lua 5.0的实现(翻译)1,2,3,4,5
http://www.blogjava.net/killme2008/archive/2008/04/07/191324.html
三个多月前翻译的,今天又找出来看看,后面的待整理下继续发,有错误的地方请不吝赐教。
原文:http://www.tecgraf.puc-rio.br/~lhf/ftp/doc/jucs05.pdf
翻译:dennis zhuang ([email protected]) http://www.blogjava.net/killme2008
转载请注明出处,谢谢。
摘要:我们讨论了lua 5.0实现的主要新特性:基于寄存器的虚拟机,优化表的新算法以便(将表)用作数组,闭包的实现,以及coroutines(译注:协程)
关键字: compilers, virtual machines, hash tables, closures, coroutines
1. 介绍
Lua作为内部使用的开发工具诞生于学术实验室中,现在却已经被世界范围内许多工业级项目所采用,广泛应用于游戏领域。Lua为什么能获得这样广泛的应用呢?我们认为答案就来源于我们的设计和实现目标上:提供一种简单、高效、可移植和轻量级的嵌入式脚本语言。这是Lua自1993年诞生以来我们一直追求的目标,并在(语言的)演化过程中遵守。这些特性,以及Lua一开始就被设计成嵌入大型应用的事实,才使它在早期被工业界所接受。
广泛的应用产生了对(新的)语言的特性的需求。Lua的许多特性来自于工业需求和用户反馈的推动。重要的例如lua 5.0引入的coroutines和即将到来的Lua 5.1改进的垃圾收集实现,这些特性对于游戏(编程)特别重要。
在这篇论文中,我们讨论了lua 5.0相比于lua 4.0的主要新特性:
基于寄存器的的虚拟机:传统上,绝大多数虚拟机的实际执行都是基于栈,这个趋势开始于Pascal的Pmachine,延续到今天的java虚拟机和微软的.net环境。目前,尽管对于基于寄存器的虚拟机的兴趣逐渐增多(比如Perl6计划中的新的虚拟机(Parrot)将是基于寄存器的),但是就我们所知,lua 5.0是第一个被广泛使用的基于寄存器的虚拟机。我们将在第7部分描述这个虚拟机。
优化表的新算法以便作为数组: 不像其他脚本语言,Lua并没有提供数组类型。Lua使用整数索引的普通表来实现数组作为替代。Lua 5.0使用了一个新的算法,可以检测表是否被作为数组使用,并且可以自动将关联着数字索引的值存储进一个真实的数组,而不是将它们放进Hash表。在第4部分我们将讨论这个算法。
闭包的实现:lua 5.0在词法层次上支持first-class 函数(译注:将函数作为一等公民)。这个机制导致一个著名的语言难题:使用基于数组的栈来存储激活记录。Lua 使用了一个新办法来实现函数闭包,保存局部变量在(基于数组)的栈(stack)上,当它们被内嵌函数引用而从作用域逸出的时候才将它们转移到堆(heap)上。闭包的实现将在第5部分讨论。
添加coroutines: lua 5.0语言引入了coroutines。尽管coroutines的实现较为传统,但为了完整性我们将在第6部分做个简短的概况介绍。
其他部分是为了讨论的完整性或者提供背景资料。在第2部分我们介绍了lua的设计目标以及这个目标如何驱动实现的概况。在第3部分我们介绍了lua是如何表示值的。尽管就这个过程本身没有什么新意,但是为了(理解)其他部分我们需要这些资料。最后,在第8部分,我们介绍了一个小型的基准测试来得到一些结论。
2. lua设计和实现概况
在介绍部分提到过的,lua实现的主要目标是:
简单性:我们探索我们能提供的最简单的语言,以及实现(这样的)语言的最简单的C代码。这就意味着(需要)不会偏离传统很远的拥有很少语言结构的简单语法。
效率:我们探索编译和执行lua程序的最快方法,这就意味着(需要)一个高效的、聪明的一遍扫描编译器和一个高效的虚拟机。
可移植性:我们希望lua能跑在尽可能多的平台上。我们希望能在任何地方不用修改地编译lua核心,在任何一个带有合适的lua解释器的平台上不用修改地运行lua程序。这就意味着一个对可移植性特别关注的干净的ANSI C的实现,例如避开C和标准库库中的陷阱缺陷,并确保能以c++方式干净地编译。我们追求warning-free的编译(实现)。
嵌入性:lua是一门扩展语言,它被设计用来为大型程序提供脚本设施。这个以及其他目标就意味着一个简单并且强大的C API实现,但这样将更多地依赖内建的C类型。
