基本Kmeans算法介绍及其实现
申明:本文非逼着原创,原文转载自:http://blog.csdn.net/qll125596718/article/details/8243404
1.基本Kmeans算法[1]
- 选择K个点作为初始质心
- repeat
- 将每个点指派到最近的质心,形成K个簇
- 重新计算每个簇的质心
- until 簇不发生变化或达到最大迭代次数
空间复杂度:O((m+K)n),其中,K为簇的数目,m为记录数,n为维数
2.注意问题
(1)K如何确定
kmenas算法首先选择K个初始质心,其中K是用户指定的参数,即所期望的簇的个数。这样做的前提是我们已经知道数据集中包含多少个簇,但很多情况下,我们并不知道数据的分布情况,实际上聚类就是我们发现数据分布的一种手段,这就陷入了鸡和蛋的矛盾。如何有效的确定K值,这里大致提供几种方法,若各位有更好的方法,欢迎探讨。
1.与层次聚类结合[2]
经常会产生较好的聚类结果的一个有趣策略是,首先采用层次凝聚算法决定结果粗的数目,并找到一个初始聚类,然后用迭代重定位来改进该聚类。
2.稳定性方法[3]
稳定性方法对一个数据集进行2次重采样产生2个数据子集,再用相同的聚类算法对2个数据子集进行聚类,产生2个具有k个聚类的聚类结果,计算2个聚类结果的相似度的分布情况。2个聚类结果具有高的相似度说明k个聚类反映了稳定的聚类结构,其相似度可以用来估计聚类个数。采用次方法试探多个k,找到合适的k值。
3.系统演化方法[3]
系统演化方法将一个数据集视为伪热力学系统,当数据集被划分为K个聚类时称系统处于状态K。系统由初始状态K=1出发,经过分裂过程和合并过程,系统将演化到它的稳定平衡状态Ki,其所对应的聚类结构决定了最优类数Ki。系统演化方法能提供关于所有聚类之间的相对边界距离或可分程度,它适用于明显分离的聚类结构和轻微重叠的聚类结构。
4.使用canopy算法进行初始划分[4]
基于Canopy Method的聚类算法将聚类过程分为两个阶段
Stage1、聚类最耗费计算的地方是计算对象相似性的时候,Canopy Method在第一阶段选择简单、计算代价较低的方法计算对象相似性,将相似的对象放在一个子集中,这个子集被叫做Canopy ,通过一系列计算得到若干Canopy,Canopy之间可以是重叠的,但不会存在某个对象不属于任何Canopy的情况,可以把这一阶段看做数据预处理;
Stage2、在各个Canopy 内使用传统的聚类方法(如K-means),不属于同一Canopy 的对象之间不进行相似性计算。
从这个方法起码可以看出两点好处:首先,Canopy 不要太大且Canopy 之间重叠的不要太多的话会大大减少后续需要计算相似性的对象的个数;其次,类似于K-means这样的聚类方法是需要人为指出K的值的,通过Stage1得到的Canopy 个数完全可以作为这个K值,一定程度上减少了选择K的盲目性。
其他方法如贝叶斯信息准则方法(BIC)可参看文献[5]。
(2)初始质心的选取
(3)距离的度量
(4)质心的计算
(5)算法停止条件

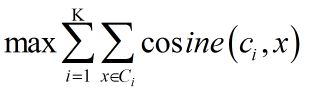
(6)空聚类的处理
3.适用范围及缺陷
4.实现
- #include <iostream>
- #include <sstream>
- #include <fstream>
- #include <vector>
- #include <math.h>
- #include <stdlib.h>
- #define k 3//簇的数目
- using namespace std;
- //存放元组的属性信息
- typedef vector<double> Tuple;//存储每条数据记录
- int dataNum;//数据集中数据记录数目
- int dimNum;//每条记录的维数
- //计算两个元组间的欧几里距离
- double getDistXY(const Tuple& t1, const Tuple& t2)
- {
- double sum = 0;
- for(int i=1; i<=dimNum; ++i)
- {
- sum += (t1[i]-t2[i]) * (t1[i]-t2[i]);
- }
- return sqrt(sum);
- }
- //根据质心,决定当前元组属于哪个簇
- int clusterOfTuple(Tuple means[],const Tuple& tuple){
