并加载至JVM中,JVM通过类的全限定名(com.bluedavy. HelloWorld)及类加载器(ClassLoaderA实例)完成类的加载,同样,也采用以上两个元素来标识一个被加载了的类:类的全限定名+ClassLoader实例ID。类名的命名方式如下:
对于接口或非数组型的类,其名称即为类名,此种类型的类由所在的ClassLoader负责加载;
对于数组型的类,其名称为"["+(基本类型或L+引用类型类名;),例如byte[] bytes=new byte[512],该bytes的类名为:[B; Object[] bjects=new Object[10],objects的类名则为:[Ljava.lang.Object;,数组型类中的元素类型由所在的ClassLoader负责加载,但数组类则由JVM直接创建。
2.2 链接(Link)
链接过程负责对二进制字节码的格式进行校验、初始化装载类中的静态变量及解析类中调用的接口、类。
二进制字节码的格式校验遵循Java Class File Format(具体请参见JVM规范)规范,如果格式不符合,则抛出VerifyError;校验过程中如果碰到要引用到其他的接口和类,也会进行加载;如果加载过程失败,则会抛出NoClassDefFoundError。
在完成了校验后,JVM初始化类中的静态变量,并将其值赋为默认值。
最后对类中的所有属性、方法进行验证,以确保其要调用的属性、方法存在,以及具备相应的权限(例如public、private域权限等)。如果这个阶段失败,可能会造成NoSuchMethodError、NoSuchFieldError等错误信息。
2.3 初始化(Initialize)
初始化过程即执行类中的静态初始化代码、构造器代码及静态属性的初始化,在以下四种情况下初始化过程会被触发执行:
1)调用了new;
2)反射调用了类中的方法;
3)子类调用了初始化;
4)JVM启动过程中指定的初始化类。
在执行初始化过程之前,首先必须完成链接过程中的校验和准备阶段,解析阶段则不强制。
JVM的类加载通过ClassLoader及其子类来完成,分为Bootstrap ClassLoader、Extension ClassLoader、System ClassLoader及User-Defined ClassLoader。这4种ClassLoader的关系如下所示:
Bootstrap Class Loader----java_home/jre/lib/rt.jar
Extention Class Loader ----java_home/jre/lib/ext/*.jar
System Class Loader ----classpath
UserDefined Class Loader
(1) Bootstrap ClassLoader
Sun JDK采用C++实现了此类,此类并非ClassLoader的子类,在代码中没有办法拿到这个对象,Sun JDK启动时会初始化此ClassLoader,并由ClassLoader完成$JAVA_HOME中jre/lib/rt.jar里所有class文件的加载,jar中包含了Java规范定义的所有接口及实现。
(2)Extension ClassLoader
JVM用此ClassLoader来加载扩展功能的一些jar包,例如Sun JDK中目录下有dns工具jar包等,在Sun JDK中ClassLoader对应的类名为ExtClassLoader。
(3)System ClassLoader
JVM用此ClassLoader来加载启动参数中指定的Classpath中的jar包及目录,在Sun JDK中ClassLoader对应的类名为AppClassLoader。
例如一段这样的代码:
- public class ClassLoaderDemo {
- public static void main(String[] args) throws Exception{
- System.out.println(ClassLoaderDemo.class.getClassLoader());
- System.out.println(ClassLoaderDemo.class.getClassLoader().getParent());
- System.out.println(ClassLoaderDemo.class.