嵌入的低成本:我们希望能容易地将Lua添加进一个应用,而不会使应用变的臃肿。这就意味着(需要)紧凑的C代码和一个小的Lua核心,扩展将作为用户库来添加。
这些目标是有所权衡的。例如,lua经常被用作数据描述语言,用于保存和加载文件,有时是非常大的数据库(几M字节的lua程序不常见)。这就意味着我们需要一个快速的lua编译器。另一方面,我们想让lua程序运行快速,这就意味着(需要)一个可以为虚拟机产生优秀代码的聪明的编译器。因此,LUA编译器的实现必须在这两种需求中寻找平衡。尽管如此,编译器还是不能太大,否则将使整个发行包变的臃肿。目前编译器大约占lua核心大小的30%。在内存受限的应用中,比如嵌入式系统,嵌入不带有编译器的Lua是可能的,Lua程序将被离线预编译,然后被一个小模块(这个小模块也是快速的,因为它加载的是二进制文件)在运行时加载。
Lua使用了一个手写的扫描器和一个手写的递归下降解释器。直到3.0版本,lua还在使用一个YACC产生的解释器,这在语言的语法不够稳定的时候很有价值的。然而,手写的解释器更小、更高效、更轻便以及完全可重入,也能提供更好的出错信息(error message)。
Lua编译器没有使用中间代码表示(译注:也就是不生成中间代码)。当解释一个程序的时候,它以“on-the-fly”的 方式给虚拟机发出指令。不过,它会进行一些优化。例如,它会推迟像变量和常量这样的基本表达式的代码生成。当它解释这样的表达式的时候,没有产生任何代 码,而是使用一种简单的结构来表示它们。所以,判断一个给定指令的操作数是常量还是变量以及将它们的值直接应用在指令都变的非常容易,避免了不必要的和昂 贵的移动。
为了轻便地在许许多多不同的C编译器和平台之间移植,Lua不能使用许多解释器通常使用的技巧,例如direct threaded code [8, 16]。作为替代,它(译注:指lua解释器)使用了标准的while-switch分发循环。此处的C代码看起来过于复杂,但是复杂性也是为了确保可移植性。当lua在许多不同的平台上(包括64位平台和一些16位平台)被很多不同的C编译器编译,lua实现的可移植性一直以来变的越来越稳定了。
我们认为我们已经达到我们的设计和实现目标了。Lua是一门非常轻便的语言,它能跑在任何一个带有ANSI C编译器的平台上,从嵌入式系统到大型机。Lua确实是轻量级的:例如,它在linux平台上的独立解释器包括所有的标准库,占用的空间小于150K;核心更是小于100K。lua是高效的:独立的基准测试表明lua是脚本语言(解释的、动态类型的语言)领域中最快的语言之一。主观上我们也认为lua是一门简单的语言,语法上类似Pascal,语义上类似Scheme(译注:Lisp的一种方言)。
3、值的表示
Lua是动态类型语言:类型依附于值而不是变量。Lua有8种基本类型:nil, boolean, number, string, table, function,userdata, 和thread。Nil是一个标记类型,它只拥有一个值也叫nil。Boolean就是通常的true和false。Number是双精度浮点数,对应于C语言中的double类型,但用float或者long作为替代来编译lua也很容易(不少游戏consoles或者小机器都缺乏对double的硬件支持)。String是有显式大小的字节数组,因此可以存储任意的二进制类型,包括嵌入零。Table类型就是关联的数组,可以用任何值做索引(除了nil),也可以持有任何值。Function是依据与lua虚拟机连接的协议编写的lua函数或者C函数。Userdata本质上是指向用户内存区块(user memory block)的指针,有两种风格:重量级,由lua分配块并由GC回收;轻量级,由用户分配和释放(内存)块。最后,thread表示coroutines。所有类型的值都是first-class值:我们可以将它们作为全局变量、局部变量和table的域来存储,作为参数传递给函数,作为函数的返回值等等。
typedef struct { typedef union {
int t; GCObject *gc;
Value v; void *p;
} TObject; lua_Number n;
int b;
} Value;
Figure 1: 带标签的union表示lua值
