Linux内核分析 - 网络[八]:IP协议
内核版本:2.6.34
这篇是关于IP层协议接收报文时的处理,重点说明了路由表的查找,以及IP分片重组。
ip_rcv进入IP层报文接收函数
丢弃掉不是发往本机的报文,skb->pkt_type在网卡接收报文处理以太网头时会根据dst mac设置,协议栈的书会讲不是发往本机的广播报文会在二层被丢弃,实际上丢弃是发生在进入上层之初。
if (skb->pkt_type == PACKET_OTHERHOST) goto drop;
在取IP报头时要注意可能带有选项,因此报文长度应当以iph->ihl * 4为准。这里就需要尝试两次,第一次尝试sizeof(struct iphdr),只是为了确保skb还可以容纳标准的报头(即20字节),然后可以ip_hdr(skb)得到报头;第二次尝试ihl * 4,这才是报文的真正长度,然后重新调用ip_hdr(skb)来得到报头。两次尝试pull后要重新调用ip_hdr()的原因是pskb_may_pull()可能会调用__pskb_pull_tail()来改现现有的skb结构。
if (!pskb_may_pull(skb, sizeof(struct iphdr))) goto inhdr_error; iph = ip_hdr(skb); …… if (!pskb_may_pull(skb, iph->ihl*4)) goto inhdr_error; iph = ip_hdr(skb);
获取到IP报头后经过一些检查,获取到报文的总长度len = iph->tot_len,此时调用pskb_trim_rcsum()去除多余的字节,即大于len的。
if (pskb_trim_rcsum(skb, len)) {
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INDISCARDS);
goto drop;
}
然后调用ip_rcv_finish()继续IP层的处理,ip_rcv()可以看成是查找路由前的IP层处理,接下来的ip_rcv_finish()会查找路由表,两者间调用插入的netfilter(关于NetFilter,参考前篇http://blog.csdn.net/qy532846454/article/details/6605592)。
return NF_HOOK(PF_INET, NF_INET_PRE_ROUTING, skb, dev, NULL, ip_rcv_finish);
进入ip_rcv_finish函数
ip_rcv_finish()主要工作是完成路由表的查询,决定报文经过IP层处理后,是继续向上传递,还是进行转发,还是丢弃。
刚开始没有进行路由表查询,所以还没有相应的路由表项:skb_dst(skb) == NULL。则在路由表中查找ip_route_input(),关于内核的路由表,可以参见前篇http://blog.csdn.net/qy532846454/article/details/6726171:
if (skb_dst(skb) == NULL) {
int err = ip_route_input(skb, iph->daddr, iph->saddr, iph->tos,
skb->dev);
if (unlikely(err)) {
if (err == -EHOSTUNREACH)
IP_INC_STATS_BH(dev_net(skb->dev),
IPSTATS_MIB_INADDRERRORS);
else if (err == -ENETUNREACH)
IP_INC_STATS_BH(dev_net(skb->dev),
IPSTATS_MIB_INNOROUTES);
goto drop;
}
}
通过路由表查找,我们知道:
- 如果是丢弃的报文,则直接drop;
- 如果是不能接收或转发的报文,则input = ip_error
- 如果是发往本机报文,则input = ip_local_deliver;
- 如果是广播报文,则input = ip_local_deliver;
- 如果是组播报文,则input = ip_local_deliver;
- 如果是转发的报文,则input = ip_forward;
在ip_rcv_finish()最后,会调用查找到的路由项_skb_dst->input()继续向上传递:
return dst_input(skb);
具体看下各种情况下的报文传递,如果是丢弃的报文,则报文被释放,并从IP协议层返回,完成此次报文传递流程。
drop: kfree_skb(skb); return NET_RX_DROP;
如果是不能处理的报文,则执行ip_error,根据error类型发送相应的ICMP错误报文。
static int ip_error(struct sk_buff *skb)
{
struct rtable *rt = skb_rtable(skb);
unsigned long now;
int code;
switch (rt->u.dst.error) {
case EINVAL:
default:
goto out;
case EHOSTUNREACH:
code = ICMP_HOST_UNREACH;
break;
case ENETUNREACH:
code = ICMP_NET_UNREACH;
IP_INC_STATS_BH(dev_net(rt->u.dst.dev),
IPSTATS_MIB_INNOROUTES);
break;
case EACCES:
code = ICMP_PKT_FILTERED;
break;
}
now = jiffies;
rt->u.dst.rate_tokens += now - rt->u.dst.rate_last;