- double dist=getDistXY(means[0],tuple);
- double tmp;
- int label=0;//标示属于哪一个簇
- for(int i=1;i<k;i++){
- tmp=getDistXY(means[i],tuple);
- if(tmp<dist) {dist=tmp;label=i;}
- }
- return label;
- }
- //获得给定簇集的平方误差
- double getVar(vector<Tuple> clusters[],Tuple means[]){
- double var = 0;
- for (int i = 0; i < k; i++)
- {
- vector<Tuple> t = clusters[i];
- for (int j = 0; j< t.size(); j++)
- {
- var += getDistXY(t[j],means[i]);
- }
- }
- //cout<<"sum:"<<sum<<endl;
- return var;
- }
- //获得当前簇的均值(质心)
- Tuple getMeans(const vector<Tuple>& cluster){
- int num = cluster.size();
- Tuple t(dimNum+1, 0);
- for (int i = 0; i < num; i++)
- {
- for(int j=1; j<=dimNum; ++j)
- {
- t[j] += cluster[i][j];
- }
- }
- for(int j=1; j<=dimNum; ++j)
- t[j] /= num;
- return t;
- //cout<<"sum:"<<sum<<endl;
- }
- void print(const vector<Tuple> clusters[])
- {
- for(int lable=0; lable<k; lable++)
- {
- cout<<"第"<<lable+1<<"个簇:"<<endl;
- vector<Tuple> t = clusters[lable];
- for(int i=0; i<t.size(); i++)
- {
- cout<<i+1<<".(";
- for(int j=0; j<=dimNum; ++j)
- {
- cout<<t[i][j]<<", ";
- }
- cout<<")\n";
- }
- }
- }
- void KMeans(vector<Tuple>& tuples){
- vector<Tuple> clusters[k];//k个簇
- Tuple means[k];//k个中心点
- int i=0;
- //一开始随机选取k条记录的值作为k个簇的质心(均值)
- srand((unsigned int)time(NULL));
- for(i=0;i<k;){
- int iToSelect = rand()%tuples.size();
- if(means[iToSelect].size() == 0)
- {
- for(int j=0; j<=dimNum; ++j)
- {
- means[i].push_back(tuples[iToSelect][j]);
- }
- ++i;
- }
- }
- int lable=0;
- //根据默认的质心给簇赋值
- for(i=0;i!=tuples.size();++i){
- lable=clusterOfTuple(means,tuples[i]);
- clusters[lable].push_back(tuples[i]);
- }
- double oldVar=-1;
- double newVar=getVar(clusters,means);
- cout<<"初始的的整体误差平方和为:"<<newVar<<endl;
- int t = 0;
- while(abs(newVar - oldVar) >= 1) //当新旧函数值相差不到1即准则函数值不发生明显变化时,算法终止
- {
- cout<<"第 "<<++t<<" 次迭代开始:"<<endl;
- for (i = 0; i < k; i++) //更新每个簇的中心点
- {
