模式识别-经典聚类方法
一、基于试探的聚类搜索算法(类别数由少到多)
1、按最邻近规则的简单试探法
基本思想:假设有N个样本{X1,X2...Xn},要求按距离阈值T分类到聚类中心{Z1,Z2,Z3…}
步骤:
step1:将第一个样本作为第一类的中心,Z1=X1.
step2:将剩下的样本计算||Xi-Z1 ||,若大于阈值T,则Xi作为新的一类的中心Z2.
step3:将剩余样本分别计算||Xi-Z1||,||Xi-Z2||,若||Xi-Z1||>T且||Xi-Z2||>T,则取Xi作为新的聚类的中心Z3。否则Xi属于距离Z1和Z2的较近者。
step4:按上述策略重复下去,直至将N个模式分类完毕。
优点:计算简单,若模式样本的集合分布的先验知识已知,则可获得较好的聚类结果。
缺点:在实际中,对于高维模式样本很难获得准确的先验知识,因此只能选用不同的阈值和起始点来试探,并对结果进行验证。
这种方法在很大程度上依赖于以下因素:
第一个聚类中心的位置(初始化问题)
待分类模式样本排列次序(聚类样本的选择问题)
距离阈值T的大小(判决准则问题)
样本分布的几何性质(样本的固有特性问题)
2、最大最小距离算法
基本思想:以试探类间欧式距离为最大作为预选出聚类中心的条件。
步骤:
step1:将第一个样本X1作为第一类的中心Z1.
step2:在剩余样本中选出距离X1最远的样本Xi作为第二类的中心Z2.
step3:计算剩余样本Xi距离Z1,Z2的较小者min(||Xi-Z1||,||Xi-Z2||),并取这些距离的最大值max。若max>C*||Z1-Z2||,则Xi为Z3,C为常量。若找不到,则聚类结束。若找到,则按上述规则继续找新的类。
step4:找到各类及其中心点后,剩余样本分配到最邻近的类。
结论:该算法的聚类结果与参数C和起始点Z1的选取关系重大。若无先验样本分布知识,则只有试探法通过多次试探优化,若有先验知识用于指导C和Z1选取,则算法可以很快收敛。
二、系统聚类法(类别数从多到少)
基本思想:先把每个样本作为一类,然后根据它们间的相似性或相邻性聚合,类别由多到少,直到获得合适的分类要求为止;相似性、相邻性用距离表示。聚合的关键就是每次迭代中形成的聚类之间以及它们和样本之间距离的计算,不同的距离函数会得到不同结果。
步骤:
step1:设初始模式样本共有n个,每个样本自成一类,即建立n类,G1(0),G2(0),G3(0),...,Gn(0)。计算各类之间的距离(初始时即为各样本间的距离),得到一个n*n维的距离矩阵D(0)。这里,标号(0)表示聚类开始运算前的状态。
step2:假设前一步聚类运算中已求得距离矩阵D(n),n为逐次聚类合并的次数,则求D(n)中的最小元素。如果它是Gi(n)和Gj(n)两类之间的距离,则将Gi(n)和Gj(n)两类合并为一类Gij(n+1),由此建立新的分类:G1(n+1),G2(n+1),...,Gl(n+1)。
step3:计算合并后新类别之间的距离,得D(n+1)。计算与其它没有发生合并的之间的距离,可采用多种不同的距离计算准则进行计算。
step4:返回step2,重复计算及合并,直到得到满意的分类结果。(如:达到所需的聚类数目,或D(n)中的最小分量超过给定阈值D等。)
注:距离计算准则
进行聚类合并的一个关键就是每次迭代中形成的聚类之间以及它们和样本之间距离的计算,采用不同的距离函数会得到不同的计算结果。
主要的距离计算准则:
–最短距离法
–最长距离法
–中间距离法
–重心法
–类平均距离法
聚类准则函数:




三、动态聚类法
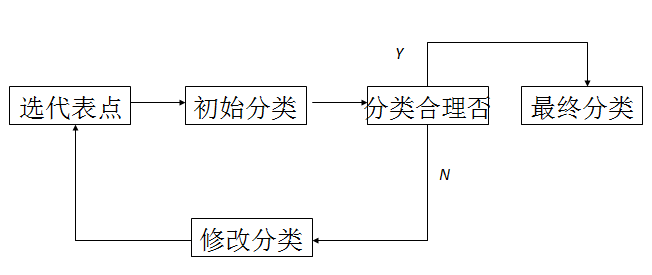
首先选择若干个样本点作为聚类中心,再按某种聚类准则(通常采用最小距离准则)使样本点向各中心聚集,从而得到初始聚类,然后判断初始分类是否合理。若不合理,则修改分类,如此反复进行修改聚类的迭代算法,直到合理为止。以下为动态聚类框图