if (rt->u.dst.rate_tokens > ip_rt_error_burst)
rt->u.dst.rate_tokens = ip_rt_error_burst;
rt->u.dst.rate_last = now;
if (rt->u.dst.rate_tokens >= ip_rt_error_cost) {
rt->u.dst.rate_tokens -= ip_rt_error_cost;
icmp_send(skb, ICMP_DEST_UNREACH, code, 0);
}
out: kfree_skb(skb);
return 0;
}
如果是主机可以接收报文,则执行ip_local_deliver。ip_local_deliver在向上传递前,会对分片的IP报文进行组包,因为IP层协议会对过大的数据包分片,在接收时,就要进行重组,而重组的操作就是在这里进行的。IP报头的16位偏移字段frag_off是由3位的标志(CE,DF,MF)和13的偏移量组成。如果收到了分片的IP报文,如果是最后一片,则MF=0且offset!=0;如果不是最后一片,则MF=1。
在这种情况下会执行ip_defrag来处理分片的IP报文,如果不是最后一片,则将该报文添加到ip4_frags中保留下来,并return 0,此次数据包接收完成;如果是最后一片,则取出之前收到的分片重组成新的skb,此时ip_defrag返回值为0,skb被重置为完整的数据包,然后继续处理,之后调用ip_local_deliver_finish处理重组后的数据包。
if (ip_hdr(skb)->frag_off & htons(IP_MF | IP_OFFSET)) {
if (ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
下面来看下ip_defrag()函数,主体就是下面的代码段。它首先用ip_find()查找IP分片,并返回(如果没有则创建),然后用ip_frag_queue()将新分片加入,关于IP分片的处理,在后面的IP分片中有详细描述。
if ((qp = ip_find(net, ip_hdr(skb), user)) != NULL) {
int ret;
spin_lock(&qp->q.lock);
ret = ip_frag_queue(qp, skb);
spin_unlock(&qp->q.lock);
ipq_put(qp);
return ret;
}
然后会调用ip_local_deliver_finish()完成IP协议层的传递,两者调用间依然有netfilter,这是查找完路由表继续向上传递的中间点。
NF_HOOK(PF_INET, NF_INET_LOCAL_IN, skb, skb->dev, NULL, ip_local_deliver_finish);
在ip_local_deliver_finish()中会完成IP协议层处理,再交由上层协议模块处理:ICMP、IGMP、UDP、TCP。在ip_local_deliver_finish函数中,由于IP报头已经处理完,剔除IP报头,并设置skb->transport_header指向传输层协议报头位置。
__skb_pull(skb, ip_hdrlen(skb)); skb_reset_transport_header(skb);
protocol是IP报头中的的上层协议号,以它在inet_protos哈希表中查找处理protocol的协议模块,取出得到ipprot。
hash = protocol & (MAX_INET_PROTOS - 1); ipprot = rcu_dereference(inet_protos[hash]);
而关于inet_protos,它的数据结构是哈希表,用来存储IP层上的协议,包括传输层协议和3.5层协议,它在IP协议模块加载时被添加。
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0) printk(KERN_CRIT "inet_init: Cannot add ICMP protocol\n"); if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0) printk(KERN_CRIT "inet_init: Cannot add UDP protocol\n"); if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0) printk(KERN_CRIT "inet_init: Cannot add TCP protocol\n"); #ifdef CONFIG_IP_MULTICAST if (inet_add_protocol(&igmp_protocol, IPPROTO_IGMP) < 0) printk(KERN_CRIT "inet_init: Cannot add IGMP protocol\n"); #endif
然后通过调用handler交由上层协议处理,至此,IP层协议处理完成。
ret = ipprot->handler(skb);
IP分片
在收到IP分片时,会暂时存储到一个哈希表ip4_frags中,它在IP协议模块加载时初始化,inet_init() -> ipfrag_init()。要留意的是ip4_frag_match用于匹配IP分片是否属于同一个报文;ip_expire用于在IP分片超时时进行处理。
void __init ipfrag_init(void)
{
ip4_frags_ctl_register();
register_pernet_subsys(&ip4_frags_ops);