- getClassLoader().getParent().getParent());
- }
- }
执行后显示的信息类似如下:
- (sun.misc.Launcher$AppClassLoader)
- (sun.misc.Launcher$ExtClassLoader)
- null
按照上面的描述,就可看到典型的System ClassLoader、Extension ClassLoader,而由于Bootstrap ClassLoader并不是Java中的ClassLoader,因此Extension ClassLoader的parent为null。
(4)User-Defined ClassLoader
User-Defined ClassLoader是Java开发人员继承ClassLoader抽象类自行实现的ClassLoader,基于自定义的ClassLoader可用于加载非Classpath中(例如从网络上下载的jar或二进制)的jar及目录、还可以在加载之前对class文件做一些动作,例如解密等。
JVM的ClassLoader采用的是树形结构,除BootstrapClassLoader外,其他的ClassLoader都会有parent ClassLoader,User-Defined ClassLoader默认的parent ClassLoader为System ClassLoader。加载类时通常按照树形结构的原则来进行,也就是说,首先应从parent ClassLoader中尝试进行加载,当parent中无法加载时,应再尝试从System ClassLoader中进行加载,System ClassLoader同样遵循此原则,在找不到的情况下会自动从其parent ClassLoader中进行加载。值得注意的是,由于JVM是采用类名加Classloader的实例来作为Class加载的判断的,因此加载时不采用上面的顺序也是可以的,例如加载时不去parent ClassLoader中寻找,而只在当前的ClassLoader中寻找,会造成树上多个不同的ClassLoader中都加载了某Class,并且这些Class的实例对象都不相同,JVM会保证同一个ClassLoader实例对象中只能加载一次同样名称的Class,因此可借助此来实现类隔离的需求,但有时也会带来困惑,例如ClassCastException。因此在加载类的顺序上要根据需求合理把握,尽量保证从根到最下层的ClassLoader上的Class只加载了一次。
ClassLoader抽象类提供了几个关键的方法:
(1)loadClass
此方法负责加载指定名字的类,ClassLoader的实现方法为先从已经加载的类中寻找,如果没有,则继续从Parent Class Loader中寻找;如果仍然没找到,则从System ClassLoader中寻找,最后再调用findClass方法寻找;如果要改变类的加载顺序,则可以覆盖此方法;如果加载顺序相同,则可以通过覆盖findClass来做特殊处理,比如解密、固定路径寻找等。当通过整个寻找类的过程仍然没有获取Class对象时,则抛出ClassNotFoundException。
(2)findLoadedClass
此方法负责从当前ClassLoader实例对象的缓存中寻找已知加载的类,调用的为native方法。
(3)findClass
此方法直接抛出ClassNotFoundException,因此要通过覆盖loadClass或此方法来自定义方法加载类。
(4)findSystemClass
此方法负责从System Class Loader中寻找类,如果没有找到,则继续从BootStrap Class Loader中寻找,如果仍未找到,则返回null。
(5)defineClass
此方法负责将二进制的字节码转化为Class对象,这个方法对于自定义加载类而言很重要,若二进制字节码的格式不符合JVM Class的规范,则抛出ClassFormatError,如果生成的类名和二进制字节码中的不同,则抛出NoClassDefError;若加载的class是受保护的,采用不同签名的或者类名是以Java开头的,则抛出SecurityException;若加载的calss在此ClassLoader中已加载,则抛出LinkageError。
(6)resolveClass
此方法负责完成Class对象的链接,如果连接过,则直接返回。
当调用Class.forName来获取一个对应名称的class对象时,JVM会从方法栈上寻找第一个ClassLoader,通常也就是执行Class.forName所在类的ClassLoader,并使用此ClassLoader来加载此名称的类。JVM不允许ClassLoader直接卸载加载了的类,只有JVM本身才有权卸载。当ClassLoader对象没有引用时,此ClassLoader对象加载的类才会被卸载。
根据上面的描述,在实际的应用中,JVM类加载过程会抛出这样那样的异常,这些情况下掌握各种异常产生的原因是最为重要的,下面来看类加载方面的常见异常。
(1)ClassNotFoundException
(2)NoClassDefFoundError
(3) LinkageError
(4)ClassCastException
