机器学习技法总结(六)Decision Tree Hypothesis
这里先再次提出我们利用aggregation获取更好性能的Hypothesis G所涉及的方法:blending,就是在得到g_set之后进行融合;learning呢?就是在线online的获取g并融合。下面就是关于整个aggregation所涉及到的方法总结:

其中Bagging、AdaBoost我们都已经探讨,它们分别是基于uniform(voting / average)和non-uniform(linear)的aggregation type,那么下面就开始介绍一个基于conditional的learning model:decision tree(决策树)。
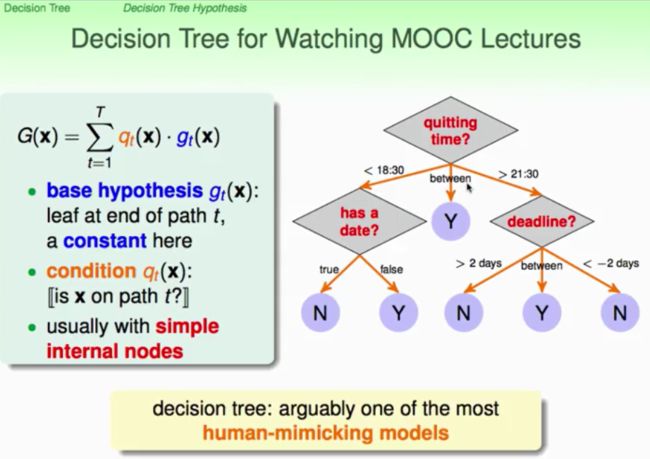
它实际上是模仿人类的决策过程,在C语言中很常见的if...else...语句就可以看作是非常简单的decision tree。看我们如何利用aggregation进行演进,如下图,我们希望internal nodes(内部的决策过程)都要非常简单。从入口处将状况进行分开为不同的branch,Gc(x)作为一个独立的Sub-Tree。就是把一颗大Tree,配合上分支条件,分拆为小点的树,实际上就是一个递归结构的定义。tree = (root, sub-trees),root根部告诉我们如何做branch。

另外对于Decision Tree有些好处和坏处,这里先给出,有一个大致的定位,如下图:
那么一个基本的decision tree演算法就应该如下:(采用递归的结构),所有的资料送入作出一个大的树,root,sub-tree,然后再对sub-tree进行分解,一直到sub-tree不能再分,就是碰到了叶子(leaf)后就逐级回传,最后合成大的decision tree。

一个典型的决策树:C&RT:classification and Regression Tree。1)将branch分支为2元树(binary tree);2)leaf级的hypothesis是g = Ein-optimal constant (常数);3)内部节点:就直接用decision stump;4)利用所有可能的decision stump来计算其纯度(purity),最大的purity作为最终的decision stump(branching by purifying)

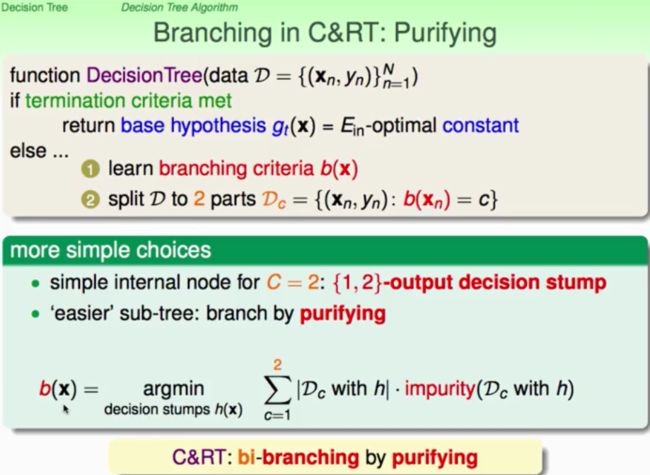
那么纯度的衡量都有哪些呢?

那么演算法什么时候停止呢?到所有的purity=1时,可以回传一个常数了;或者是所有的xn都一样时,也就说没有了decision stump了。这种是叫作强制停止,有个特点:叶子回传的是一个常数。

所以,基本的C&RT算法如下,可以很容易做多类分类。

如果我们将树叶覆盖所有的数据,那么Ein很有可能就变成0了,这样我们很可能出现overfitting的现象,那又该怎样做呢?对! regularization!:让叶子节点变得少,就有可能控制模型复杂度。但是我们找所有可能的 tree,这有可能非常多,计算量比较大,那么如果我们利用C&RT得到一个fully-grown tree之后,比如是10个叶子,我们可以依次去掉一片叶子来得到10个砍掉的树,这样来进行Regularization可能是有用的。如何选择lambda呢?

先讨论一下decision stump的输入特征都有哪些种,这将决定我们如何利用decision stump进行切割。如果是数字特征,那么很容易就是简单的decision stump,那么如果特征是categorical features时,可以利用decision subset进行处理。所以C&RT都可以处理。

如果有些特征丢失了,该怎么办呢?我们如果类比人的方法:就是类比,就是说,比如人的身高与体重有一定的关系,weight<50 == height < 150,就这样用替代的特征进行;所以C&RT能够处理丢失的特征;

最后举出一些例子来更加形象的了解Decision Tree这个模型的工作机制,跟AdaBoost-decision stump中的讲解类似,同样先从简单的例子入手:
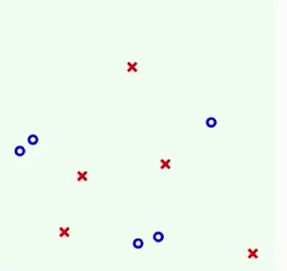
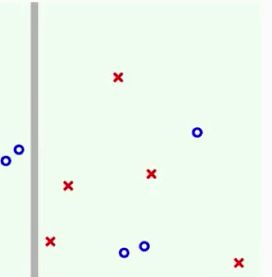
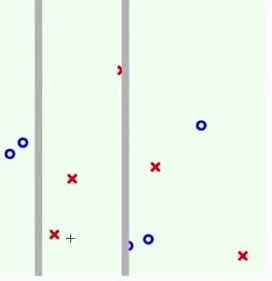
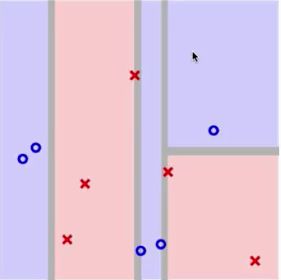
就是逐渐的递归地把树给展开。那么与AdaBoost有和差别呢?

可以很清楚的看到,Decision Tree是一种有condition的切割,而AdaBoost则是全平面的切割,这样相比着decision tree就会有更加细腻的边界线,但是相比着AdaBoost VC bound的理论上的upper bound的限制,decision tree则没有那么多的理论上的解释,所以需要显式的regularization,而AdaBoost则不需要。
那么再看在复杂样本上的表现吧:

C&RT方法的特点如下总结。不同的decision tree的演算法不同之处可能就是在于如何regularization即如何砍树叶子(pruning),或者某些点上的处理不同而已。

下面可能要做的就是把C&RT算法基于上面的例子进行实现,并于AdaBoost-stump进行对比,以加深对Decision Tree的理论上的理解。
*****************************************************随时学习,随时分享******************************************************