Nutch加Hadoop集群搭建
1、Apache Nutch
Apache Nutch是一个用于网络搜索的开源框架,它提供了我们运行自己的搜索引擎所需的全部工具,包括全文搜索和Web爬虫。
1.1、Nutch的组件结构
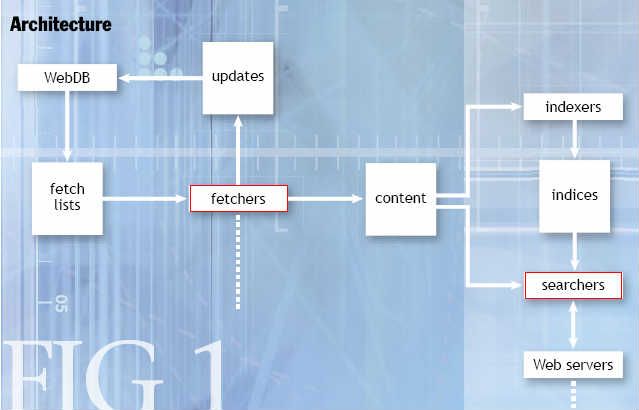
WebDB:存储网页数据和连接信息
Fetch lists:将WebDB所存储的连接分成多个组,来用于分布式检索
Fetchers:检索Fetch list中的内容并下载到本地,共有两项输出:分别是连接的update
信息和内容content
Updates:更新WebDB的页面检索状态
WebDB、updates、fetch lists和fetchers组成循环结构,不断运行下去,来确保所得到的Web镜像是最新的
Content:界面内容,获取内容之后,Nutch便可以根据它来创建索引并执行查询操作
Indexers:对目标Content创建索引,当索引内容较大时,可把索引划分成多个索引片段,然后分配给不同的seracher实现并行检索
Searchers:实现查询功能的同时也会缓存content
Webservers:有两种角色:
1处理用户的交互请求(Nutch Search Client)
2从searchers中获取查询结果(HTTP Server)注:fetchers和searchers两个节点所对应的操作可放到分布式环境(hadoop)中去完成
创建索引及查询的操作可通过solr框架来实现
1.2、Nutch的数据结构:
Nutch数据包含3个目录结构,分别是:
1、Crawldb:用于存储Nutch将要检索的url信息,以及检索状态(是否检索、何时检索)
2、Linkdb:用于存储每一个url所包含的超链接信息(包括锚点)
3、Segments:一组url的集合,他们作为一个检索单元,可用于分布式检索
Segment目录包含以下子目录信息:
(1) crawl_generate:定义将要检索的url集合(文件类型为SequenceFile)
(2) crawl_fetch:存储每一个url的检索状态(文件类型为MapFile)
(3) content:存储每一个url所对应的二进制字节流(文件类型为MapFile)
(4) parse_text:存储每一个url所解析出的文本内容(文件类型为MapFile)
(5) parse_data:存储每一个url所解析出的元数据(文件类型为MapFile)
(6) crawl_parse:用于及时更新crawldb中的内容(如要检索的url已不存在等情况)--文件类型为SequenceFile
注:结合Nutch的数据结构和组件结构来看,crawldb相当于WebDB,而segment相当于是fetchlists.
分布式crawl过程中,每个MapReduce Job都会生成一个segment,名称以时间来命名
2、Apache Hadoop
Nutch的单机采集(local方式)并不复杂,然而当所采集的数据源较大时,一台机器难以满足性能上的需求,因此通常的做法是将Nutch集成到Hadoop环境中以完成分布式采集和分布式查询的效果(deploy方式)。
Hadoop框架在功能划分上包含3个子框架,分别是:
MapReduce:用于分布式并行计算
HDFS:用于分布式存储
Common:封装HDFS和MapReduce所需要的实用类
2.1、MapReduce工作流程

1.将输入源(Inputfiles)切割成不同的片段,每个片段的大小通常在16M-64M之间(可通过参数配置),然后启动云端程序。
2.MapReduce程序基于master/slaves方式部署,在云端机器中选中一台机器运行master程序,职责包括:调度任务分配给slaves,监听任务的执行情况。
3.在图形中,slave的体现形式为worker,当worker接到Map任务时,会读取输入源片段,从中解析出Key/Value键值对,并作为参数传递到用户自定义的Map功能函数之中,Map功能函数的输出值同样为Key/Value键值对,这些键值对会临时缓存在内存里面。
4.缓存之后,程序会定期将缓存的键值对写入本地硬盘(执行如图所示的local write操作),并且把存储地址传回给master,以便master记录它们的位置用以执行Reduce操作。
5.当worker被通知执行Reduce操作时,master会把相应的Map输出数据所存储的地址也发送给该worker,以便其通过远程调用来获取这些数据。得到这些数据之后,reduce worker会把具有相同Key值的记录组织到一起来达到排序的效果。
6.Reduce Worker会把排序后的数据作为参数传递到用户自定义的Reduce功能函数之中,而函数的输出结果会持久化存储到output file中去。
7.当所有的Map任务和Reduce任务结束之后,Master会重新唤醒用户主程序,至此,一次MapReduce操作调用完成。
2.2、HDFS组件结构
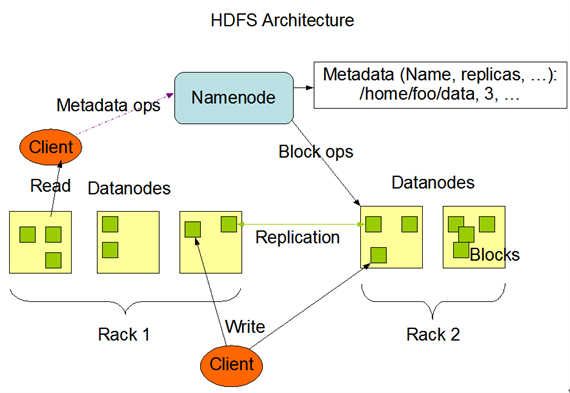
同MapReduce部署结构类似,HDFS同样具备master/slaves主仆结构
1.如图所示中,NameNode充当master角色,职责包括:管理文档系统的命名空间(namespace);调节客户端访问到需要的文件(存储在DateNode中的文件)
注:namespace—映射文件系统的目录结构
2.DataNodes充当slaves角色,通常情况下,一台机器只部署一个Datenode,用来存储MapReduce程序需要的数据
Namenode会定期从DataNodes那里收到Heartbeat和Blockreport反馈
Heartbeat反馈用来确保DataNode没有出现功能异常;
Blockreport包含DataNode所存储的Block集合
2.3、hadoop资源
1 http://wiki.apache.org/nutch/NutchHadoopTutorial基于Nutch和Hadoop完成分布式采集和分布式查询
3、环境搭建
3.1、需要准备
3.1.1两台或以上Linux机器(这里假定为两台)