3.类执行机制在完成将class文件信息加载到JVM并产生Class对象后,就可执行Class对象的静态方法或实例化对象进行调用了。在源码编译阶段将源码编译为JVM字节码,JVM字节码是一种中间代码的方式,要由JVM在运行期对其进行解释并执行,这种方式称为字节码解释执行方式。
字节码解释执行
由于采用的为中间码的方式,JVM有一套自己的指令,对于面向对象的语言而言,最重要的是执行方法的指令,JVM采用了invokestatic、invokevirtual、invokeinterface和invokespecial四个指令来执行不同的方法调用。invokestatic对应的是调用static方法,invokevirtual对应的是调用对象实例的方法,invokeinterface对应的是调用接口的方法,invokespecial对应的是调用private方法和编译源码后生成的<init>方法,此方法为对象实例化时的初始化方法,例如下面一段代码:
public class Demo{
public void execute(){
A.execute();
A a=new A();
a.bar();
IFoo b=new B();
b.bar();
}
}
class A{
public static int execute(){
return 1+2;
}
public int bar(){
return 1+2;
}
}
class B implements IFoo{
public int bar(){
return 1+2;
}
}
public interface IFoo{
public int bar();
}
通过javac编译上面的代码后,使用javap -c Demo查看其execute方法的字节码:
public void execute(); Code: 0: invokestatic #2; //Method A.execute:()I 3: pop 4: new #3; //class A 7: dup 8: invokespecial #4; //Method A."<init>":()V 11: astore_1 12: aload_1 13: invokevirtual #5; //Method A.bar:()I 16: pop 17: new #6; //class B 20: dup 21: invokespecial #7; //Method B."<init>":()V 24: astore_2 25: aload_2 26: invokeinterface #8, 1; //InterfaceMethod IFoo.bar:()I 31: pop 32: return
从以上例子可看到invokestatic、invokespecial、invokevirtual及invokeinterface四种指令对应调用方法的情况。
Sun JDK基于栈的体系结构来执行字节码,基于栈方式的好处为代码紧凑,体积小。
线程在创建后,都会产生程序计数器(PC)(或称为PC registers)和栈(Stack);PC存放了下一条要执行的指令在方法内的偏移量;栈中存放了栈帧(StackFrame),每个方法每次调用都会产生栈帧。栈帧主要分为局部变量区和操作数栈两部分,局部变量区用于存放方法中的局部变量和参数,操作数栈中用于存放方法执行过程中产生的中间结果,栈帧中还会有一些杂用空间,例如指向方法已解析的常量池的引用、其他一些VM内部实现需要的数据等,结构如图3.5所示。
PC寄存器--局部变量区,操作数栈(Stack Frame栈帧)
下面来看一个方法执行时过程的例子,代码如下:
public class Demo(){
public static void foo(){
int a=1;
int b=2;
int c=(a+b) * 5;
}
}
编译以上代码后,foo方法对应的字节码为以及相应的解释如下:
public static void foo(); Code: 0: iconst_1 //将类型为int、值为1的常量放入操作数栈; 1: istore_0 //将操作数栈中栈顶的值弹出放入局部变量区; 2: iconst_2 //将类型为int、值为2的常量放入操作数栈; 3: istore_1 //将操作数栈中栈顶的值弹出放入局部变量区; 4: iload_0 //装载局部变量区中的第一个值到操作数栈; 5: iload_1 //装载局部变量区中的第二个值到操作数栈; 6: iadd //执行int类型的add指令,并将计算出的结果放入操作数栈; 7: iconst_5 //将类型为int、值为5的常量放入操作数栈; 8: imul //执行int类型的mul指令,并将计算出的结果放入操作数栈; 9: istore_2 //将操作数栈中栈顶的值弹出放入局部变量区; 10: return // 返回
(1)指令解释执行
执行方式为获取下一条指令,解码并分派,然后执行
(2)栈顶缓存
在方法的执行过程中,有很多的操作要将值放入操作数栈,这回导致寄存器和内存要不断的交换数据,为此JDK采用了一个栈顶缓存,将本来位于操作数栈顶的值直接缓存到寄存器上,这对于需要一个值得操作而言,无须将数据放入操作数栈,可直接在寄存器计算,然后放回操作数栈。
(3)部分栈帧共享
当一个方法调用另一个方法时,通常传入另一个方法的参数为已存放在操作数栈的数据,JDK做了个优化,就是当调用方法时,后一方法可将前一个方法的操作数栈作为当前方法的局部变量,从而节省数据copy的消耗。
编译执行
