基于MeanShift的Camshift算法原理详解(opencv实现,有源码)
基于MeanShift的Camshift算法原理详解(整理)
第一篇MeanShift原理和实现
1 MeanShift原理
如下图所示:矩形窗口中的红色点代表特征数据点,矩形中的圆圈代表选取窗口。meanshift算法的目的是找到含有最多特征的窗口区域,即使圆心与概率密度函数的局部极值点重合,亦即使圆心与特征数据点最密集的地方中心尽量重合到一块。算法实现是通过向特征数据点密度函数上升梯度方向逐步迭代偏移至上升梯度值近似为零(到达最密集的地方)。

即在不改变选取局部窗口的情况下,通过给窗口一个向着特征数据点更密集的方向一个偏移向量,然后将偏移后的选取窗口作为当前选取窗口,根据选取窗口数据特征点密集情况给出一个一个向着特征数据点更密集的方向一个偏移向量……迭代偏移过程中,直到偏移向量的模值近似为零即可。
我们来分析一下上述过程:当选取窗口(圆形)由远靠近最密集点,再远离最密集点的过程中,圆形窗口中特征数据点的数量变化:理想情况下应是选取窗口包含的特征数据点越来越多,再到越来越少。(这个过程对应meanshift算法的基本形式,没有添加核函数时)
2 为什么要用概率密度函数的上升梯度呢?
概率密度函数可以表示大小不变的选取窗口中特征数据点的密度,我们要找的是概率密度最大的选取窗口,这样,我们只要使下一个选取窗口的概率密度函数值减去当前选取窗口的概率密度函数值大于0,就可以越来越靠近取窗口的概率密度函数的最大值,当下一个选取窗口与当前选取窗口非常接近时,就可以用概率密度梯度表示两窗口概率密度函数对应值的差,也就是说只要使选取窗口向概率密度函数梯度上升的方向偏移就可以在上升梯度值近似为零时取得概率密度函数的近似最大值。所以使用概率,是因为特征数据点本身是概率事件或说是标定与标准特征匹配程度的特征数据。
上面的分析的前提是默认选取窗口中的各个特征数据点的权值是相等的,但实际中各个特征数据点对最终判定是否为目标的影响是不一样的,这可以通过加权值函数(即meanshift扩展方法中的核函数)来实现。
3 添加的权值函数应满足什么条件呢?
对某一选取窗口的概率密度函数值=各个特征数据点的总和相当量除以窗口面积的相当量。
当选取窗口为全局窗口时,目标一定出现,即此范围内权值函数的各个值的总和归一化后一定为1。
为了便于比较和求概率密度函数的梯度,加权函数亦即核函数在自变量取值范围内的积分为1.
所以核函数应满足的条件:自变量范围内积分,值为1。
4 meanshift方法的适用范围及其优缺点

meanshift方法适合概率密度函数有极值且在某一局部区域内唯一,即选择的特征数据点能够较为明显的判定目标,亦即显著特征点。显然此方法,meanshift的基本形式不适合等概率特征点(即特征点是均匀分布)的情况。
1) meanshift算法,受初始值的影响很大,和经验相关。
2) 算法收敛的速度和程度很大程度上与选取的窗口有关,选取恰当的窗口非常重要。
3) 窗口选取的是否恰当很大程度上取决于目标(特征数据点的分布状况),这就是说此方法在处理一类目标时,还是很有效的,最起码跟踪同一目标,在窗口经过恰当的线性变换后,跟踪效果应该还是不错的。即概率密度函数的极值在自变量区域压缩或扩大的过程中,极值仍存在,仍可跟踪到目标。
4) meanshift算法若用于图割,则适用于:
已经建立标准的特征数据点集,且通过恰当的概率密度函数和核函数可以唯一的确定目标时,可以将目标从批量图片中分割,挑选出来,但是取出的结果显示为选取窗口中所有的内容,也就是说可能会有目标物之外的图像或缺失部分目标物。若选取窗口为目标物的轮廓,那将非常不错,也就意味着窗口模板要更新或目标轮廓是不变的(实际中不变几乎是不可能的),更新以为误差与误差的积累,也就是说进行批量分割时,效果是有限的。
5 meanshift 编程实现(opencv)
具体编程实现的时候meanshift算法思想其实很简单——利用概率密度的梯度爬升来寻找局部最优。它要做的就是输入一个在图像的范围,然后一直迭代(朝着重心迭代)直到满足你的要求为止。
例如在opencv中,实现过程:输入一张图像(imgProb),再输入一个开始迭代的方框(windowIn)和一个迭代条件(criteria),输出的是迭代完成的位置(comp )。
