Struck Structured Output Tracking with Kernels阅读笔记
今天讲讲struck,最近感觉tracking的model进步是日新月异,比如大牛Dr. Chao Ma,最近在他的homepage:https://sites.google.com/site/chaoma99/
上传了他的2014年CVPR的code:long term correlation filter的codes。理论清晰,效果超好,这才是top research.
去年VOT比赛的冠军算法是DSST,基于correlation filter做的,今年的冠军我估计还是correlation filter的,基于Deep learing的方法,我估计。我今天读了一篇2013年VOT的冠军算法struck,感觉还是很有意思的。
因为这个算法给我一些启示,比如如何将object detection里面成熟的技术用到visual tracking中。诚然,像大牛Naiyan Wang说的那样,tracking落后于other CV domain很多年,像image classification, object detection,image segmentation等,所以"虚心地"借鉴这些领域的算法为tracking所用是很有意义的,扯远了。
这个算法说白了就是将object detection中用的structured SVM用到visual tracking,当然肯定不会这么一句话这么简单。
作者首先提出要解决什么问题:在tracking -by-detectio的方法中,我们都需要那正负样本来训练一个分类器。然后当新的一帧图像来了的时候,我们在上一帧预测的位置上
生成大量的candidates输入到里面,然后分类输出score,从中选择score最好的那个位置作为当前帧的位置。公式化就是:
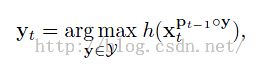 ----------------------1
----------------------1
Pt-1是上一帧的位置,y表示偏移量,于是我们获得的样本都可以看做是经过这样一个偏移y之后得到的,于是我们的分类器及时想找到一个最好的偏移量能够最大化这个目标函数,Y表示偏移量的范围,也即search space. 然后再次获取一些正负样本。这里有个问题就是,我训练分类器的时候,什么样的正负样本是"好“的正负样本,以前有方法是根据距离,越远的就label成负的,距离近的就是positive。第二个问题就是分类器的目标是为了正确的完成二分类,而我们tracking的目标是为了准确的估计target位置。怎么能统一这两个目的。
作者利用structured output SVM来实现visual tracking,因为作者看到已经有人讲structured output SVM应用到object detection当中了,并且采用online learning的方法,因为初始帧得到的样本太少了。整个model框架如下所示,下面带着上面说的两个问题,以及structured output SVM展开。

在这个框图中,作者要监督的学习label,半监督的学习样本,利用MIL来搞多种 特征。
第一,我们要得到好的正负样本,因为之前我们对样本贴标签的时候没有考虑transformation,第二是所有的样本看做了等权重啦训练SVM,然而有些负样本其实不是那么的负。很可能会对model产生不好的影响,比如drift。第三个问题是可能的噪声label。下面介绍怎么解决这个问题:
首先作者讲了一年传统的生成正负样本的方法:
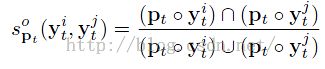 ----------------------------2
----------------------------2
在这里,Pt表示当前帧target的位置,yt表示估计出来的translation,于是对于两个样本(也就是两个bounding box)i,j,我们计算他们的重叠率:
![]()
作者定义了一个label函数l,如下所示:
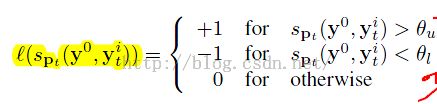 ------------------------3
------------------------3
其中y0可以看做是对target位置的0偏移,也就是不偏移。于是和现有位置重叠率大于阈值\theta_u的就看做是正样本而小于\theta_l的看做是负样本,说白了去掉一些不好的正负样本,就是让正样本更加正,负样本更加负。作者感觉这个方法无法自动估计这两个参数,太low了。于是放出了他的大招,我感觉我自己也没特别看懂,就凑合着说吧……
======================================
首先先祭出structured output SVM,作者说我们不去学习一个预测标签的分类器出来,我们学习一个能直接估计目标偏移量的函数出来,也就是说对于函数![]() y不再是正负一,而是或者正或者负的偏移量。这个一般的SVM搞不定,就得靠structured output SVM,
y不再是正负一,而是或者正或者负的偏移量。这个一般的SVM搞不定,就得靠structured output SVM,
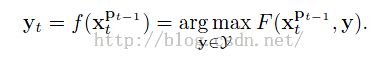 ------------------------------4,
------------------------------4,
比较公式4和公式1,发现我们这个时候目标函数包含了样本的标签y. 什么意思?根据机器学习算法,我们知道,这个y是可以学习的,也就是说样本的标签是可以学习的,我们就可以随着tracking的过程,不断的update 样本标签,就出现了这样的情形:在前几帧某个样本还看做是正样本,但是在最近一帧中被看做负样本。
这个F的物理意义是衡量(x,y)的兼容性。特别的,F写成:
![]() 。
。
其中\pha(x,y)是一个联合核map,用来从一些样本集合:![]()
![]() 中学出一个最大边际出来,目标函数如下:
中学出一个最大边际出来,目标函数如下:

OK,这个目标函数有了,如果让我讲他的物理意义,需要再学一遍SVM,所以pass.
然后就是对这个函数的解,各种优化方法(SMOSTEP)求解,先搞出对偶形式,然后搞优化迭代....由于在对偶形式可以用到核技巧,于是。。。。。
同时作者在update的时候考虑了三种update 策略:PROCESSNEW , PROCESSOLD 以及OPTIMIZE三种。
然而这个算法的一个缺点就是样本会无限制增长,于是作者采用budget方法来合并这些样本,实现的时候特征采用的Harr特征,毕竟是2013年,竟然用Harr没有用HoG,现在tracking不用HoG,就先输在起跑线了。
