strom中worker、task、spout/bolt、executor、component的关系
整理一下网上有关worker、task、spout/bolt、executor、component之间的关系。
Storm在集群上运行一个Topology时,主要通过以下3个实体来完成Topology的执行工作:
1. Worker(进程)
2. Executor(线程)
3. Task
下图简要描述了这3者之间的关系:
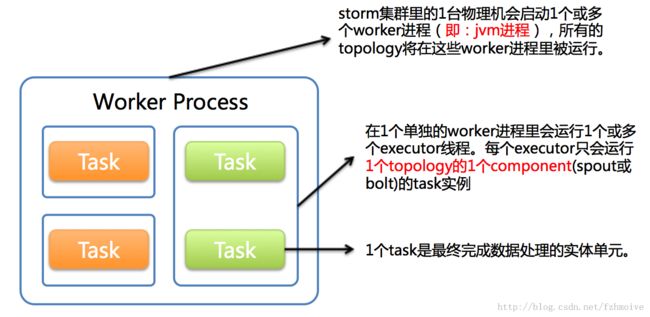
1个worker进程执行的是1个topology的子集(注:不会出现1个worker为多个topology服务)。1个worker进程会启动1个或多个executor线程来执行1个topology的component(spout或bolt)。因此,1个运行中的topology就是由集群中多台物理机上的多个worker进程组成的。
executor是1个被worker进程启动的单独线程。每个executor只会运行1个topology的1个component(spout或bolt)的task(注:task可以是1个或多个,storm默认是1个component只生成1个task,executor线程里会在每次循环里顺序调用所有task实例)。
task是最终运行spout或bolt中代码的单元(注:1个task即为spout或bolt的1个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)。topology启动后,1个component(spout或bolt)的task数目是固定不变的,但该component使用的executor线程数可以动态调整(例如:1个executor线程可以执行该component的1个或多个task实例,当执行多个task实例时executor的数量就减少了)。这意味着,对于1个component存在这样的条件:#threads<=#tasks(即:线程数小于等于task数目)。默认情况下task的数目等于executor线程数目,即1个executor线程只运行1个task。
如果一个topology里面一共有一个spout, 一个bolt。 其中spout的parallelism是2, bolt的parallelism是4, 那么我们可以把这个topology的总工作量(即task的数量)看成是6, 那么一共有6个task,那么/tasks/{topology-id}下面一共会有6个以task-id命名的文件,其中两个文件的内容是spout的id, 其它四个文件的内容是bolt的id。
topology里面的组件(spout/bolt)都根据parallelism被分成多个task, 而这些task被分配给supervisor的多个worker来执行。
task都会跟一个componment-id关联, componment是spout和bolt的一个统称。
对于每一个component在部署的时候都会指定使用的数量,通过设置parallelism来指定执行spout/bolt的线程数量. 而在配置中还有另外一个地方(backtype.storm.Config.setNumWorkers(int))来指定一个storm集群中执行topolgy的进程数量, 所有的线程将在这些指定的worker进程中运行. 比如说一个topology中要启动300个线程来运行spout/bolt, 而指定的worker进程数量是60个, 那么storm将会给每个worker分配5个线程来跑spout/bolt, 如果要对一个topology进行调优, 可以调整worker数量和spout/bolt的parallelism数量(调整参数之后要记得重新部署topology. 后续会为该操作提供一个swapping的功能来减小重新部署的时间).
/**************************************************示例***************************************************************/
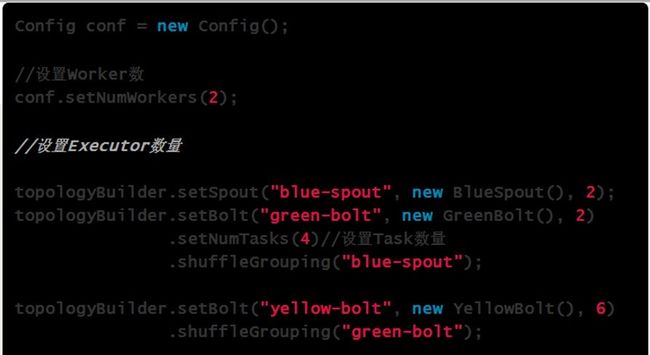
图形理解:
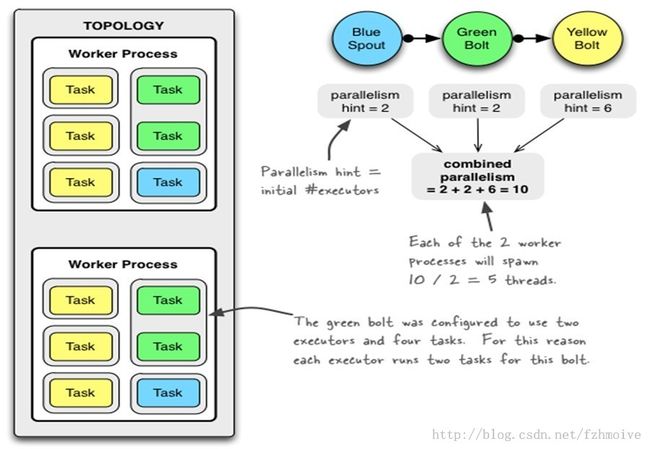
Spout或者Bolt的Task个数一旦指定之后就不能改变了,而Executor的数量可以根据情况来进行动态的调整。默认情况下# executor = #tasks即一个Executor中运行着一个Task。
动态调整:

总结:一个topology可以通过setNumWorkers来设置worker的数量,通过设置parallelism来规定executor的数量(一个component(spout/bolt)可以由多个executor来执行),通过setNumTasks来设置每个executor跑多少个task(默认为一对一)。
task是spout和bolt执行的最小单元。