解释执行的效率较低,为提升代码的执行性能,Sun JDK提供将字节码编译为机器码的支持,编译在运行时进行,通常称为JIT编译器。Sun JDK在执行过程中对执行频率高的代码进行编译,对执行不频繁的代码则继续采用解释的方式,因此Sun JDK又称为Hotspot VM,在编译上Sun JDK提供了两种模式:client compiler(-client)和servercompiler(-server)。
client compiler又称为C1 ,较为轻量级,只做少量性能开销比高的优化,它占用内存较少,适合于桌面交互式应用。在寄存器分配策略上,JDK 6以后采用的为线性扫描寄存器分配算法 ,在其他方面的优化主要有:方法内联、去虚拟化、冗余削除等。
1.方法内联
2.去虚拟化
3.冗余消除
反射执行
反射执行是Java的亮点之一,基于反射可动态调用某对象实例中对应的方法、访问查看对象的属性等,无需在编写代码时就确定要创建的对象。这使得Java可以很灵活地实现对象的调用,例如MVC框架中通常要调用实现类中的execute方法,但框架在编写时是无法知道实现类的。在Java中则可以通过反射机制直接去调用应用实现类中的execute方法,代码示例如下:
Class actionClass=Class.forName(外部实现类);
Method method=actionClass.getMethod("execute",null);
Object action=actionClass.newInstance();
method.invoke(action,null);
这种方式对于框架之类的代码而言非常重要,反射和直接创建对象实例,调用方法的最大不同在于创建的过程、方法调用的过程是动态的。这也使得采用反射生成执行方法调用的代码并不像直接调用实例对象代码,编译后就可直接生成对对象方法调用的字节码,而是只能生成调用JVM反射实现的字节码了。
要实现动态的调用,最直接的方法就是动态生成字节码,并加载到JVM中执行,Sun JDK采用的即为这种方法,来看看在Sun JDK中以上反射代码的关键执行过程。
Class actionClass=Class.forName(外部实现类);
调用本地方法,使用调用者所在的ClassLoader来加载创建出的Class对象;
Method method=actionClass.getMethod("execute",null);
校验Class是否为public类型,以确定类的执行权限,如不是public类型的,则直接抛出SecurityException。
调用privateGetDeclaredMethods来获取Class中的所有方法,在privateGetDeclaredMethods对Class中所有方法集合做了缓存,第一次会调用本地方法去获取。
扫描方法集合列表中是否有相同方法名及参数类型的方法,如果有,则复制生成一个新的Method对象返回;如果没有,则继续扫描父类、父接口中是否有该方法;如果仍然没找到方法,则抛出NoSuchMethodException,代码如下:
Object action=actionClass.newInstance();
校验Class是否为public类型,如果权限不足,则直接抛出SecurityException。
如果没有缓存的构造器对象,则调用本地方法获取构造器,并复制生成一个新的构造器对象,放入缓存;如果没有空构造器,则抛出InstantiationException。
校验构造器对象的权限。
执行构造器对象的newInstance方法。
判断构造器对象的newInstance方法是否有缓存的ConstructorAccessor对象,如果没有,则调用sun.reflect.ReflectionFactory生成新的ConstructorAccessor对象。
判断sun.reflect.ReflectionFactory是否需要调用本地代码,可通过sun.reflect.noInflation=true来设置为不调用本地代码。在不调用本地代码的情况下,可转交给MethodAccessorGenerator来处理。本地代码调用的情况在此不进行阐述。
MethodAccessorGenerator中的generate方法根据Java Class格式规范生成字节码,字节码中包括ConstructorAccessor对象需要的newInstance方法。该newInstance方法对应的指令为invokespecial,所需参数则从外部压入,生成的Constructor类的名字以sun/reflect/ GeneratedSerializationConstructorAccessor或sun/reflect/GeneratedConstructorAccessor开头,后面跟随一个累计创建对象的次数。
在生成字节码后将其加载到当前的ClassLoader中,并实例化,完成ConstructorAccessor对象的创建过程,并将此对象放入构造器对象的缓存中。
执行获取的constructorAccessor.newInstance,这步和标准的方法调用没有任何区别。
method.invoke(action,null);
这步的执行过程和上一步基本类似,只是在生成字节码时方法改为了invoke,其调用目标改为了传入对象的方法,同时类名改为了:sun/reflect/GeneratedMethodAccessor。