ip4_frags.hashfn = ip4_hashfn;
ip4_frags.constructor = ip4_frag_init;
ip4_frags.destructor = ip4_frag_free;
ip4_frags.skb_free = NULL;
ip4_frags.qsize = sizeof(struct ipq);
ip4_frags.match = ip4_frag_match;
ip4_frags.frag_expire = ip_expire;
ip4_frags.secret_interval = 10 * 60 * HZ;
inet_frags_init(&ip4_frags);
}
当收到一个IP分片,首先用ip_find()查找IP分片,实际上就是从ip4_frag表中取出相应项。这里的哈希值是由IP报头的(标识,源IP,目的IP,协议号)得到的。
hash = ipqhashfn(iph->id, iph->saddr, iph->daddr, iph->protocol); q = inet_frag_find(&net->ipv4.frags, &ip4_frags, &arg, hash);
inet_frag_find实现直正的查找
根据hash值取得ip4_frag->hash[hash]项 – inet_frag_queue,它是一个队列,然后遍历该队列,当net, id, saddr, daddr, protocol, user相匹配时,就是要找的IP分片。如果没有匹配的,则调用inet_frag_create创建它。
struct inet_frag_queue *inet_frag_find(struct netns_frags *nf,
struct inet_frags *f, void *key, unsigned int hash)
__releases(&f->lock)
{
struct inet_frag_queue *q;
struct hlist_node *n;
hlist_for_each_entry(q, n, &f->hash[hash], list) {
if (q->net == nf && f->match(q, key)) {
atomic_inc(&q->refcnt);
read_unlock(&f->lock);
return q;
}
}
read_unlock(&f->lock);
return inet_frag_create(nf, f, key);
}
inet_frag_create创建一个IP分片队列ipq,并插入相应队列中。
首先分配空间,真正分配空间的是inet_frag_alloc中的q = kzalloc(f->qsize, GFP_ATOMIC);其中f->qsize = sizeof(struct ipq),也就是说分配了ipq大小空间,但返回的却是struct inet_frag_queue q结构,原因在于inet_frag_queue是ipq的首个属性,它们两者的联系如下图。
![Linux内核分析 - 网络[八]:IP协议_第1张图片](http://img.e-com-net.com/image/info5/408de2898c804feda6f34a468cf592aa.jpg)
static struct inet_frag_queue *inet_frag_create(struct netns_frags *nf,
struct inet_frags *f, void *arg)
{
struct inet_frag_queue *q;
q = inet_frag_alloc(nf, f, arg);
if (q == NULL)
return NULL;
return inet_frag_intern(nf, q, f, arg);
}
在分配并初始化空间后,由inet_frag_intern完成插入动作,首先还是根据(标识,源IP,目的IP,协议号)先成hash值,这里的qp_in即之前的q。
hash = f->hashfn(qp_in);
然后新创建的队列qp(即上面的qp_in)插入到hash表(即ip4_frags->hash)和net->ipv4.frags中,并增加队列qp的引用计数,net中的队列nqueues统计数。至此,IP分片的创建过程完成。
atomic_inc(&qp->refcnt); hlist_add_head(&qp->list, &f->hash[hash]); list_add_tail(&qp->lru_list, &nf->lru_list); nf->nqueues++;
ip_frag_queue实现将IP分片加入队列中
首先获取该IP分片偏移位置offset,和IP分片偏移结束位置end,其中skb->len – ihl表示IP分片的报文长度,三者间关系即为end = offset + skb->len – ihl。
offset = ntohs(ip_hdr(skb)->frag_off); flags = offset & ~IP_OFFSET; offset &= IP_OFFSET; offset <<= 3; /* offset is in 8-byte chunks */ ihl = ip_hdrlen(skb); /* Determine the position of this fragment. */ end = offset + skb->len - ihl;
如果该IP分片是最后一片(MF=0,offset!=0),即设置q.last_iin |= INET_FRAG_LAST_IN,表示收到了最后一个分片,qp->q.len = end,此时q.len是整个IP报文的总长度。
if ((flags & IP_MF) == 0) {