这是函数原型:
int cvMeanShift( const void* imgProb,CvRect windowIn,
CvTermCriteria criteria, CvConnectedComp* comp )
但是当它用于跟踪时,这张输入的图像就必须是反向投影图了。反向投影图实际上是一张概率密度图。经过反向投影时的输入是一个目标图像的直方图(也可以认为是目标图像),还一个输入是当前图像就是你要跟踪的全图,输出大小与全图一样大,它上像素点表征着一种概率,就是全图上这个点是目标图像一部分的概率。如果这个点越亮,就说明这个点属于物体的概率越大。
1)半自动跟踪思路:
输入视频,用画笔圈出要跟踪的目标,然后对物体跟踪。(用过opencv的都知道,这其实是camshiftdemo的工作过程)
第一步:选中物体,记录你输入的方框和物体。
第二步:求出视频中有关物体的反向投影图。
第三步:根据反向投影图和输入的方框进行meanshift迭代,由于它是向重心移动,即向反向投影图中概率大的地方移动,所以始终会移动到目标上。
第四步:然后下一帧图像时用上一帧输出的方框来迭代即可。
2)全自动跟踪思路:
输入视频,对运动物体进行跟踪。
第一步:运用运动检测算法将运动的物体与背景分割开来。
第二步:提取运动物体的轮廓,并从原图中获取运动图像的信息。
第三步:对这个信息进行反向投影,获取反向投影图。
第四步:根据反向投影图和物体的轮廓(也就是输入的方框)进行meanshift迭代,由于它是向重心移动,即向反向投影图中概率大的地方移动,所以始终会移动到物体上。
第五步:然后下一帧图像时用上一帧输出的方框来迭代即可。
(半自动和全自动的区别就是多了物体和背景的分离,特征提取部分)
附:后面的目标的跟踪例子是半自动的,即需要人手工选定一个目标。我正在努力尝试全自动的目标跟踪,希望可以和大家能在这方面与大家交流。![]()
总结:用meanshift进行跟踪最重要的一点是输入图像的把握,也就是要让它的迭代能越来越迭代到目标上。这种图像也不一定就是反向投影图,只要是一幅反映当前图像中每个像素点含有目标概率图就可以了,其实反向投影图就是这样的一幅图而已。
6 代码和效果图
代码参见请在此处下载点击打开链接
效果图分析:下图均为跟踪人皮肤肤色区域的效果,第一张图为只有人脸出现的时候,检测出人脸;第二张图为当人体其他部位出现时,跟踪的还是人脸部分,对比下面两个图可以发现,meanshift不具备自适应性,当和人脸肤色相近的身体部位出现时,不能自动调整检测区域(矩形框)的大小)。
补充:在调整过程中,发现:
1)当人脸移除时,检测失败,即使没有移除,在人脸运动过程中,若是人脸在视屏中所占的区域面积很小时,也会跟踪失败。
2)迭代速度体现不明显,事实上速度是和选取窗口有关的。当人脸移除时,跟踪区域切换到非肤色区域(即跟踪丢失),反应速度会稍微变慢。

第二篇CamShift的改进原理和实现(在meanshift基础上)
1 CamShift原理
CamShift(Continuously Apative Mean-Shift)算法,是一种运动跟踪算法。它主要通过视频图像中运动物体的颜色信息来达到跟踪的目的。
camshift利用目标的颜色直方图模型将图像转换为颜色概率分布图,初始化一个搜索窗的大小和位置,并根据上一帧得到的结果自适应调整搜索窗口的位置和大小,从而定位出当前图像中目标的中心位置。该算法分为三个部分:
1) Back Projection计算
2) Mean Shift算法
3) CamShift算法
具体实现是:
(反向投影:目标的颜色直方图模型将图像转换为颜色概率分布图)
2 算法步骤
2.1 色彩投影图(反向投影)
(1)RGB颜色空间对光照亮度变化较为敏感,为了减少此变化对跟踪效果的影响,首先将图像从RGB空间转换到HSV空间。
(2)然后对其中的H分量作直方图,在直方图中代表了不同H分量值出现的概率或者像素个数,就是说可以查找出H分量大小为h的概率或者像素个数,即得到了颜色概率查找表。
(3)将图像中每个像素的值用其颜色出现的概率对替换,就得到了颜色概率分布图。这个过程就叫反向投影,颜色概率分布图是一个灰度图像。
2.2 meanshift
meanshift算法是一种密度函数梯度估计的非参数方法,通过迭代寻优找到概率分布的极值来定位目标。算法过程为:
(1)在颜色概率分布图中选取搜索窗W
(2)计算零阶距:
计算一阶距:
计算搜索窗的质心:
(3)调整搜索窗大小:宽度为;长度为1.2s;
(4)移动搜索窗的中心到质心,如果移动距离大于预设的固定阈值,则重复2)3)4),直到搜索窗的中心与质心间的移动距离小于预设的固定阈值,或者循环运算的次数达到某一最大值,停止计算。
算法过程也可以描述如下:
(1) 选择搜索窗口
a.窗口的初始位置
b.窗口的类型(均匀、多项式、指数或者高斯类型)
c.窗口的形状(对称的或歪斜的,可能旋转的,圆形或矩形)
d.窗口的大小(超出宽口大小被截去)
(2) 计算窗口(可能是带权重的)的重心
(3) 将窗口的中心设置在计算出的重心处。移动搜索窗的中心到质心,如果移动距离大于预设的固定阈值,则重复2)3)4),直到搜索窗的中心与质心间的移动距离小于预设的固定阈值,或者循环运算的次数达到某一最大值,停止计算。
(4) 返回(2),直到窗口的位置不再变化(通常会变化,直至最后迭代收敛)
2.3 camshift
将meanshift算法扩展到连续图像序列,就是camshift算法。它将视频的所有帧做meanshift运算,并将上一帧的结果,即搜索窗的大小和中心,作为下一帧meanshift算法搜索窗的初始值。如此迭代下去,就可以实现对目标的跟踪。算法过程为:
(1) 初始化搜索窗
(2) 计算搜索窗的颜色概率分布(反向投影)
(3) 运行meanshift算法,获得搜索窗新的大小和位置。
(4) 在下一帧视频图像中用(3)中的值重新初始化搜索窗的大小和位置,再跳转到(2)继续进行。
camshift能有效解决目标变形和遮挡的问题,对系统资源要求不高,时间复杂度低,在简单背景下能够取得良好的跟踪效果。但当背景较为复杂,或者有许多与目标颜色相似像素干扰的情况下,会导致跟踪失败。因为它单纯的考虑颜色直方图,忽略了目标的空间分布特性,所以这种情况下需加入对跟踪目标的预测算法。
3 opencv实现
3.1 Back Projection计算步骤:
1)计算被跟踪目标的色彩直方图。在各种色彩空间中,只有HSI空间(或与HSI类似的色彩空间)中的H分量可以表示颜色信息。所以在具体的计算过程中,首先将其他的色彩空间的值转化到HSI空间,然后会其中的H分量做1D直方图计算。
2)根据获得的色彩直方图将原始图像转化成色彩概率分布图像,这个过程就被称作“Back Projection”。在OpenCV中的直方图函数中,包含BackProjection的函数,函数原型是:
void cvCalcBackProject(IplImage** img,CvArr** backproject, const CvHistogram* hist);
传递给这个函数的参数有三个:
1. IplImage** img:存放原始图像,输入。
2. CvArr** backproject:存放BackProjection结果,输出。
3. CvHistogram* hist:存放直方图,输入
3)下面就给出计算Back Projection的OpenCV代码。
(1)准备一张只包含被跟踪目标的图片,将色彩空间转化到HSI空间,获得其中的H分量:
IplImage*target=cvLoadImage("target.bmp",-1); //装载图片
IplImage* target_hsv=cvCreateImage(cvGetSize(target), IPL_DEPTH_8U, 3 );
IplImage* target_hue=cvCreateImage(cvGetSize(target), IPL_DEPTH_8U, 3 );
cvCvtColor(target,target_hsv,CV_BGR2HSV); //转化到HSV空间
cvSplit( target_hsv, target_hue, NULL,NULL, NULL ); //获得H分量
(2)计算H分量的直方图,即1D直方图:
IplImage* h_plane=cvCreateImage(cvGetSize(target_hsv),IPL_DEPTH_8U,1 );
int hist_size[]={255}; //将H分量的值量化到[0,255]