一台机器名称设置为master,另一台设置为slave01,两台机器具有相同的登录用户名nutch,并且将两台机器的etc/hosts文件设置成相同的内容,如:
192.168.7.11 master
192.168.7.12 slave01
……
这样,便可以通过主机名找到对应的机器
3.1.2搭建ssh环境
ssh的安装可通过如下命令完成:
$ sudo apt-get install ssh
$ sudo apt-get install rsync
3.1.3安装JDK
$ apt-get install openjdk-6-jdkopenjdk-6-jre
3.1.4下载最近版本的hadoop和nutch
下载地址:
Hadoop: http://www.apache.org/dyn/closer.cgi/hadoop/common/
Nutch: http://www.apache.org/dyn/closer.cgi/nutch/
3.2、搭建配置
3.2.1SSH登录配置
(1)在master机器上通过以下命令生成证书文件authorized_keys
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
(2)将证书文件复制到其他机器的用户主目录下
$scp /home/nutch/.ssh authorized_keys nutch@slave01:/home/nutch/.ssh/authorized_keys
通过以上两步操作,master机器便可以在不需要密码的情况下ssh到slave01机器上
3.2.2HADOOP配置
同ssh登录证书的配置类似,HADOOP配置同样是在master机器上完成,然后在复制到slave机器上,确保每一台机器的hadoop环境相同
$HADOOP_HOME/conf目录下:
(1)hadoop-env.sh文件
export HADOOP_HOME=/PATH/TO/HADOOP_HOME
export JAVA_HOME=/PATH/TO/JDK_HOME
export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
(2)core-site.xml文件
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
(3)hdfs-site.xml文件
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/nutch/filesystem/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/nutch/filesystem/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
(4)mapred-site.xml文件
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>2</value>
</property>
<property>
<name>mapred.reduce.tasks</name>
<value>2</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>/nutch/filesystem/mapreduce/system</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/nutch/filesystem/mapreduce/local</value>
</property>
</configuration>
(5)masters和slaves配置
将相应的机器IP加到对应的配置文件中去
3.2.3 Nutch配置
$NUTCH_HOME/conf目录下
(1)nutch-site.xml文件
<property>
<name>http.agent.name</name>
<value>Nutch Spider</value>
</property>
(2)regex-urlfilter.txt
添加需要检索的url
+^http://([a-z0-9]*\.)*nutch.apache.org/(3)将修改后的文件放到NUTCH_HOME/runtime/deploy/nutch-*.job中
3.3、启动运行
3.3.1 启动Hadoop
1.格式化namenode节点
bin/hadoop namenode –format
2.启动hadoop进程
bin/start-all.sh
启动成功后,可通过如下url查看NameNode和MapReduce运行状态
NameNode: http://master:50070/
MapReduce: http://master:50030/
3.向hdfs放入测试数据
$ bin/hadoop fs -put conf input
4.执行测试
$ bin/hadoop jar hadoop-examples-*.jar grep input output'dfs[a-z.]+'
5.关闭hadoop进程
bin/stop-all.sh
3.3.2 运行Nutch
1启动前提:
(1).hadoop已成功启动
(2).将HADOOP_HOME/bin路径添加到环境变量中,以便Nutch找到hadoop命令
通过修改/etc/enviroment配置文件实现
(3)在控制台执行export JAVA_HOME=/PATH/TO/JAVA命令
2向HDFS中存入待检索数据
$ bin/hadoop fs -put urldir urldir
注:第一个urldir为本地文件夹,存放了url数据文件,每行一个url
第二个urldir为HDFS的存储路径
3启动nutch命令
在NUTCH_HONE/runtime/deploy目录下执行以下命令
$ bin/nutch crawl urldir –dir crawl -depth 3 –topN 10
命令成功执行后,会在HDFS中生成crawl目录
注:一定要在deploy目录下执行该命令,在local目录下执行的是单机采集,而没有使用hadoop环境