【算法导论】贪心算法之赫夫曼编码
概述
讨论赫夫曼编码问题,赫夫曼编码的思想就是变长编码。变长编码就是让字符表中出现概率高的字符的编码长度尽可能小,而出现概率高的字符的编码长度相对较长。然后还要遵循前缀码的要求,就是任意一个编码都不是其他编码的前缀码,这样方便解码。
思路及实现
对于下表中的字符和相应的出现概率,有对应图中的编码树:

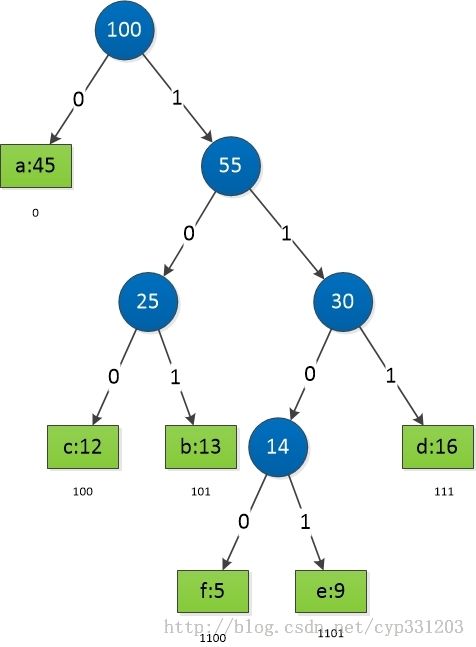
可以比较容易的看出来,每个叶节点就代表一个字符,从根节点到叶节点走过的路径拼接起来,就代表这个字符的编码,比如f是1100,e是1101,而f和e是深度最深的节点也是概率最小的两个节点。这也就是我们要求的赫夫曼编码形式。这种最优的编码形式,总是一颗满的二叉树。
算导上有大量的篇幅来论证用贪心算法,每次选择概率最小的两个节点来,可以完成赫夫曼编码。这里只说实现方法。
由于每次都要找出出现概率最小的那个节点,弹出来,并删掉,所以我们可以使用最小优先队列来做。注意一点是,编码树的叶子节点个数等于字符的个数,而内部节点个数则等于字符的个数减去一,所以求内部节点的循环只需要n-1次即可,n为字符数。
小根堆操作:
#include <iostream>
#include <stack>
using namespace std;
#define MAX_INDEX 11
struct node {
int freq;
node* left;
node* right;
node() :
freq(), left(NULL), right(NULL) {
}
};
//数组从1号元素开始算起
int left_child(int i) {
return i * 2;
}
int right_child(int i) {
return i * 2 + 1;
}
int parent(int child) {
return child / 2;
}
void swap(node* a, node* b) {
node tmp = *a;
*a = *b;
*b = tmp;
}
void Print_Heap(node* a, int len) {
for (int i = 1; i < len; i++) {
cout << a[i].freq << ' ';
}
cout << endl;
}
/*
* 将一个左右子树都是小根堆的堆转化成小根堆
*/
void Min_Heapify(node heap[], int root, int n) {
int l = left_child(root);
int r = right_child(root);
int min = root;
if (l <= n && heap[min].freq > heap[l].freq) {
min = l;
}
if (r <= n && heap[min].freq > heap[r].freq) {
min = r;
}
if (min != root) {
swap(heap + root, heap + min);
Min_Heapify(heap, min, n);
}
}
/*
* 构建一个小根堆
*/
void Build_min_heap(node heap[], int n) {
int idx = n / 2 + 1;
for (int i = idx; i >= 1; i--) {
Min_Heapify(heap, i, n);
}
}
最小优先队列操作:
/*
* 最小优先队列要实现的操作:
*
* ①INSERT(S,x)
*
* ②MINIMUM(S)
*
* ③EXTRACT_MIN(S)
*
* ④DECREASE_KEY(S,x,k)
*
*/
/*
* 最小优先队列
*/
struct min_priority_queue {
node* min_heap;
int len;
min_priority_queue(node* mh, int l) :
min_heap(mh), len(l) {
}
};
/*
* 返回最小元素
*/
node* HEAP_MINIMUM(min_priority_queue* mpq) {
if (mpq->len < 1) {
cout << "min_priority_queue underflow" << endl;
}
return mpq->min_heap + 1;
}
/*
* 弹出并移除最小的元素
*/
node* HEAP_EXTRACT_MIN(min_priority_queue* mpq) {
if (mpq->len < 1) {
cout << "min_priority_queue underflow" << endl;
}
//这里必须要新建一个节点返回去,如果直接返回原节点,则会导致后面insert的时候,左右孩子的指针指向的内容发生变化
//新建一个节点
node* min = new node();
//复制最小节点的内容到新建节点,最后将新建的节点的指针返回
*min = *(mpq->min_heap + 1);
swap(mpq->min_heap + 1, mpq->min_heap + mpq->len);
//删除弹出的节点,防止内存泄露