float* ranges[]={ {0,360}}; //H分量的取值范围是[0,360)
CvHistogram* hist=cvCreateHist(1,hist_size, ranges, 1);
cvCalcHist(&target_hue, hist, 0, NULL);
在这里需要考虑H分量的取值范围的问题,H分量的取值范围是[0,360),这个取值范围的值不能用一个byte来表示,为了能用一个byte表示,需要将H值做适当的量化处理,在这里我们将H分量的范围量化到[0,255]。
(3)计算Back Projection:
IplImage* rawImage;
//get from video frame,unsigned byte,onechannel
IplImage*result=cvCreateImage(cvGetSize(rawImage),IPL_DEPTH_8U,1);
cvCalcBackProject(&rawImage,result,hist);
(4)result即为我们需要的。
3.2 Mean Shift算法的质心计算:
(1)计算区域内0阶矩
for(int i=0;i< height;i++)
for(int j=0;j< width;j++)
M00+=I(i,j)
(2)区域内1阶矩:
for(int i=0;i< height;i++)
for(int j=0;j< width;j++)
{
M10+=i*I(i,j);
M01+=j*I(i,j);
}
(3)则Mass Center为:Xc=M10/M00; Yc=M01/M00
在OpenCV中,提供MeanShift算法的函数,函数的原型是:
int cvMeanShift(IplImage* imgprob,CvRectwindowIn, CvTermCriteria criteria,CvConnectedComp* out);
需要的参数为:
(1).IplImage* imgprob:2D概率分布图像,传入;
(2).CvRect windowIn:初始的窗口,传入;
(3).CvTermCriteria criteria:停止迭代的标准,传入;
(4).CvConnectedComp* out:查询结果,传出。
注:构造CvTermCriteria变量需要三个参数,一个是类型,另一个是迭代的最大次数,最后一个表示特定的阈值。例如可以这样构造 criteria:
criteria=cvTermCriteria(CV_TERMCRIT_ITER|CV_TERMCRIT_EPS,10,0.1)。
3.3 CamShift算法的具体步骤分5步:
Step 1:将整个图像设为搜寻区域。
Step 2:初始话Search Window的大小和位置。
Step 3:计算Search Window内的彩色概率分布,此区域的大小比Search Window要稍微大一点。
Step 4:运行MeanShift。获得Search Window新的位置和大小。
Step 5:在下一帧视频图像中,用Step 3获得的值初始化Search Window的位置和大小。跳转到Step 3继续运行。
在OpenCV中,有实现CamShift算法的函数,此函数的原型是:
cvCamShift(IplImage* imgprob, CvRectwindowIn,CvTermCriteria criteria,CvConnectedComp* out, CvBox2D* box=0);
其中:
imgprob:色彩概率分布图像。
windowIn:Search Window的初始值。
Criteria:用来判断搜寻是否停止的一个标准。
out:保存运算结果,包括新的Search Window的位置和面积。
box :包含被跟踪物体的最小矩形。总结如下:
Camshift算法的过程由下面步骤组成:
(1)确定初始目标及其区域;
(2)计算出目标的色度(Hue)分量的直方图;
(3)利用直方图计算输入图像的反向投影图(后面做进一步的解释);
(4)利用MeanShift算法在反向投影图中迭代收索,直到其收敛或达到最大迭代次数。并保存零次矩;
(5)从第(4)步中获得收索窗口的中心位置和计算出新的窗口大小,以此为参数,进入到下一帧的目标跟踪。(即跳转到第(2)步);