if (end < qp->q.len ||
((qp->q.last_in & INET_FRAG_LAST_IN) && end != qp->q.len))
goto err;
qp->q.last_in |= INET_FRAG_LAST_IN;
qp->q.len = end;
}
如果该IP分片不是最后一片(MF=1),当end不是8字节倍数时,通过end &= ~7处理为8字节整数倍(但此时会忽略掉多出的字节,如end=14 => end=8);然后如果该分片更靠后,则q.len = end。
else {
if (end&7) {
end &= ~7;
if (skb->ip_summed != CHECKSUM_UNNECESSARY)
skb->ip_summed = CHECKSUM_NONE;
}
if (end > qp->q.len) {
/* Some bits beyond end -> corruption. */
if (qp->q.last_in & INET_FRAG_LAST_IN)
goto err;
qp->q.len = end;
}
}
查找q.fragments链表,找到该IP分片要插入的位置,这里的q.fragments就是struct sk_buff类型,即各个IP分片skb都会插入到该链表中,插入的位置按偏移顺序由小到大排列,prev表示插入的前一个IP分片,next表示插入的后一个IP分片。
prev = NULL;
for (next = qp->q.fragments; next != NULL; next = next->next) {
if (FRAG_CB(next)->offset >= offset)
break; /* bingo! */
prev = next;
}
然后将skb插入到链表中,要注意fragments为空和不为空的情形,在下图中给出。
skb->next = next; if (prev) prev->next = skb; else qp->q.fragments = skb;
![Linux内核分析 - 网络[八]:IP协议_第2张图片](http://img.e-com-net.com/image/info5/bc16ec40bf22419ba442cea01a89adac.jpg)
增加q.meat计数,表示已收到的IP分片的总长度;如果offset为0,则表明是第一个IP分片,设置q.last_in |= INET_FRAG_FIRST_IN。
qp->q.meat += skb->len; if (offset == 0) qp->q.last_in |= INET_FRAG_FIRST_IN;
最后当满足一定条件时,进行IP重组。当收到了第一个和最后一个IP分片,且收到的IP分片的最大长度等于收到的IP分片的总长度时,表明所有的IP分片已收集齐,调用ip_frag_reasm重组包。具体的,当收到第一个分片(offset=0且MF=1)时设置q.last_in |= INET_FRAG_FIRST_IN;当收到最后一个分片(offset != 0且MF=0)时设置q.last_in |= INET_FRAG_LAST_IN。meat和len的区别在于,IP是不可靠传输,到达的IP分片不能保证顺序,而meat表示到达IP分片的总长度,len表示到达的IP分片中偏移最大的长度。所以当满足上述条件时,IP分片一定是收集齐了的。
if (qp->q.last_in == (INET_FRAG_FIRST_IN | INET_FRAG_LAST_IN) && qp->q.meat == qp->q.len) return ip_frag_reasm(qp, prev, dev);
以下图为例,原始IP报文分成了4片发送,假设收到了1, 3, 4分片,则此时q.last_in = INET_FRGA_FIRST_IN | INET_FRAG_LAST_IN,q.meat = 30,q.len = 50。表明还未收齐IP分片,等待IP分片2的到来。
![Linux内核分析 - 网络[八]:IP协议_第3张图片](http://img.e-com-net.com/image/info5/2325749d43ee4cc6a2cc3079891805b2.jpg)
这里还有一些特殊情况需要处理,它们可能是重新分片或传输时错误造成的,那就是IP分片互相间有重叠。为了避免这种情况发生,在插入IP分片前会处理掉这些重叠。
第一种重叠是与前个分片重叠,即该分片的的偏移是从前个分片的范围内开始的,这种情况下i表示重叠部分的大小,offset+=i则将该分片偏移后移i个长度,从而与前个分片隔开,而且减少len,pskb_pull(skb, i),见下图图示。
if (prev) {
int i = (FRAG_CB(prev)->offset + prev->len) - offset;
if (i > 0) {
offset += i;
err = -EINVAL;
if (end <= offset)
goto err;
err = -ENOMEM;
if (!pskb_pull(skb, i))
goto err;
if (skb->ip_summed != CHECKSUM_UNNECESSARY)
skb->ip_summed = CHECKSUM_NONE;
}
}

第二种重叠是与后个分片重叠,即该分片的的结束位置在后个分片的范围内,这种情况下i表示重叠部分的大小。后片重叠稍微复杂点,被i重叠的部分都要删除掉,如果i比较大,超过了分片长度,则整个分片都被覆盖,从q.fragments链表中删除。使用while处理i覆盖多个分片的情况。
while (next && FRAG_CB(next)->offset < end)
