4.6 FlyWeight 享元模式
意图:
运用共享技术邮箱地支持大量细粒度的对象。
享元模式可以避免大量非常相似类的开销。在程序设计中,有时需要生成大量细粒度的类实例来表示数据。如果能发现这些实例除了几个参数外基本上都是相同的,有时就能够受大幅度地减少需要实例化的类的数量。如果能把那些参数移到类实例的外面,在方法调用时将它们传递进来,就可以通过共享大幅度地减少单个实例的数目。
在现实中什么时候才会应该考虑使用享元模式呢?如果一个应用程序使用了大量的对象,而大量的这些对象造成了很大的存储开销时就应该考虑使用;还有就是对象的大多数状态可以外部状态,如果删除对象的外部状态,那么可以用相对较少的共享对象取代很多组对象,此时可以考虑使用享元模式。
想想我们编辑文档用的wps,文档里文字很多都是重复的,我们不可能为每一个出现的汉字都创建独立的空间,这样代价太大,最好的办法就是共享其中相同的部分,使得需要创建的对象降到最小,这个就是享元模式的核心,即运用共享技术有效地支持大量细粒度的对象。
享元对象能做到共享的关键是区分内蕴状态(Internal State)和外蕴状态(External State)。内蕴状态是存储在享元对象内部并且不会随环境改变而改变。因此内蕴状态并可以共享。
外蕴状态是随环境改变而改变的、不可以共享的状态。享元对象的外蕴状态必须由客户端保存,并在享元对象被创建之后,在需要使用的时候再传入到享元对象内部。外蕴状态与内蕴状态是相互独立的。
UML图:
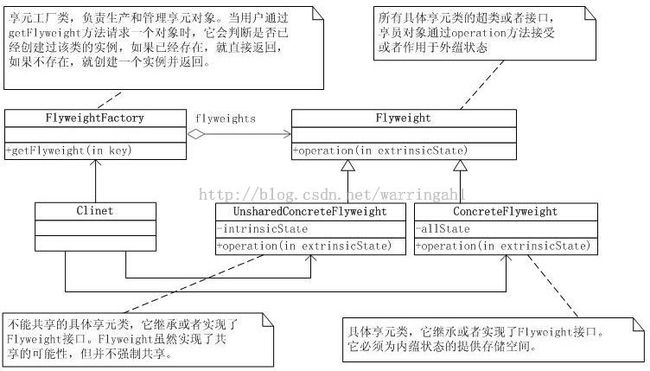
抽象享元类(Flyweight)
它是所有具体享元类的超类。为这些类规定出需要实现的公共接口,那些需要外蕴状态(Exte的操作可以通过方法的参数传入。抽象享元的接口使得享元变得可能,但是并不强制子类实行共享,因此并非所有的享元对象都是可以共享的。
具体享元类(ConcreteFlyweight)
具体享元类实现了抽象享元类所规定的接口。如果有内蕴状态的话,必须负责为内蕴状态提供存储空间。享元对象的内蕴状态必须与对象所处的周围环境无关,从而使得享元对象可以在系统内共享。有时候具体享元类又称为单纯具体享元类,因为复合享元类是由单纯具体享元角色通过复合而成的。
不能共享的具体享元类(UnsharableFlyweight)
不能共享的享元类,又叫做复合享元类。一个复合享元对象是由多个单享元对象组成,这些组成的对象是可以共享的,但是复合享元类本身并不能共享。
享元工厂类(FlyweightFactoiy)
享元工厂类负责创建和管理享元对象。当一个客户端对象请求一个享元对象的时候,享元工厂需要检查系统中是否已经有一个符合要求的享元对象,如果已经有了,享元工厂角色就应当提供这个已有的享元对象;如果系统中没有适当的享元对象的话,享元工厂角色就应当创建一个新的合适的享元对象。
客户类(Client)
客户类需要自行存储所有享元对象的外蕴状态。
仿照大话设计模式上的代码:
#include <iostream>
#include <hash_map>
#include <string>
using namespace std;
using namespace stdext;
class User
{
private:
string name;
public:
User(const string &name) : name(name){}
string GetName() const
{
return name;
}
};
class WebSite
{
public:
virtual void Use(User *user){}
};
class ConcreteWebSite : public WebSite
{
private:
string name;
public:
ConcreteWebSite(const string &name) : name(name){}
virtual void Use(User *user)
{
cout<<"网站分类:"<<name<<"用户:"<<user->GetName()<<endl;
}
};