几点说明:
1. 在输入图像进行反向投影图之前在HSV空间内做了一个阀值处理,用以滤掉一些噪声。
2. 反向投影图则是概率分布图,在反向投影图中某一像素点的值指的是这个点符合目标的概率分布的概率是多少,或者直接说其为目标图像像素点的像素点是多少。计算方法为:根据像素点的像素值查目标的直方图,其对应像素值的概率是多少就作为该点在反向投影图中的值。
3.Camshit算法到底是怎样自适应调整窗口的大小的。扩大:Canshift算法在计算窗口大小前,在MeanShift算出的窗口的四个方向上增大了TOLERANCE,即高和宽都增大了2TOLERANCE(此值自己调整设置),这才有可能使得窗口能够变大。缩小:在扩大的窗口内重新计算0阶矩,1阶矩和2阶矩,利用矩的值重新计算高和宽。因此Camshif算法相当于在MeanShift的结果上,再做了一个调整,从而使得跟踪的窗口大小能够随目标的大小变化。
优点:算法的效率比较高,如果能利用多少特征做出来的统计直方图,我估计实验效果会更好。
缺点:(1)只利用颜色统计做的跟踪,在背景有相似颜色时,会出现跟踪错误的情况。(2)不能做多目标跟踪。(3)由于它只在初始位置(而不是从每个像素点)开始迭代,所以有可能在初始位置错了后,收敛的位置还是原位置(即跟丢了后,可能会找不回来)。
说明:有关于窗口大小调整,是根据直方图来迭代求解,在camshift函数中会有体现,可以查看其具体算法部分如下:
代码Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->CV_IMPL int
cvCamShift( const void* imgProb, CvRect windowIn,
CvTermCriteria criteria,
CvConnectedComp* _comp,
CvBox2D* box )
{
const int TOLERANCE = 10;
CvMoments moments;
double m00 = 0, m10, m01, mu20, mu11, mu02, inv_m00;
double a, b, c, xc, yc;
double rotate_a, rotate_c;
double theta = 0, square;
double cs, sn;
double length = 0, width = 0;
int itersUsed = 0;
CvConnectedComp comp;
CvMat cur_win, stub, *mat = (CvMat*)imgProb;
CV_FUNCNAME( "cvCamShift" );
comp.rect = windowIn;//初始化comp
__BEGIN__;
CV_CALL( mat = cvGetMat( mat, &stub ));
CV_CALL( itersUsed = cvMeanShift( mat, windowIn, criteria, &comp ));//调用meanshift计算质心
windowIn = comp.rect;//获得新的窗口的位置
//为了容错,窗口的四边都增大了TOLERANCE
windowIn.x -= TOLERANCE;
if( windowIn.x < 0 )
windowIn.x = 0;
windowIn.y -= TOLERANCE;
if( windowIn.y < 0 )
windowIn.y = 0;
windowIn.width += 2 * TOLERANCE;
if( windowIn.x + windowIn.width > mat->width )
windowIn.width = mat->width - windowIn.x;
windowIn.height += 2 * TOLERANCE;
if( windowIn.y + windowIn.height > mat->height )
windowIn.height = mat->height - windowIn.y;
CV_CALL( cvGetSubRect( mat, &cur_win, windowIn ));//获得指向子窗口的数据指针