综上所述,执行一段反射执行的代码后,在debug里查看Method对象中的MethodAccessor对象引用(参数为-Dsun.reflect.noInflation=true,否则要默认执行15次反射调用后才能动态生成字节码),如图3.6所示:Sun JDK采用以上方式提供反射的实现,提升代码编写的灵活性,但也可以看出,其整个过程比直接编译成字节码的调用复杂很多,因此性能比直接执行的慢一些。Sun JDK中反射执行的性能会随着JDK版本的提升越来越好,到JDK 6后差距就不大了,但要注意的是,getMethod相对比较耗性能,一方面是权限的校验,另一方面是所有方法的扫描及Method对象的复制,因此在使用反射调用多的系统中应缓存getMethod返回的Method对象,而method.invoke的性能则仅比直接调用低一点。一段对比直接执行、反射执行性能的程序如下所示:
// Server OSR编译阈值:10700
private static final int WARMUP_COUNT=10700;
private ForReflection testClass=new ForReflection();
private static Method method=null;
public static void main(String[] args) throws Exception{
method=ForReflection.class.getMethod
("execute",new Class<?>[]{String.class});
Demo demo=new Demo();
// 保证反射能生成字节码及相关的测试代码能够被JIT编译
for (int i = 0; i < 20; i++) {
demo.testDirectCall();
demo.testCacheMethodCall();
demo.testNoCacheMethodCall();
}
long beginTime=System.currentTimeMillis();
demo.testDirectCall();
long endTime=System.currentTimeMillis();
System.out.println("直接调用消耗的时间为:"+
(endTime-beginTime)+"毫秒");
beginTime=System.currentTimeMillis();
demo.testNoCacheMethodCall();
endTime=System.currentTimeMillis();
System.out.println("不缓存Method,反射调用消耗的时间为:
"+(endTime-beginTime)+"毫秒");
beginTime=System.currentTimeMillis();
demo.testCacheMethodCall();
endTime=System.currentTimeMillis();
System.out.println("缓存Method,反射调用
消耗的时间为:"+(endTime-beginTime)+"毫秒");
}
public void testDirectCall(){
for (int i = 0; i < WARMUP_COUNT; i++) {
testClass.execute("hello");
}
}
public void testCacheMethodCall() throws Exception{
for (int i = 0; i < WARMUP_COUNT; i++) {
method.invoke(testClass, new Object[]{"hello"});
}
}
public void testNoCacheMethodCall() throws Exception{
for (int i = 0; i < WARMUP_COUNT; i++) {
Method testMethod=ForReflection.class.
getMethod("execute",new Class<?>[]{String.class});
testMethod.invoke(testClass, new Object[]{"hello"});
}
}
public class ForReflection {
private Map<String, String> caches=new
HashMap<String, String>();
public void execute(String message){
String b=this.toString()+message;
caches.put(b, message);
}
}
执行后显示的性能如下(执行环境: Intel Duo CPU E8400 3G, windows 7, Sun JDK 1.6.0_18,启动参数为-server -Xms128M -Xmx128M):
直接调用消耗的时间为5毫秒;
不缓存Method,反射调用消耗的时间为11毫秒;
缓存Method,反射调用消耗的时间为6毫秒。
在启动参数上增加-Xint来禁止JIT编译,执行上面代码,结果为:
直接调用消耗的时间为133毫秒;
不缓存Method,反射调用消耗的时间为215毫秒;
缓存Method,反射调用消耗的时间为150毫秒。
对比这段测试结果也可看出,C2编译后代码的执行速度得到了大幅提升。
(选自林昊先生的著作《分布式Java应用基础与实践》)