hadoop2.6.0版本搭建伪分布式环境
由于个人需要在自己的笔记本上搭建hadoop伪分布环境,为了方便自己使用,如想看机器也看之前的一篇博客:hadoop2.6.0版本集群环境搭建
一台虚拟机,配置信息如下:
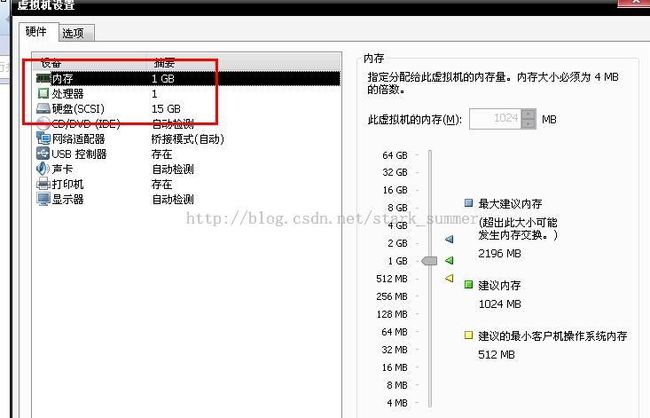
内存:1G,cpu:一个core,硬盘:15G
1、修改下主机名为master
sudo vi /etc/sysconfig/network

修改结果后:

重启电脑后再查看结果:
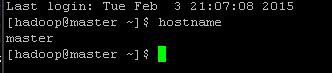
修改主机名成功
2、修改hosts中的主机名:


修改后:

3、配置SSH

进入.ssh目录并生成authorized_keys文件:

授权.ssh/文件夹权限为700,authorized_keys文件权限为600(or 644):

ssh验证:

4、hadoop安装:
去官网下载hadoop最新安装包:http://apache.fayea.com/hadoop/common/hadoop-2.6.0/
下载并解压后:

修改系统配置文件,修改~/.bash_profile文件,增加HADOPP_HOME的bin文件夹到PATH中,修改后使用source命令使配置文件生效:

在hadoop目录下创建文件夹:

接下来开始修改hadoop的配置文件,首先进入hadoop2.6配置文件夹:

第一步修改配置文件hadoop-env.sh,加入"JAVA-HOME",如下所示:

指定我们安装的“JAVA_HOME”:

第二步修改配置文件"yarn-env.sh",加入"JAVA_HOME",如下所示:

指定我们安装的“JAVA_HOME”:

第三步 修改配置文件“mapred-env.sh”,加入“JAVA_HOME”,如下所示:

指定我们安装的“JAVA_HOME”:

第四步 修改配置文件slaves,如下所示:

设置从节点为master,因为我们是伪分布式,如下所示:

第五步 修改配置文件core-site.xml,如下所示:

修改core-site.xml文件后:

目前来说,core-site.xml文件的最小化配置,core-site.xml各项配置可参考:http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-common/core-default.xml
第六步 修改配置文件 hdfs-site.xml,如下所示:

hdfs-site.xml文件修改后:

上述是hdfs-site.xml文件的最小化配置,hdfs-site.xml各项配置可参考:http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
第七步 修改配置文件 mapred-site.xml,如下所示:
copy mapred-site.xml.template命名为mapred-site.xml,打开mapred-site.xml,如下所示:
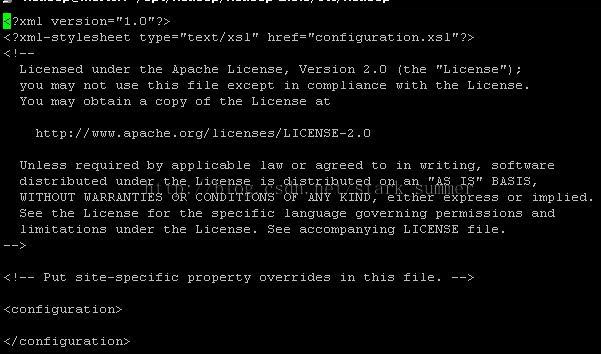
mapred-site.xml 修改后:

上述是mapred-site.xml最小化配置,mapred-site.xml各项配置可参考:http://hadoop.apache.org/docs/r2.6.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
第八步 配置文件yarn-site.xml,如下所示:

yarn-site.xml修改后:
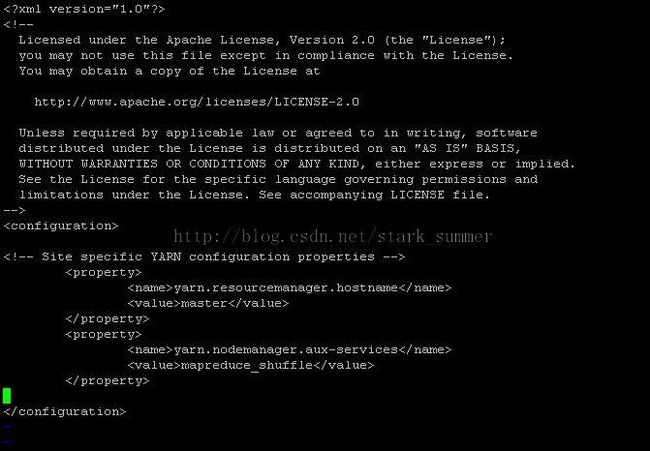
上述内容是yarn-site.xml的最小化配置,yarn-site文件配置的各项内容可参考:http://hadoop.apache.org/docs/r2.6.0/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
也可以增加spark_shuffle,配置如下
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
PS: 当提交hadoop MR 就启用,mapreduce_shuffle,当提交spark作业 就使用spark_shuffle,但个人感觉spark_shuffle 效率一般,shuffle是很大瓶颈,还有 如果你使用spark_shuffle 你需要把spark-yarn_2.10-1.4.1.jar 这个jar copy 到HADOOP_HOME/share/hadoop/lib下 ,否则 hadoop 运行报错 class not find exeception
5、启动并验证hadoop伪分布式
第一步:格式化hdfs文件系统:


第二步:进入sbin中启动hdfs,执行如下命令:

此刻我们发现在master上启动了NameNode、DataNode、SecondaryNameNode
此刻通过web控制台查看hdfs,http://master:50070/


点击“Live Nodes”,查看一下其信息:

第三步:启动yarn

使用jps命令可以发现master机器启动了ResourceManager进程
PS:我们上传一个文件到hdfs吧:

hadoop web控制台页面的端口整理:
50070:hdfs文件管理
8088:ResourceManager
8042:NodeManager
19888:JobHistory(使用“mr-jobhistory-daemon.sh”来启动JobHistory Server)