/* Calculating moments in new center mass */
CV_CALL( cvMoments( &cur_win, &moments ));//重新计算窗口内的各种矩
m00 = moments.m00;
m10 = moments.m10;
m01 = moments.m01;
mu11 = moments.mu11;
mu20 = moments.mu20;
mu02 = moments.mu02;
if( fabs(m00) < DBL_EPSILON )
EXIT;
inv_m00 = 1. / m00;
xc = cvRound( m10 * inv_m00 + windowIn.x );//新的中心坐标
yc = cvRound( m01 * inv_m00 + windowIn.y );
a = mu20 * inv_m00;
b = mu11 * inv_m00;
c = mu02 * inv_m00;
/* Calculating width & height */
square = sqrt( 4 * b * b + (a - c) * (a - c) );
/* Calculating orientation */
theta = atan2( 2 * b, a - c + square );
/* Calculating width & length of figure */
cs = cos( theta );
sn = sin( theta );
rotate_a = cs * cs * mu20 + 2 * cs * sn * mu11 + sn * sn * mu02;
rotate_c = sn * sn * mu20 - 2 * cs * sn * mu11 + cs * cs * mu02;
length = sqrt( rotate_a * inv_m00 ) * 4;//长与宽的计算
width = sqrt( rotate_c * inv_m00 ) * 4;
/* In case, when tetta is 0 or 1.57... the Length & Width may be exchanged */
if( length < width )
{
double t;
CV_SWAP( length, width, t );
CV_SWAP( cs, sn, t );
theta = CV_PI*0.5 - theta;
}
/* Saving results */
//由于有宽和高的重新计算,使得能自动调整窗口大小
if( _comp || box )
{
int t0, t1;
int _xc = cvRound( xc );//取整
int _yc = cvRound( yc );
t0 = cvRound( fabs( length * cs ));
t1 = cvRound( fabs( width * sn ));
t0 = MAX( t0, t1 ) + 2;//宽的重新计算
comp.rect.width = MIN( t0, (mat->width - _xc) * 2 );//保证宽不超出范围
t0 = cvRound( fabs( length * sn ));
t1 = cvRound( fabs( width * cs ));
t0 = MAX( t0, t1 ) + 2;//高的重新计算
comp.rect.height = MIN( t0, (mat->height - _yc) * 2 );//保证高不超出范围
comp.rect.x = MAX( 0, _xc - comp.rect.width / 2 );
comp.rect.y = MAX( 0, _yc - comp.rect.height / 2 );
comp.rect.width = MIN( mat->width - comp.rect.x, comp.rect.width );
comp.rect.height = MIN( mat->height - comp.rect.y, comp.rect.height );
comp.area = (float) m00;
}
__END__;
if( _comp )
*_comp = comp;
if( box )
