事务策略: API 层策略
不论您是在 EJB 2.1 或 3.0 中使用容器环境,还是使用 Spring Framework 环境,或者是 Tomcat 和 Jetty 等带有 Java Open Transaction Manager (JOTM) 的 Web 容器环境,都需要一种事务策略来确保数据库的一致性和完整性。Java Transaction API (JTA) 指定了与事务处理有关的语法和接口,但是并没有描述如何将这些构建块组合起来。正如建筑工人需要根据一张设计图来将一堆木材建造成一栋房子一样,您需要一种策略来描述如何 将事务构建块组合在一起。
我将在本文介绍的策略名为 API Layer 事务策略 。它是最健壮、最简单并且是最容易实现的事务策略。但是其简单性也带来了一些限制和一些需要考虑的因素,我将对此加以解释。我在代码示例中使用 EJB 3.0 规范;同样的概念也适用于 Spring Framework 和 JOTM。
基本结构
API Layer 事务策略的命名基于这样一个事实:所有事务逻辑包含在逻辑应用程序架构的 API 层。这个层是一个逻辑层 — 有时也被称为应用程序的域层(domain layer) 或 facade 层 ,它以公共方法或接口的形式向客户机(或表示层)公开功能。之所以说是逻辑 层,是因为可以从本地访问域层(通过直接实例化和调用),或通过 HTTP、远程方法调用(RMI)、通过 EJB 使用 RMI over Internet Inter-Orb Protocol (RMI-IIOP),甚至通过 Java Message Service (JMS) 进行远程访问。
图 1 展示了大多数 Java 应用程序的典型逻辑应用程序层堆栈:
图 1. 架构层和事务逻辑
图 1 中的架构实现了 API Layer 事务策略。包含事务逻辑的类使用红色背景表示。注意,这些只包含应用程序架构的域类(API 层)。客户机层、业务层和表示层没有包含事务逻辑,意味着这些层并不能开始、提交或回滚事务,也不会包含事务注释,比如 EJB 3.0 中的 @TransactionAttribute 注释。整个应用程序架构中用于启动、提交和回滚事务的惟一方法就是 API 层的域类中包含的公共方法。这就解释了为什么 API 层是最健壮、最简单的事务策略。
不要局限在图 1 所示的 4 个层上。应用程序架构可以包含更多的层,也可能包含比这更少的层。可以将表示层和域层结合放到单个 WAR 文件中,或将域类单独放到一个 EAR 文件中。您可能将域类中包含的业务逻辑作为一个层,而不是两个。这都不会影响事务策略的工作方式或实现方式。
这个事务策略非常适合拥有粗粒度 API 层的应用程序。并且由于表示层并未包含任何事务逻辑(甚至更新请求),因此此策略非常适合那些必须支持多客户机通道的应用程序,包括 Web 服务客户机、桌面客户机和远程客户机。但是这种灵活性需要付出一定代价 — 即客户机层仅限于对给定事务工作单元的单一请求。我将在本文后面解释这一限制的必要性。
策略设置和特征
以下规则和特征将应用到 API Layer 事务策略:
- 只有包含在应用程序架构的 API 层中的公共方法包含事务逻辑。其他方法、类或组件都不应包含事务逻辑(包括事务注释、编程式事务逻辑和回滚逻辑)。
- API 层中的所有公共写方法(包括插入、更新和删除)都应当使用事务属性
REQUIRED加以标记。 - API 层中的所有公共写方法(包括插入、更新和删除)都应当包含回滚逻辑,以标记对检查出的异常执行回滚的事务。
- API 层中的所有公共读方法默认情况下都应使用事务属性
SUPPORTS加以标记(参见 “事务策略:了解事务陷阱 ” 中的 事务策略:了解事务陷阱 侧边栏内容)。这将确保在一个事务范围的上下文内调用读方法时,该方法被包括在事务范围内。否则,它将在事务上下文之外运行,并假设它是惟一一个在逻辑工 作单元(LUW)内得到调用的方法。我在这里假设这个读操作(作为 API 层的入口点)不会反过来对数据库调用写操作。 - API 层的事务将传播到在事务所有者 内调用的所有方法(如 下一小节 定义的那样)。
- 声明式事务(Declarative Transaction)模型通常用于这种模式,并假设 API 层类由一个 Java EE 容器环境管理,或由另一个框架(比如 Spring)管理。如果不是这样的话,那么很可能需要使用编程式事务(Programmatic Transaction)模型。(参见 “Transaction strategies: Models and strategies overview ” 了解更多有关这些事务模型的信息)。