Lua将值表示为带标签的union(tagged unions),也就是pairs(t,v),其中t是一个决定了值v类型的整数型标签,而v是一个实现了lua类型的C语言的union结构。Nil拥有一个单独的值(译注:也就是nil)。Booleans和numbers被实现为“拆箱式”的值:v在union中直接表示这些类型的值。这就意味着union(译注:指图中的Value)必须有足够的空间容纳double(类型)。Strings,tables, functions, threads, 和 userdata类型的值通过引用来实现:v拥有指向实现这些类型的结构的指针。这些结构(译注:指实现Strings,tables, functions, threads, 和 userdata这些类型的具体结构)共享一个共同的head,用来保存用于垃圾收集的信息。结构的剩下的部分专属于各自的类型。
Figure1展示了一个实际的lua值的实现。TObject是这个实现的主要结构体:它表示了上文描述的带标签的联合体(tagged unions) (t,v)。Value是实现了值的union类型。类型nil的值没有显式表示在这个union类型中是因为标签已经足够标识它们。域n用来表示numbers类型(lua_Number默认是double类型)。同样,域b是给booleans类型用的,域p是给轻量级的userdata类型。而域gc是为会被垃圾回收的其他类型准备的((strings, tables, functions, 重量级userdata, 和threads)。
使用带标签的union实现lua值的一个后果就是拷贝值的代价稍微昂贵了一点:在一台支持64位double类型的32位机器上,TObject的大小是12字节(或者16字节,如果double按8字节对齐的话),因此拷贝一个值将需要拷贝3(或者4)个机器字长。尽管如此,想在ANSI C中实现一个更好的值的表示是困难的。一些动态类型语言(例如Smalltalk80的原始实现)在每个指针中使用多余的位来存储值的类型标签。这个技巧在绝大多数机器上正常工作,这是因为一个指针的最后两个或者三个位由于对齐将总是0,所以可以被用作他途。但是,这项技术既不是可移植的也无法在ANSI C中实现,C 语言标准甚至都不保证指针适合任何整数类型,所以没有在指针上操作位的标准方法。
减小值大小的另一个观点就是持有显式标签,从而避免在union中放置一个double类型。例如,所有的number类型可以表示为堆分配的对象,就像String那样。(python使用了这项技术,除了预先分配了一些小的整数值)。尽管如此,这样的表示方法将使语言变的非常缓慢。作为选择,整数的值可以表示位“拆箱式”的值,直接存储在union中,而浮点值放在堆中。这个办法将极大地增加所有算术运算操作的实现复杂度。
类似早期的解释型语言,例如Snobol [11] 和 Icon [10],lua在一个hash表中“拘留”(internalizes)字符串:(hash表)没有重复地持有每个字符串的单独拷贝。此外,String是不可变的:一个字符串一旦被“拘留”,将不能再被改变。字符串的哈希值依据一个混合了位和算术运算的简单表达式来计算,囊括所有的位。当字符串被“拘留”时,hash值保存(到hash表),以支持更快的字符串比较和表索引。如果字符串太长的话,hash函数并不会用到字符串的所有字节,这有利于快速地散列长字符串。避免处理长字符串带来的性能损失是重要的,因为(这样的操作)在lua中是很普遍的。例如,用lua处理文件的时候经常将整个文件内容作为一个单独的长字符串读入内存。
4、 表
Table是lua的主要——实际上,也是唯一的——数据结构。Table不仅在语言中,同时也在语言的实现中扮演着重要角色。Effort spent on a good implementation of tables is rewarded in the language,because tables are used for several internal tasks, with no qualms about performance。这有助于保持实现的小巧。相反的,任何其他数据结构的机制的缺乏也为table的高效实现带来了很大压力
Lua中的table是关联数组,也就是可以用任何值做索引(除了nil),也可以持有任何值。另外,table是动态的,也就是说当加进数据的时候它们将增长(给迄今不存在的域赋值)而移除数据的时候将萎缩(给域赋nil值)。
不像大多数其他脚本语言,lua没有数组类型。数组被表示为以整数做键的table。用table作为数组对于语言是有益的。主要的(益处)显而易见:lua并不需要操纵表和数组的两套不同的运算符。另外,程序员不用对两种实现做出艰难选择。在lua中实现稀疏数组是轻而易举的。例如,在Perl里面,如果你尝试去跑$a[1000000000]=1 这样的程序,你能跑出个内存溢出!(you can run out of memory),因为它触发了一个10亿个元素的数组的创建(译注,Perl的哲学是:去除不必要的限制)。而等价的lua程序 a={[1000000000]=1},(只是)创建了有一个单独的项的表(而已)。