- means[i] = getMeans(clusters[i]);
- }
- oldVar = newVar;
- newVar = getVar(clusters,means); //计算新的准则函数值
- for (i = 0; i < k; i++) //清空每个簇
- {
- clusters[i].clear();
- }
- //根据新的质心获得新的簇
- for(i=0; i!=tuples.size(); ++i){
- lable=clusterOfTuple(means,tuples[i]);
- clusters[lable].push_back(tuples[i]);
- }
- cout<<"此次迭代之后的整体误差平方和为:"<<newVar<<endl;
- }
- cout<<"The result is:\n";
- print(clusters);
- }
- int main(){
- char fname[256];
- cout<<"请输入存放数据的文件名: ";
- cin>>fname;
- cout<<endl<<" 请依次输入: 维数 样本数目"<<endl;
- cout<<endl<<" 维数dimNum: ";
- cin>>dimNum;
- cout<<endl<<" 样本数目dataNum: ";
- cin>>dataNum;
- ifstream infile(fname);
- if(!infile){
- cout<<"不能打开输入的文件"<<fname<<endl;
- return 0;
- }
- vector<Tuple> tuples;
- //从文件流中读入数据
- for(int i=0; i<dataNum && !infile.eof(); ++i)
- {
- string str;
- getline(infile, str);
- istringstream istr(str);
- Tuple tuple(dimNum+1, 0);//第一个位置存放记录编号,第2到dimNum+1个位置存放实际元素
- tuple[0] = i+1;
- for(int j=1; j<=dimNum; ++j)
- {
- istr>>tuple[j];
- }
- tuples.push_back(tuple);
- }
- cout<<endl<<"开始聚类"<<endl;
- KMeans(tuples);
- return 0;
- }
这里是随机选取的初始质心,以鸢尾花的数据集为例,原数据集中1-50为一个簇,51-100为第二个簇,101到150为第三个簇:
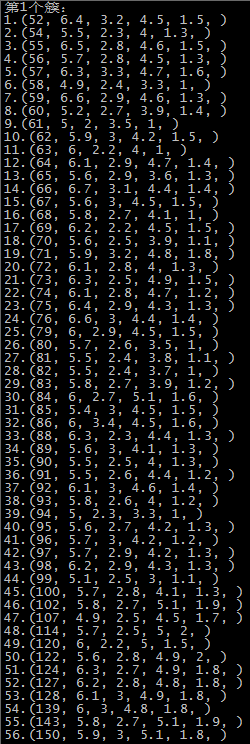
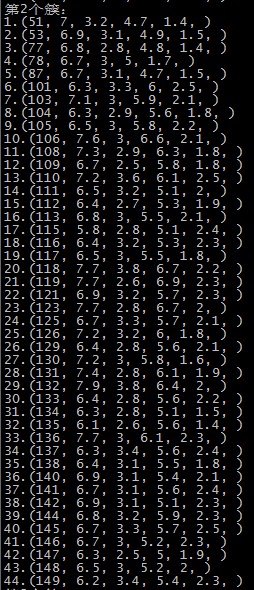
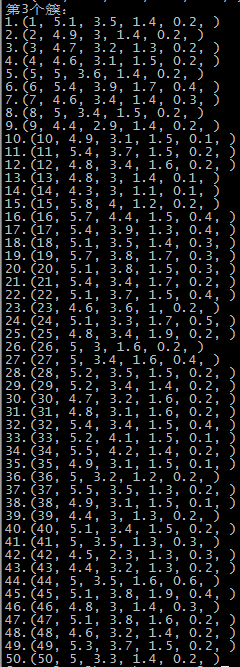
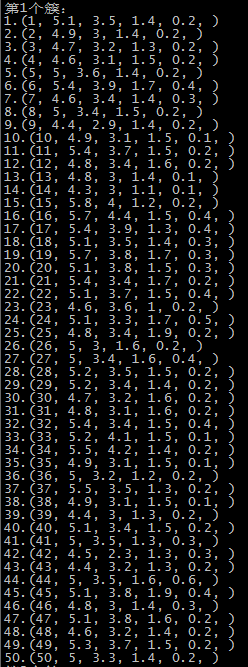
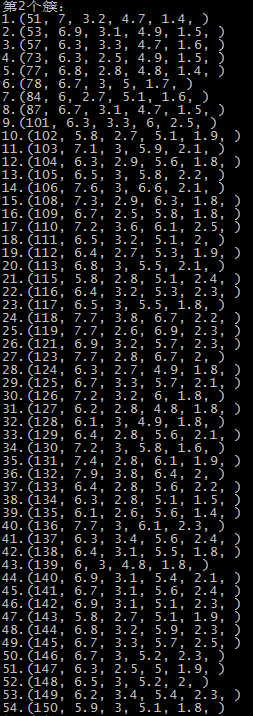
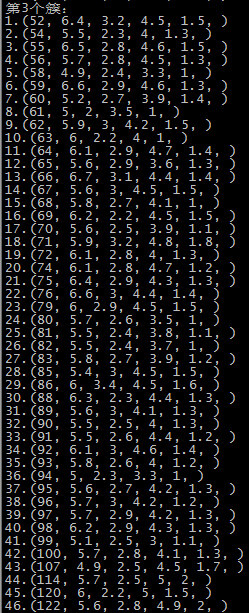
第二次运行结果 SSE=98.1404
。。。
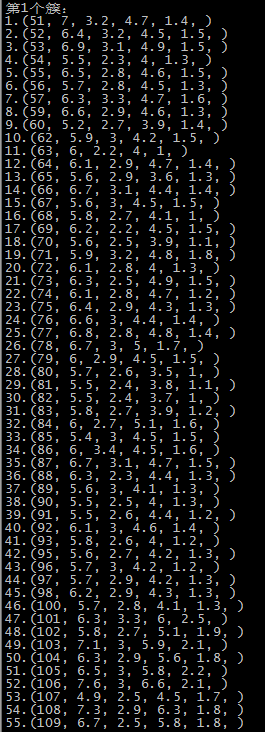
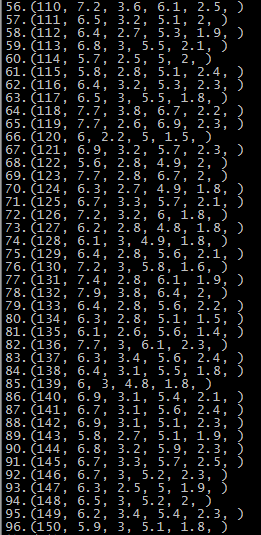
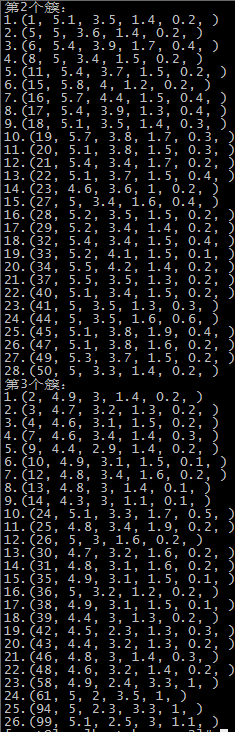
第五次运行结果 SSE=123.397
由于初始质心是随机选取的,前两次还算正常,运行到第五次时,第一个簇基本包括了后51-150个记录,第二个簇和第三个簇包含了第1-50个记录,可能的原因就是随机选择初始点时,有两个初始点都选在了1-50个记录中。
参考:
[1]Pang-Ning Tan等著,《数据挖掘导论》,2011
[2]Jiawei Han等著,《数据挖掘概念与技术》,2008
[3]聚类分析中类数估计方法的实验比较
[4]http://www.cnblogs.com/vivounicorn/archive/2011/09/23/2186483.html
[5]一种基于贝叶斯信息准则的k均值聚类方法
[6]http://www.zhihu.com/question/19640394?nr=1¬i_id=8736954