class WebSiteFactory
{
private:
hash_map<string, WebSite*> flyweights;
public:
WebSite *GetWebSiteCategory(const string &key)
{
if (!flyweights.count(key)) {
flyweights[key] = new ConcreteWebSite(key);
}
return flyweights[key];
}
int GetCounter() const
{
return flyweights.size();
}
~WebSiteFactory()
{
hash_map<string, WebSite*>::const_iterator hashIter;
for (hashIter=flyweights.begin(); hashIter!=flyweights.end(); ++hashIter){
WebSite *pwebSite = hashIter->second;
if (pwebSite) {
delete pwebSite;
pwebSite = NULL;
}
}
}
};
int main(int argc, char **argv)
{
WebSiteFactory *f = new WebSiteFactory();
WebSite *fx = f->GetWebSiteCategory("产品展示");
fx->Use(new User("张三"));
WebSite *fy = f->GetWebSiteCategory("产品展示");
fy->Use(new User("李四"));
WebSite *fz = f->GetWebSiteCategory("产品展示");
fz->Use(new User("王五"));
WebSite *fl = f->GetWebSiteCategory("博客");
fl->Use(new User("赵六"));
WebSite *fm = f->GetWebSiteCategory("博客");
fm->Use(new User("钱七"));
WebSite *fn = f->GetWebSiteCategory("博客");
fn->Use(new User("孙八"));
cout<<"得到分类网站的总数为"<<f->GetCounter()<<endl;
system("pause");
return 0;
}
要点
1、面向对象很好的解决了抽象性的问题,但是作为一个运行在机器中的程序实体,我们需要考虑对象的代价问题。Flyweight设计模式主要解决面向对象的代价问题,一般不触及面向对象的抽象性问题。
2、Flyweight采用对象共享的做法来降低系统中对象的个数,从而降低细粒度对象给系统带来的内存压力。在具体实现方面,要注意对象状态的处理。
3、享元模式的优点在于它大幅度地降低内存中对象的数量。但是,它做到这一点所付出的代价也是很高的:享元模式使得系统更加复杂。为了使对象可以共享,需要将一些状态外部化,这使得程序的逻辑复杂化。另外它将享元对象的状态外部化,而读取外部状态使得运行时间稍微变长。
适用性
当以下所有的条件都满足时,可以考虑使用享元模式:
1、一个系统有大量的对象。
2、这些对象耗费大量的内存。
3、这些对象的状态中的大部分都可以外部化。
4、这些对象可以按照内蕴状态分成很多的组,当把外蕴对象从对象中剔除时,每一个组都可以仅用一个对象代替。
5、软件系统不依赖于这些对象的身份,换言之,这些对象可以是不可分辨的。
满足以上的这些条件的系统可以使用享元对象。最后,使用享元模式需要维护一个记录了系统已有的所有享元的表,而这需要耗费资源。因此,应当在有足够多的享元实例可供共享时才值得使用享元模式。
优缺点
享元模式的优点在于它大幅度地降低内存中对象的数量。但是,它做到这一点所付出的代价也是很高的:
1、享元模式使得系统更加复杂。为了使对象可以共享,需要将一些状态外部化,这使得程序的逻辑复杂化。
2、享元模式将享元对象的状态外部化,而读取外部状态使得运行时间稍微变长。