直到lua 4.0,table都是作为hash表严格地实现:所有的pair都被显式地保存。Lua5.0引入了一个新算法来优化作为数组的table:它将以整数为键的pair不再是存储键而是优化成存储值在真正的数组中。更精确地说,在lua 5.0中,table被实现为一个混合数据结构:它们包括一个hash部分和一个数组部分。图2展示了一个有"x"→ 9.3, 1 → 100,2 → 200, 3 → 300对子的表的一种可能结构。注意到数组部分在右边,并没有存储整数的key。这个划分仅仅是在一个低的实现层次进行的,访问table仍然是透明的,甚至在虚拟机内部(访问table)也是如此。Table根据内容自动并且动态地对两个部分进行适配:数组部分试图从1到n的相应地存储值,关联非整数键或者整数键超过数组范围的值被存储在hash部分。
当一个table需要增长时,lua重新计算hash部分和数组部分的大小。任一部分都可能是空的。重新计算后的数组大小是至少是当前使用的数组部分从1到n的一半情况下的最大n值(原文:The computed size of the array part is the largest n such that at least half the slots between 1 and n are in use)(稀疏数组时避免浪费空间),并至少有一个(元素)处在n/2+1到n的槽中(当n被2整除时,避免n的这样的数组大小)。计算完大小后,lua创建了“新”的部分并将“旧”的部分的元素重新插入到的“新”的部分。作为一个例子,假设a是一个空表;它的数组部分和hash部分的大小都是0。当我们执行a[1]=v时,这个表需要增长到足够容纳新的键。Lua将为新的数组部分的大小选择n=1(带有一个项1→v)。hash部分仍然保持为空。
这个混合的方案有两个优点。首先,访问以整数为键的值加快了,因为不再需要任何的散列行为。其次,也是最重要的,数组部分占用的内存大概是将数组部分存储在hash部分时的一半,因为key在数组中是隐式的(译注:也就是数组的下标)而在hash部分却是显式的。因而,当一个table被用作数组的时,它表现的就像一个数组,只要整数键是密集。另外,不用为hash部分付出任何内存和时间上的惩罚,因为它(译注:hash部分)甚至都不存在。相反的控制:如果table被用作关联数组而非一个数组,数组部分可能就是空的。这些内存上的节省是比较重要的,因为lua程序经常创建一些小的table,例如table被用来实现对象(Object)(译注,也就是用table来模仿对象,有点类似javascript中的json)。
Hash部分采用Brent's variation[3]的组合的链状发散表。这些table的主要不变式是如果一个元素没有在它的主要位置上(也就是hash值的原始位置),则冲突的元素在它自己的主要位置上。换句话说,仅当两个元素有相同的主要位置(也就是在当时table大小情况下的hash值)时才有冲突的。没有二级冲突。正因为那样,这些table的加载因子可以是100%而没有性能上的损失。这部分不是很明白,附上原文:
The hash part uses a mix of chained scatter table with Brent's variation [3].
A main invariant of these tables is that if an element is not in its main position
(i.e., the original position given by its hash value), then the colliding element
is in its own main position. In other words, there are collisions only when two
elements have the same main position (i.e., the same hash values for that table
size). There are no secondary collisions. Because of that, the load factor of these
tables can be 100% without performance penalties.
