结构化查询语言
1、什么是SQL?
简介:SQL(Structure Query Language)官方为各关系型数据库规定的统一的结构化查询语言,是数据库的核心语言, 具有操作所有关系型数据库管理系统的能力。但是各个品牌的数据库各自具有一些其他数据库不具备的功能或沿袭下来的语法,相当于普通话规定之外的方言。例如MySQL中的LIMIT语句就是MySQL独有的方言,其它数据库都不支持,当然,Oracle或SQL Server 也都有自己的方言。
语法要求:SQL语句可以单行或多行书写,以分号结尾;可以用空格和缩进来来增强语句的可读性;关键字不区别大小写,建议使用大写。
分类:DDL、DML、DCL、DQL(DQL也可以归入到DML中)。
2、DDL(Data Definition Language)
数据定义语言,用来定义数据库对象:库、表、列等。
(1)对数据库的操作
● 查看所有数据库名称:show databases;
● 切换数据库(进入数据库):USE mydb1,切换到mydb1数据库;
● 创建数据库:CREATE DATABASE [IF NOT EXISTS] mydb1;
例:CREATE DATABASE mydb1,创建一个名为mydb1的数据库。如果这个数据已经存在,那么会报错。例如CREATE DATABASE IF NOT EXISTS mydb1,表示在名为mydb1的数据库不存在时创建该库,这样可以避免报错。
● 删除数据库:DROP DATABASE [IF EXISTS] mydb1;
例:DROP DATABASE mydb1,删除名为mydb1的数据库。如果这个数据库不存在,那么会报错。DROP DATABASE IF EXISTS mydb1,就算mydb1不存在,也不会报错。
● 修改数据库编码:ALTER DATABASE mydb1 CHARACTER SET utf8;
修改数据库mydb1的编码为utf8。注意,在MySQL中所有的UTF-8编码都不能使用中间的“-”,即UTF-8要书写为UTF8。
(2)mysql中的数据类型
MySQL与Java一样,也有数据类型,MySQL中数据类型主要应用在列上。
整型:

字符串:

二进制:

浮点型、布尔型、日期时间型:

(3)对表的操作
● 创建表
create table 表名称(列名 列类型, 列名 列类型, ...),例:<span style="font-size:18px;">CREATE TABLE stu( sid CHAR(6), sname VARCHAR(20), age INT, gender VARCHAR(10) );</span>
● 查看当前数据库中所有表名称:show tables;
● 查看指定表的创建语句:SHOW CREATE TABLE emp,查看emp表的创建语句;
● 查看表结构:desc 表名;
● 删除表:DROP TABLE emp,删除emp表;
● 修改表:前缀:alter table 表名
● 修改之添加列:add(列名 列类型, 列名 列类型, ...);
例:给stu表添加classname列:
ALTER TABLE stu ADD (classname varchar(100));
● 修改之修改列类型:modify 列名 新类型
例:修改stu表的gender列类型为CHAR(2):
ALTER TABLE stu MODIFY gender CHAR(2);
● 修改之修改列名:change 老列名 新列名 新类型
例:修改stu表的gender 列名为sex:
ALTER TABLE stu change gender sex CHAR(2);
● 修改之删除列:drop 列名
例:删除stu表的classname列:
ALTER TABLE stu DROP classname;
● 修改之修改表名称:rename to 新表名
例:修改stu表名称为student:
ALTER TABLE stu RENAME TO student;
2、DML(Data ManipulationLanguage)
数据操作语言,用来定义数据库记录(数据);它的操作是针对表记录的操作(ddl会改变表记录),注意字符串常量必须使用单引号,而不是双引号。
(1)插入记录
语法:INSERT INTO 表名(列名1,列名2, …) VALUES(值1, 值2)
例:INSERT INTO stu(sid, sname,age,gender) VALUES('s_1001','zhangSan', 23, 'male');
INSERT INTO stu(sid, sname) VALUES('s_1001', 'zhangSan');(因为没有插入age和gender列的数据,所以该条记录的age和gender值上为NULL);
若插入所有列,那么列名可以省略,值的顺序按创建表时表的顺序。
(2)修改记录
语法:UPDATE 表名 SET 列名1=值1, … 列名n=值n [WHERE 条件]
例:UPDATE stu SET sname=’zhangSanSan’, age=’32’, gender=’female’ WHERE sid=’s_1001’;
UPDATE stu SET gender=’female’ WHERE gender IS NULL;
注意:
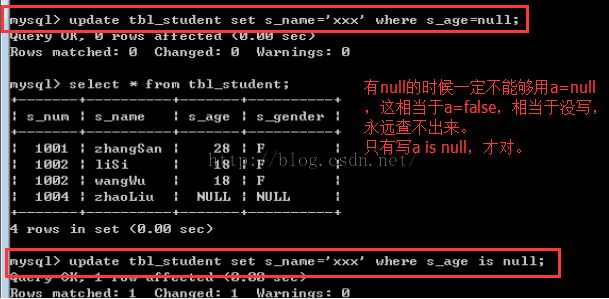
(3)删除记录
语法:DELETE FROM 表名 [WHERE 条件]
例:DELETE FROM stu WHERE sid=’s_1001’;
delete from tbl_student where s_age is null
truncate table 表名:删除所有记录(DDL)(不能回滚)
虽然TRUNCATE和DELETE都可以删除表的所有记录,但有原理不同。DELETE的效率没有TRUNCATE高!delete每删除一行就会在日志中记录一行,而truncate没有任何记录,所以不能回滚。TRUNCATE其实属性DDL语句,因为它是先DROP TABLE,再CREATE TABLE(而delete是一行一行的删除)。
3、DCL(Data Control Language)
数据控制语言,用来定义访问权限和安全级别;
(1)创建用户
语法:CREATE USER 用户名@地址 IDENTIFIED BY '密码';
例:CREATE USER user1@localhost IDENTIFIED BY ‘123’;(user1用户只能在localhost这个IP登录mysql服务器)
CREATE USER user2@’%’ IDENTIFIED BY ‘123‘;(user2用户可以在任何电脑上登录mysql服务器)
(2)给用户授权
语法:GRANT 权限1, … , 权限n ON 数据库.* TO 用户名;
例:GRANT CREATE,ALTER,DROP,INSERT,UPDATE,DELETE,SELECT ON mydb1.* TO user1@localhost;(把数据库 mydb1的CREATE,ALTER,DROP,INSERT,UPDATE,DELETE,SELECT权限授予给本地用户user1)
GRANT ALL ON mydb1.* TO user2@localhost;(把数据库mydb1的所有操作权限授予给user2)
(3)撤消权限
语法:REVOKE权限1, … , 权限n ON 数据库.* FORM 用户名@'IP地址'
例:REVOKE CREATE,ALTER,DROP ON mydb1.* FROMuser1@localhost;
(4)查看权限
语法:SHOW GRANTS FOR用户名
例:SHOW GRANTS FOR user1@localhost;(5)删除用户
语法:DROP USER 用户名
例:DROP USER user1@localhost;
(6)修改用户名密码
语法:USE mysql;(进入权限所在数据库)
UPDATE USER SETPASSWORD=PASSWORD(‘密码’) WHERE User=’用户名’ and Host=’IP’;(修改)
FLUSHPRIVILEGES;(更新)
例:UPDATE USER SET PASSWORD=PASSWORD('1234') WHERE User='user2'and Host=’localhost’;FLUSHPRIVILEGES;
4、DQL(Data Query Language)
数据查询语言,用来查询记录(数据),数据库执行DQL语句不会对数据进行改变,而是让数据库发送结果集给客户端。
(1)基础查询
● 查询所有列:select * from 表名;
(2)条件查询
条件查询就是在查询时给出WHERE子句,在WHERE子句中可以使用如下运算符及关键字:
=、!=、<>、<、<=、>、>=;
BETWEEN…AND;
IN(set);
IS NULL;
AND;
OR;
NOT;
● 查询指定列:select 列名,列名,... from 表名。
例:select ename, sal from emp;
● distinct:去除完全相同的行
例:SELECT DISTINCT job FROM emp:查询job列,再去除完全重复行!
● 列运算:列还可以做四则运算!
例:select sal*0.8 from emp;
● ifnull(列名, 期望值):ifnull(comm, 0):当comm这一列上出现null时,把null当成0。
例:SELECT ename, sal+IFNULL(comm, 0) FROM emp;(如果comm列为null,那么默认值为0)
● 给列起别名:as 别名(as可省略)
例: SELECT ename, sal+IFNULL(comm, 0) [as] salary FROM emp;
● 连接字符串:concat('', '')
例: SELECT CONCAT('我叫', ename) FROM emp;
(3)模糊查询
模糊查询需要使用关键字LIKE,其下标记符有:
下划线(_):匹配一个任意字符
百分号(%):匹配0~N个任意字符
例:查询2001年入职的员工:select * from emp where hiredate like '2001%'
(4)排序
● 关键字:order by,其下标记符:
asc:升序,可以省略asc
desc:降序
● 单列排序:order by 列名 asc 或 desc
● 多列排序:第一列如果相同,那么才会使用第二列进行排序!
order by 第一列 asc或desc, 第二列 asc或desc
例:SELECT * FROM emp ORDER BY sal ASC, comm DESC:使用sal的升序进行排序,如果sal相同,那么使用comm的降序排序
(5)聚合函数(纵向运算)
聚合函数是用来做纵向运算的函数:
COUNT():统计指定列不为NULL的记录行数;
MAX():计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
MIN():计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
SUM():计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
AVG():计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
● count():计数:
select count(*) from emp:计算有效行!一行上所有列都为null表示无效行!
例:select count(comm) from emp:计算指定列的有效行,如果这一列上为null值,表示无效行!
● sum():求和
例:select sum(sal) from emp:计算sal这一列所有值的和
● max():最大
例:select max(sal) from emp;
● min():最小例:select min(sal) from emp;
● avg():平均
例:select avg(sal) from emp;
(6)分组查询
当需要分组查询时需要使用GROUP BY子句,例如查询每个部门的工资和。
例:SELECT job, COUNT(*), MAX(sal), MIN(sal), AVG(sal), SUM(sal) FROM emp GROUP BY job;
having:分组后的条件,条件中带有聚合函数就是分组后条件!
注意:WHERE是对分组前记录的条件,如果某行记录没有满足WHERE子句的条件,那么这行记录不会参加分组;而HAVING是对分组后数据的约束。
(7)limit(分页)
LIMIT用来限定查询结果的起始行,以及总行数,只在mysql中存在。
语法:limit n,m;
limit后两个整数
n:从第几行开始查询(第一行叫第0行)
m:一共查询几行记录(如果不足指定的行,那么有几行显示几行)
例:select * from emp limit 0, 3
