Mahout并行频繁集挖掘算法源码分析(1)--实战
Mahout版本:0.7,hadoop版本:1.0.4,jdk:1.7.0_25 64bit。
本系列分析Parallel Frequent Pattern Mining源码,本篇作为第一篇,首先进行实战,实战参考mahout官网内容。这里主要是测试sequential和mapreduce模式下对数据处理的耗时分析,使用数据为:retail.dat,前面几条数据如下:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 38 39 47 48 38 39 48 49 50 51 52 53 54 55 56 57 58Parallel Frequent Pattern Mining 主程序对应的源代码是org.apache.mahout.fpm.pfpgrowth.FPGrowthDriver。直接空参数或者使用-h参数调用FPGrowthDriver类,得到下面的算法调用参数:
usage: <command> [Generic Options] [Job-Specific Options]
Generic Options:
-archives <paths> comma separated archives to be unarchived
on the compute machines.
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-files <paths> comma separated files to be copied to the
map reduce cluster
-fs <local|namenode:port> specify a namenode
-jt <local|jobtracker:port> specify a job tracker
-libjars <paths> comma separated jar files to include in
the classpath.
-tokenCacheFile <tokensFile> name of the file with the tokens
Job-Specific Options:
--input (-i) input Path to job input
directory.
--output (-o) output The directory pathname for
output.
--minSupport (-s) minSupport (Optional) The minimum
number of times a
co-occurrence must be
present. Default Value: 3
--maxHeapSize (-k) maxHeapSize (Optional) Maximum Heap
Size k, to denote the
requirement to mine top K
items. Default value: 50
--numGroups (-g) numGroups (Optional) Number of
groups the features should
be divided in the
map-reduce version.
Doesn't work in sequential
version Default Value:1000
--splitterPattern (-regex) splitterPattern Regular Expression pattern
used to split given string
transaction into itemsets.
Default value splits comma
separated itemsets.
Default Value: "[
,\t]*[,|\t][ ,\t]*"
--numTreeCacheEntries (-tc) numTreeCacheEntries (Optional) Number of
entries in the tree cache
to prevent duplicate tree
building. (Warning) a
first level conditional
FP-Tree might consume a
lot of memory, so keep
this value small, but big
enough to prevent
duplicate tree building.
Default Value:5
Recommended Values: [5-10]
--method (-method) method Method of processing:
sequential|mapreduce
--encoding (-e) encoding (Optional) The file
encoding. Default value:
UTF-8
--useFPG2 (-2) Use an alternate FPG
implementation
--help (-h) Print out help
--tempDir tempDir Intermediate output
directory
--startPhase startPhase First phase to run
--endPhase endPhase Last phase to run其实,这里关心的也只是输入、输出、最小支持度、分组的个数(如果是mapreduce模式的话)而已,其他参数暂时考虑不到。
本来是打算直接在java里面直接调用的(改了mahout的源码,然后上传到hadoop-core-job.jar也是没用),而不是使用命令行调用该算法。但是调用的时候遇到了点问题,说没有权限,大概浏览了一下算法源码,发现Configuration每次都新建了一个,那我传进去的不是没有用了?晕,但是在运行sequential的时候老是提示找不到输入路径,我还以为是啥问题。没办法只有终端运行了,结果还是出错,找不到路径?明明有的,好吧:
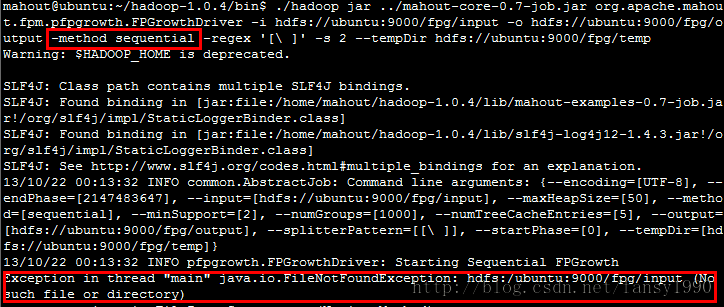
但是我把sequential改为mapreduce,然后就可以运行了:
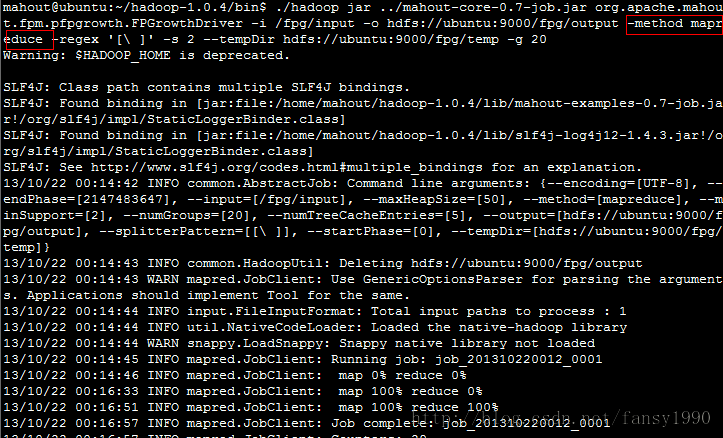
然后是算法的结束时间:

这样计算时间应该是:206秒,官网上面说102秒就可以跑完了,估计是我的内存设置比较小;sequential模式的601秒暂时试验不了 了。看下次有空的话在分析为啥sequential的输入文件不存在问题,估计还是和configuration有关。没时间的话就直接分析这个算法的mapreduce模式,不再分析sequential了。
ps:这个算法以前分析过,这次希望能系统的分析下,应该会比较快。
分享,成长,快乐
转载请注明blog地址:http://blog.csdn.net/fansy1990