5、函数和闭包
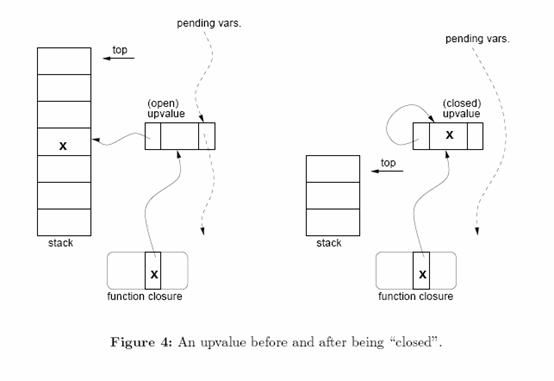
当lua编译一个函数的时候,它产生一个模型(prototype),包括了函数的虚拟机指令、常量值(数字,字符串字面量等)和一些调试信息。运行的时候,无论何时lua执行一个function…end表达式,它都创建一个新的闭包。每个闭包都有一个引用指向相应的模型,一个引用指向环境(environment)(一张查找全局变量的表,译注:指所谓环境就是这样一张表),和一组用来访问外部local变量的指向upvalue的引用。
词法范围以及first-class函数的组合导致一个关于(如何)访问外部local变量的著名难题。考虑图3中的例子。当add2被调用的时候,它的函数体(body)部分引用了外部local变量x (函数参数在lua里是local变量,译注:x就是所谓的自由变量,这里形成了闭包)。尽管如此,当add2被调用时,生成add2的函数add已经返回。如果在栈中生成变量x,(x在栈的)其栈槽将不复存在。(译注,此处的意思应该是说如果在栈保存变量x,那么在调用add2的时候,add函数早已经返回,x也在add2调用前就不在栈里头了,这就是那个著名难题)。

大多数过程语言通过限制词法范围(例如python),不提供first-class函数(例如Pascal),或者都两者都采用(例如c,译注:也就是说c既不把函数当一等公民,也限制词法范围)来回避这个问题。函数式语言就没有那些限制。围绕着非纯粹函数语言比如Scheme和ML的研究已经产生了大量的关于闭包的编译技术的知识(参见[19, 1, 21])。尽管如此,这些工作并没有尽力去限制编译器的复杂性。以优化的Scheme编译器Bigloo的控制流分
析阶段为例,(它的实现)比lua实现的10倍还大:Bigloo 2.6f的Cfa模块源码有106,350行 VS. 10,155行的lua5.0核心。正如第2部分已经解释过的(原因),lua需要简单。
Lua使用了一个称为upvalue的结构来实现闭包。任何外部local变量的访问都是通过一个upvalue间接进行的。Upvalue初始指向的是变量存活位置的栈槽(参见图4的左半部分)。当变量(x)已经离开作用域(译注,也就是这里的add函数返回时),它就迁移到upvalue结构本身一个槽中(参见图4的右半部分)。因为(对变量的)访问是间接地通过upvalue结构中的一个指针进行的,因此这个迁移对于任何写或者读该变量的代码都是透明的。不像它的内嵌函数(译注:例子的add2,它是指外部函数add),声明变量的函数访问该变量就像访问它的local变量一样:直接到栈。
通过每个变量最多创建一个upvalue结构并且在必要的时候复用它们,可变状态得以在闭包之间正确地共享。为了保证这一约束,lua维持一个链表,里面是一个栈里(图4中的pending vars列表)的所有open upvalue(所谓open upvalue,是指仍然指向栈的upvalue结构)。当lua创建一个新的闭包的时候,它遍历所有的外部local变量。对于每个(外部local)变量,如果它在列表中找到一个open upvalue,那么它就复用这个upvalue结构。否则,lua就创建一个新的upvalue并将它放入链表。注意到列表搜索只是探测了少数几个节点,因为列表最多包含一个被内嵌函数使用的local变量的项。当一个closed upvalue不再被任何闭包引用的时候,它最后将被当作垃圾并回收。
一个函数允许访问一个不是它的直接外围函数的外部local变量,只要(这个local变量)是外部函数的(outer function)。在那种情况下,甚至在闭包被创建的时候,(外部local)变量可能就不在栈里了。Lua使用扁平闭包(flat closures)解决这种情况[5]。通过扁平闭包,一个函数无论何时去访问一个不属于它的外围函数的外部变量,这个变量都将进入外围函数的闭包。从而当一个函数被实例化的时候,所有进入它闭包的变量要么在外围函数的栈里面,要么在外围函数的闭包里。