1、k-均值聚类
将给定的样本划分为K类,K预先指定。
基本思想:基于使聚类性能指标最小化,所用的聚类准则函数是聚类集中每一个样本点到该类中心的距离平方之和,并使其最小化。
步骤:
step1.为每个聚类确定一个初始聚类中心,这样,就有K个初始聚类中心。
step2.将样本集中的样本Xi按照最小距离原则分配到最邻近聚类Zj
step3.使用每个聚类中的样本均值作为新的聚类中心。
step4.重复步骤2.3直到聚类中心不再变化。
step5.结束,得到K个聚类。
缺点:必须指定聚类的个数,这个有些时候并不太行得通。算法需要确定初始随机种子点,不同的初始种子点选取会造成不同的分类结果。
这种方法很大程度依赖于以下因素:
所选聚类的数目
聚类中心的初始分布
模式样本的几何性质
读入次序
2、ISODATA算法
基本思想:
(1)选择某些初始值,可选不同参数指标,也可在迭代过程中人为修改,以将N个模式样本按指标分配到各个聚类中心中去。
(2)计算各类中诸样本的距离指标函数
(3)-(5)按给定的要求,将前一次获得的聚类集进行分裂和合并处理((4)为分裂处理,(5)为合并处理),从而获得新的聚类中心。
(6)重新进行迭代运算,计算各项指标,判断聚类结果是否符合要求,经过多次迭代后,若结果收敛,则运算结束。
步骤:
step1:初始化
设定控制参数:
c:预期的类数;
Nc:初始聚类中心个数(可以不等于c);
TN:每一类中允许的最少样本数目(若少于此数,就不能单独成为一类);
TE:类内各特征分量分布的相对标准差上限(大于此数就分裂);
TC:两类中心间的最小距离下限(若小于此数,这两类应合并);
NT:在每次迭代中最多可以进行“合并”操作的次数;
NS:允许的最多迭代次数。
选定初始聚类中心
step2:按最近邻规则将样本集{xi}中每个样本分到某一类中。
step3:依据TN判断合并:如果类ωj中样本数nj< TN,则取消该类的中心zj,Nc=Nc-1,转至② 。
step4:计算分类后的参数:各类重心、类内平均距离dj及总体平均距离d
计算各类的重心;
计算各类中样本到类心的平均距离dj;
计算各个样本到其类内中心的总体平均距离d;
step5:判断停止、分裂或合并。
a、若迭代次数Ip =NS,则算法结束;
b、若Nc ≤c/2,则转到step6 (将一些类分裂);
c、若Nc ≥2c,则转至step7(跳过分裂处理);
d、若c/2< Nc<2c,当迭代次数Ip是奇数时转至step6 (分裂处理);迭代次数Ip是偶数时转至step7 (合并处理)。
step6:分裂操作
计算各类内样本到类中心的标准差向量
σj=(σ1j, σ2j,…., σnj)T , j=1,2,…..,Nc
计算其各个分量。
求出每一类内标准差向量σj中的最大分量σjmax
若有某一类中最大分量大于TE,同时又满足下面两个条件之一:
a、 dj>d 和 nj>2(TN+1)
b、Nc≤c/2
则将该类ωj分裂为两个类,原zj取消且令Nc=Nc+1。
两个新类的中心zj+和zj-分别是在原zj中相应于 σjmax的分量加上和减去kσjmax ,而其它分量不变,其中0<k≤1。
分裂后,Ip=Ip+1, 转至step2。
step7:合并操作
计算各类中心间的距离Dij,i=1,2,…,Nc-1; j=1,2,…,Nc
依据TC判断合并。将Dij与TC比较,并将小于TC的那些Dij按递增次序排列,取前NT个。
从最小的Dij开始,将相应的两类合并,并计算合并后的聚类中心。
在一次迭代中,某一类最多只能合并一次。
Nc=Nc-已并掉的类数。
step8:如果迭代次数Ip=NS或过程收敛,则算法结束。否则,Ip=Ip+1,若需要调整参数,则转至step1;若不改变参数,则转至step2;
具体算法讲解可查看中科院模式识别视频。