{
box->size.height = (float)length;
box->size.width = (float)width;
box->angle = (float)(theta*180./CV_PI);
box->center = cvPoint2D32f( comp.rect.x + comp.rect.width*0.5f,
comp.rect.y + comp.rect.height*0.5f);
}
return itersUsed;
}
opencv总代码参考可在此处下载点击打开链接
说明:跟踪人皮肤区域部分,当只露出人脸时,检测出人脸范围;露出皮肤时所有都检测出来。
这说明Camshift比效果好,验证了上面的说法——Camshift算法相当于在MeanShift的结果上,再做了一个调整,从而使得跟踪的窗口大小能够随目标的大小变化。
运行效果图:省去
(由于摄像头显示了本人图像,所以就不往这里粘贴了,大家可以自行运行,效果还是很不错的,第三篇Camshift应用于人脸检测
OpenCV的人脸追踪算法
Camshift(连续自适应的Meanshift算法)由以下四个步骤组成:
1 创建一个颜色直方图表示人脸特征;
2 对视频图像中每一帧的每一个像素进行计算“人脸存在的可能性”;
3 在每个视频帧中移动人脸矩形框的位置;
4 计算人脸的大小和角度。
下面是每一步骤的详细工作:
一创建一个表示人脸的Camshift直方图,它是以颜色值的直方图(或柱状图)来进行跟踪。图1是由装有OpenCV的Camshift的demo程序运行得到的两个直方图实例。每一个颜色条的高度表明了在一幅图像中有多少个像素点属于色度值。色度在HSV(色度、饱和度、值)颜色模型中用于描述一个像素的颜色。
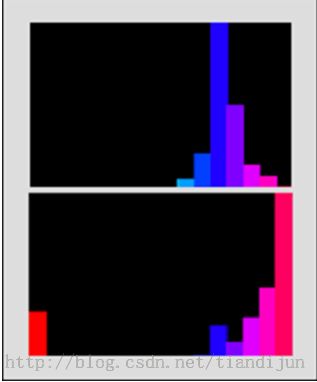
图 Camshift算法用于描述人脸的颜色直方图
顶部的直方图代表了一幅图像区域,蓝色的色调是最常见的,稍微薰衣草色调是下一个最常见的。底部直方图中最右边的值表示最常见的色度范围,这个色度经常但不总是红色。
二计算人脸概率
在初始跟踪时计算人脸概率的直方图只创建一次,在视频接下来的每一帧的处理中,该直方图被用于将人脸概率值分配给帧的每一个像素点。
“人脸概率”听起来非常复杂,计算也复杂,而实际上并非如此。现在我们给出它是如何工作的。图2表明直方图颜色条的叠加。很明显在该图像区域中叠加后最右边的颜色条大约占45%的像素。这意味着一个像素的随机选择落在最右边容器里的概率是45%,那是这一像素的“人脸概率”。同样的逻辑表明,下一个直方图容器所代表的人脸概率在20%左右,因为它大约占了总高度的20%。
当新的视频帧到达时,每一个像素点的色度值被检测,通过人脸直方图给该像素点赋人脸概率值。这个过程在OpenCV中被称为“直方图背景投影”。目前在OpenCV中有一个内置方法实现了它,那就是cvCalcBackProject()函数。
图3表示在通过Camshift算法跟踪我的脸时计算一个视频帧图像中可能存在人脸的图像。黑色像素概率值最低,白色像素概率最高,灰色的像素介于两者之间。
三在每个视频帧中移动人脸矩形框的位置
Camshift“改变”它的人脸位置判断,在可能存在人脸的图像中始终保持集中在高亮像素区域。它通过原先位置并计算一个矩形框中的人脸概率值来得出新位置,OpenCV中cvCamShift函数的功能是增强这些步骤来转变到一个新的位置。
这种和地球引力中心相一致的转换矩形的过程是基于Mean shift算法实现的,Mean shift算法由Comaniciu Dorin提出。事实上,Camshift算法就是“连续自适应的Mean shift算法”。
四、计算人脸大小和角度
Camshift算法被称为“持续自适应”,而不仅仅是“Mean shift(均值漂移)”,是因为它在每次计算人脸存在的矩形框的下一个位置时能够自动调整大小和角度。它选择的缩放值和初始方向是最符合face-probability的在新的矩形框位置的像素点。
原英文文章来源:http://www.cnblogs.com/seacode/archive/2010/09/28/1837694.html
代码还没有实现,抱歉,不能让大家看到效果图,若实现,愿共同交流,一起学习。