当整个分片被覆盖掉,从q.fragments中删除,并且由于减少了分片总长度,所以q.meat要减去删除分片的长度。
else {
struct sk_buff *free_it = next;
next = next->next;
if (prev)
prev->next = next;
else
qp->q.fragments = next;
qp->q.meat -= free_it->len;
frag_kfree_skb(qp->q.net, free_it, NULL);
}
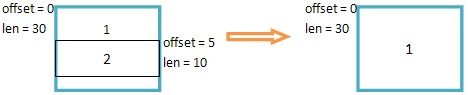
当只覆盖分片一部分时,offset+=i则将后个分片偏移后移i个长度,从而与该分片隔开,同时这样相当于减少了IP分片的长度,所以q.meat -= i;见下图图示,
if (i < next->len) {
if (!pskb_pull(next, i))
goto err;
FRAG_CB(next)->offset += i;
qp->q.meat -= i;
if (next->ip_summed != CHECKSUM_UNNECESSARY)
next->ip_summed = CHECKSUM_NONE;
break;
}

ip_frag_reasm函数实现IP分片的重组
ip_frag_reasm传入的参数是prev,而重组完成后ip_defrag会将skb替换成重组后的新的skb,而在之前的操作中,skb插入了qp->q.fragments中,并且prev->next即为skb,因此第一步就是让skb变成qp->q.fragments,即IP分片的头部。
if (prev) {
head = prev->next;
fp = skb_clone(head, GFP_ATOMIC);
if (!fp)
goto out_nomem;
fp->next = head->next;
prev->next = fp;
skb_morph(head, qp->q.fragments);
head->next = qp->q.fragments->next;
kfree_skb(qp->q.fragments);
qp->q.fragments = head;
}
下面图示说明了上面代码段作用,skb是IP分片3,通过skb_clone拷贝一份3_copy替代之前的分片3,再通过skb_morph拷贝q.fragments到原始IP分片3,替代分片1,并释放分片1:
![Linux内核分析 - 网络[八]:IP协议_第4张图片](http://img.e-com-net.com/image/info5/0c643d6509e64efab5d7288be710e483.jpg)
获取IP报头长度ihlen,head就是ip_defrag传入参数中的skb,并且它已经成为了IP分片队列的头部;len为整个IP报头+报文的总长度,qp->q.len是未分片前IP报文的长度。
ihlen = ip_hdrlen(head); len = ihlen + qp->q.len;
此时head就是skb,并且它的skb->data存储了第一个IP分片的内容,其它IP分片的内容将存储在紧接skb的空间 – frag_list;skb_push将skb->data回归原位,即未处理IP报头前的位置,因为之前的IP分片处理会调用skb_pull移走IP报头,将它回归原位是因为skb即将作为重组后的报文而被处理,那里会真正的skb_pull移走IP报头,再交由上层协议处理。
skb_shinfo(head)->frag_list = head->next; skb_push(head, head->data - skb_network_header(head));
上面所说的frag_list是struct skb_shared_info的一个属性,在分配skb时分配在其后空间,通过skb_shinfo(skb)进行引用。下面分配skb大小size和skb_shared_info大小的代码摘自[net/core/skbuff.c]
size = SKB_DATA_ALIGN(size); data = kmalloc_node_track_caller(size + sizeof(struct skb_shared_info), gfp_mask, node);
这里要弄清楚sk_buff中线性存储区和paged buffer的区别,线性存储区就是存储报文,如果是分片后的,则只是第一个分片的内容;而paged buffer则存储其余分片的内容。而skb->data_len则表示paged buffer中内容长度,而skb->len则是paged buffer + linear buffer。下面这段代码就是根据余下的分片增加data_len和len计数。
for (fp=head->next; fp; fp = fp->next) {
head->data_len += fp->len;
head->len += fp->len;
……
}
IP分片已经重组完成,分片从q.fragments链表移到了frag_list上,因此head->next和qp->q.fragments置为NULL。偏移量frag_off置0,总长度tot_len置为所有分片的长度和,这样,skb就相当于没有分片的完整的大数据包,继续向上传递。
head->next = NULL; head->dev = dev; …… iph = ip_hdr(head); iph->frag_off = 0; iph->tot_len = htons(len); IP_INC_STATS_BH(net, IPSTATS_MIB_REASMOKS); qp->q.fragments = NULL;