delete (mpq->min_heap + mpq->len);
//将最后一个节点从堆中去掉
(mpq->len)--;
//重新维护小根堆的性质
Min_Heapify(mpq->min_heap, 1, mpq->len);
//返回min
return min;
}
/*
* 把优先队列中原来为x的元素的值,换成k,并维护最小堆的性质
*/
void HEAP_DECREASE_KEY(min_priority_queue* mpq, int i, node* n) {
if (mpq->min_heap[i].freq < n->freq) {
cout << "error:要替换的值比原值要大" << endl;
return;
}
mpq->min_heap[i].freq = n->freq;
while (i >= 1 && mpq->min_heap[i].freq < mpq->min_heap[parent(i)].freq) {
swap(mpq->min_heap + i, mpq->min_heap + parent(i));
i = parent(i);
}
}
/*
* 插入元素
*/
void HEAP_INSERT(min_priority_queue* mpq, node* n) {
(mpq->len)++;
*(mpq->min_heap + mpq->len) = *n;
HEAP_DECREASE_KEY(mpq, mpq->len, n);
}
/*
* 打印节点数组
*/
void PRINT_NODE_ARRAY(node* n_arr, int max_index) {
for (int i = 1; i <= max_index; i++) {
cout << n_arr[i].freq << ' ';
}
cout << endl;
}
赫夫曼编码形成编码树:
//哈夫曼编码树
struct Huffman_Tree
{
node *root;
Huffman_Tree():root(NULL){}
};
/*
* 赫夫曼编码,返回编码树的头结点
*/
void HUFFMAN(min_priority_queue* mpq,Huffman_Tree* T) {
int n = mpq->len;
Build_min_heap(mpq->min_heap, n);
node* tmp = NULL;
//内部节点有n-1个,所以进行n-1次循环,每一个tmp都是一个内部节点,形成之后,再将tmp入堆,继续循环
for (int i = 1; i <= n - 1; i++) {
tmp = new node();
tmp->left = HEAP_EXTRACT_MIN(mpq);
tmp->right = HEAP_EXTRACT_MIN(mpq);
tmp->freq = tmp->left->freq + tmp->right->freq;
HEAP_INSERT(mpq, tmp);
}
// return HEAP_EXTRACT_MIN(mpq);
T->root=HEAP_EXTRACT_MIN(mpq);
}
/*
* 中序遍历编码树
*/
void PRINT_CODED_TREE(node* root) {
if (root != NULL) {
PRINT_CODED_TREE(root->left);
cout << root->freq << ' ';
PRINT_CODED_TREE(root->right);
}
}
/*
* 删除编码树的节点
*/
void DELETE_CODED_TREE(node* root) {
if (root != NULL) {
DELETE_CODED_TREE(root->left);
node* tmp = root->right;
delete root;
root = NULL;
DELETE_CODED_TREE(tmp);
}
}
int main() {
int freq_arr[MAX_INDEX + 1] = { 0, 10, 4, 8, 20, 7, 6, 3, 11, 1, 5, 25 };
node node_arr[MAX_INDEX + 1];
for (int i = 0; i < 12; i++) {
node_arr[i].freq = freq_arr[i];
}
//新建一个最小优先队列对象,应用上面的数组
min_priority_queue* mpq = new min_priority_queue(node_arr, MAX_INDEX);
Huffman_Tree* T = new Huffman_Tree();
HUFFMAN(mpq,T);
PRINT_CODED_TREE(T->root); //10个内部节点和原来的11个叶子节点,一共21个节点
DELETE_CODED_TREE(T->root);
return 0;
}
复杂度分析
形成小根堆耗时O(n),而在HUFFMAN(min_priority_queue* mpq,Huffman_Tree* T)中的n-1次for循环,每次for 都要做常数次维护小根堆性质的操作,每次的复杂度为O(lgn),所以总共是:O(n+n*lgn)=O(nlgn)。