根据上面列出的几条规则,如果您仔细观察的话,可能会注意到这个策略有些小问题。由于执行服务之间的通信,一个公共 API 层更新方法可以调用另一个公共 API 层更新方法。由于这两个更新方法都是公共方法,并且从客户机层的角度看被公开为 API 层入口点,因此它们包含了回滚逻辑。然而,如果其中一个公共更新方法调用了另一个,那么事务所有者在某些情况下可能无法控制回滚逻辑。因此,事务所有者在 重新提交事务或采取纠正操作时,必须万分小心。遇到这些情况时,需要重新构造结构和处理逻辑以避免发生此类问题。
限制和约束
事务策略的其中一个限制,就是客户机层(或表示层)类对任何给定事务工作单元只能发出单一的 API 层调用。这使得这种策略不太适合 “聊天” 应用程序。不幸的是,这是一种全有或全无(all-or-nothing)式的思想,并且在某些情况下需要对应用程序进行重构(本节后面将详述)。让我解 释一下它对事务策略的重要性(和必要性)。
我将对整个事务策略 系列中描述的所有事务策略应用的两条黄金法则(秘诀)是:
- 启动事务的方法被指定为事务所有者
- 只有事务所有者可以回滚事务
如果不遵守这些法则的话,事务策略将不能正常工作。您很可能会遇到问题,导致不一致的数据和糟糕的数据完整性。第二条法则非常重要,原因有两 点。首先,如果某个方法没有启动事务,那么它就不需要管理事务(例如,将其标记为回滚)。其次,如果调用链中较低级别的方法调用回滚事务,那么事务所有者 不能采取纠正操作来修复并重新提交事务;一旦被标记为回滚,那么这是惟一可能的结果。您无法对事务 “撤销回滚”。
回到原点:对于 API 层事务策略,客户机绝对 不能在涉及事务的单一工作单元中对 API 层发出多个调用。如果客户机对给定的 LUW 发出多个 API 调用,那么必须在客户机启动和终止事务工作单元。在这种情况下,API 层方法必须拥有一个事务属性 MANDATORY ,而不应包括任何回滚逻辑。记住刚才的两条黄金法则:调用 API 层方法的客户机方法是事务所有者,只有事务所有者才负责执行回滚。
考虑图 2 所示的例子,其中一个客户机(客户机 A)向 API 层(域模型)发出一个请求,请求将一个股票交易插入到数据库:
图 2. 使用 MANDATORY 属性
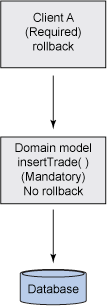
在这种情况下,客户机启动事务;因此使用 REQUIRED 事务属性。注意客户机还负责执行回滚,遵守刚才提到的两条黄金法则。域类属性有一个事务属性 MANDATORY ,因为客户机正在启动事务,而域模型(insertTrade() )不负责执行回滚。
该策略适合图 2 所示的场景。然而,假设您有另一个客户机应用程序(客户机 B)需要使用同一个域模型(insertTrade() ),如图 3 所示:
图 3. 非事务性客户机问题
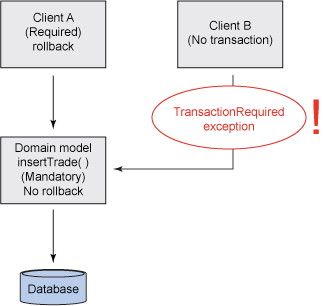
注意,客户机 B 并没有启动事务(它可以是一个远程 HTTP 客户机、消息传递客户机、或其他无法使用事务的 Java 应用程序)。由于域模型方法被标记为 MANDATORY ,客户机 B 将得到一个 TransactionRequiredException ,表示事务需要调用该方法。
如果没有提供合适的事务策略,那么通常解决此问题的办法就是将域模型(insertTrade() )中的事务属性修改为 REQUIRED 。现在,如果返回到客户机 A 的调用,将注意到您并没有影响到任何内容;客户机 A 启动了一个事务,然后将事务上下文传递给域模型方法。由于域模型方法现在被标记为 REQUIRED ,因此它将使用现有的事务上下文。注意,域模型方法并没有包含回滚逻辑。执行了域模型后(不管是否出现异常),控制权将返回给客户机。这些操作都可以在客户机 A 中正确地执行。然而,如果观察一下客户机 B,则出现了一个问题:由于没有提供任何事物上下文,域模型方法(insertTrade() )启动了一个新事务,但是在出现被检测到的异常后,由于域模型方法不负责执行回滚,因此没有执行任何回滚。图 4 解释了这一错误条件:
图 4. 使用 REQUIRED 属性而未执行回滚

在为提供合适事务策略的情况下,解决这一问题的惯用方法是向域模型方法添加回滚逻辑,以满足来自客户机 B 的调用。然而,如图 5 所示,这将在客户机 A 中引发问题:
图 5. 客户机回滚问题

客户机 A 在尝试回滚事务时,不仅会收到一个异常,而且客户机 A 还不能采取纠正操作,因为事务已经被标记为回滚。
如此反复……
这解释了事务策略为什么如此重要,以及为什么它们必须是绝对的。如前所述,您会发现对于 LUW 请求,应用程序使用 85% 的单 API 层调用和 15% 的多 API 层调用。如果是这样的话(或类似的情形),那么有两种选择:不要协调事务工作单元中的多个调用(这不是个好主意),或者(更好的方法)是使用一个聚合 API 层方法将多个 API 调用重构为一个单一的 API 调用。
为了解释这种重构技巧,我假设您拥有两个 API 层方法 insertTrade() 和 updateAcct() ,如清单 1 所示:
清单 1. 多个 API 层方法
|
假设这些方法都可以作为独立的操作运行。然而,如清单 2 所示,很多时候客户机可以在相同的 LUW 中同时调用这两种方法:
清单 2. 在同一个客户机方法中执行多个表更新
|
在这里,并没有将事务放在客户机层而搞乱所有内容,更好的办法是通过在 TradingServiceImpl 类和相应的 TradingService 接口中创建新的聚合方法来移除多 API 层调用。清单 3 展示了这个新的聚合方法(为简单起见,没有显示接口代码):
清单 3. 添加一个公共聚合方法
|
重构后的客户机代码如清单 4 所示:
清单 4. 重构后的客户机代码只发出一个 API 层调用
|
注意,客户机方法现在对名为 placeTrade() 的 API 层中的新聚合方法发出了一个调用。insertTrade() 和 updateAcct() 方法仍然是公共方法,因为它们可以彼此独立调用,而不用考虑新的聚合方法。
尽管我使用了一个简单的示例进行说明,但是我并没有要刻意忽略这项重构技巧的复杂性。在某些情况下(特别是使用 HTTPServletRequest 或 HTTPSession 等基于 Web 的对象的客户机代码)重构可以非常复杂并涉及到大量的代码修改。您需要在重构客户机和服务器代码所需的工作量和对数据完整性、一致性的需求之间做出权衡。就是说,现在需要考虑到实用性。要实现朝向可靠事务策略(比如本文描述的 API 层事务策略)的渐进式推进 ,可以临时向客户机代码添加事务逻辑,从而在同一个事务工作单元中保持两个 API 层调用互相协调(确保 API 层仍然具有 REQUIRED 属性设置)。然而,您应当理解执行以下操作的含义:
- 您需要在客户机方法中使用编程式的事务(参见 “事务策略:模型和策略概述 ”)。
- 当 API 层方法被标记为回滚事务时,需要将事务回滚封装到
try/catch块中。 - 不能够对异常采取纠正操作。
- 客户机和 API 层使用的通信协议受到了限制(例如,没有 HTTP、没有 JMS 等等)。
注意,通过渐进式地实现这个事务策略,您将不会得到一个可靠和健壮的事务策略,除非您完成了重构工作。
事务策略实现
API Layer 事务策略的实现相当简单。因为包含事务逻辑的惟一的一个层是 API 层,我将只展示该层的域模型类中的事务逻辑。
回忆一下 策略设置和特征 小节,对于写操作(更新、插入和删除),公共 API 层方法应当有一个事务属性 REQUIRED 并包含事务回滚逻辑。任何公共读方法在默认情况下都应该有一个事务属性 SUPPORTS ,其中不包含回滚逻辑。下面的清单 5 解释了这一事务策略实现:
清单 5. 实现 API Layer 策略
|
实现这一策略的一种更优化的方法是利用 EJB 3.0 中的 @TransactionAttribute 注释的 TYPE 作用域,并且在默认情况下将整个类中的所有方法设为 REQUIRED ,同时只将读操作覆盖为 SUPPORTS 。清单 6 展示了这一技巧:
清单 6. 优化 API Layer 策略的实现
|
我建议使用这种方法,而不是将所有内容默认设置为 SUPPORTS ,因为如果您忘记编写 @TransactionAttribute 注释的话,那么拥有一个事务总比什么都没有强。
结束语
API Layer 事务策略将良好地应用于大多数业务应用程序。它很直观、简单、易于实现,并且很健壮。您可能需要进行一些应用程序重构来实现这一策略,但从长远来看,付出这些努力来获得高度的数据一致性和完整性是非常值得的。记住,本文所描述的是一种事务策略 。它所涉及的不仅仅是一个简单的实现任务。团队中的每位开发人员都应当知道并理解所使用的事务策略,能够描述它,并且最重要的是能够执行它。
尽管 API Layer 事务策略是最常见的一种策略,但它也许正是您的应用程序所需要的策略。例如,有些时候,单个 LUW 中的单一 API 调用和多个 API 调用之间的分割百分比是颠倒的(假设,20% 的单一 API 层调用,80% 的多 API 层调用)。对于这类情况,可能不希望进行重大的重构。这时应当使用 Client Orchestration 事务策略,这是我将在本系列下一篇文章中介绍的内容。否则,在 API Layer 事务策略中实现事务的时间会变得很长,从而导致数据库并发性问题,降低了吞吐量,需要连接等待,甚至出现数据库死锁。这些症状经常出现在高并发性环境中, 在这种环境中,应用程序必须处理庞大的用户量或负载。遇到这种情况,需要使用 High Concurrency 事务策略 — 本系列第 5 篇文章的主题。最后一种情况,您发现自己面对的是专门针对高速需求的标准应用程序架构,每一毫秒的处理时间都非常重要。对于这些情况,您将需要使用 High Speed 事务策略,我将在本系列的第 6 篇文章中进行讨论。