linux-基本命令2
3 文件与目录管理
3.1 命令ls:列出文件
ls=Listing Files/SubFolders:列出文件/子目录
ls
ls -al
ls -alh
参数 :
-a显示全部文件(包括.开头的隐藏文件)
-l比较详细的列表-h人类能看懂的比如把1024显示为1K
ls b*
列出以b开头的所有文件或文件夹(及其下的所有文件)
举例:
gexing111@gexing111-Lenovo-IdeaPad-Y470 ~ $ ls
Desktop latest.zip nox-dependencies.deb.1 Templates workspace
Documents Music Pictures test
Downloads newtxt Public Videos
eclipse nox-dependencies.deb swig-1.3.40 wordpress
其中有文件 latest.zip
则 :
gexing111@gexing111-Lenovo-IdeaPad-Y470 ~ $ ll l*
-rw-rw-r-- 1 gexing111 gexing111 4247824 2012-03-05 12:48 latest.zip
其中有文件夹Music
gexing111@gexing111-Lenovo-IdeaPad-Y470 ~ $ ll M*
total 0
-rw-rw-r-- 1 gexing111 gexing111 0 2012-03-09 14:31 1.txt
因为M开头的没有该文件,只有一个Music文件夹,这是唯一的,其实这时(M*)按Tab键就可以直接补全了,所以就不会显示文件夹名字。
其中的文件夹Pictures和Public都以P开头:
gexing111@gexing111-Lenovo-IdeaPad-Y470 ~ $ ll P*
Pictures:
total 456
-rw-rw-r-- 1 gexing111 gexing111 349353 2012-03-06 20:26 Screenshot at 2012-03-06 20:26:29.png
-rw-rw-r-- 1 gexing111 gexing111 105610 2012-03-08 23:12 Screenshot at 2012-03-08 23:12:19.png
Public:
total 0
注意 total是文件总大小。
有时ll是 ls -al的简写
ls -Sl :按照文件大小大到小排序是 ls -Slr :按照文件大小从小到大排就加个-r
所有参数 :
-a :全部的文件,连同隐藏文件( 开头为 . 的文件) 一起列出来
-A :全部的文件,连同隐藏文件,但不包括 . 与 .. 这两个目录,一起列出来
-l :除文件名称外,亦将文件类型、权限、拥有者、文件大小等信息详细列出
-h :将文件大小以人类较易读的方式(例如 GB, KB 等等)列出来;
-r :将排序结果反向输出,例如:原本文件按英文字母顺序由小到大,反向则为由大到小;
-R :递归连同子目录内容一起列出来;
-t :依时间排序
列出inode号:
ls -i filename
3.2 命令cd:更改目录
.. 代表上一层目录
- 代表前一个工作目录
~ 代表“目前用户身份”所在的主目录
~account 代表 account 这个使用者的主目录
与此相关的命令:
cd [相对路径或绝对路径] cd #表示进入家目录 cd ~ #表示进入家目录 cd - #表示进入前一个目录 cd .ssh #因为.ssh前面的点表示隐藏的文件夹 可以从 ls -al 看出来
3.3 命令dirs:切换目录
$pushd /dir2 $pushd /dir1 $pushd /dir0 $dirs /dir0 /dir1 /dir2 $pushd +2 进入栈中/dir2 $popd +2 删除栈中/dir2
3.3 命令pwd:显示当前目录
pwd [-P] pwd -P #-P表示打印真正的路径,而非链接路径。
3.4 命令mkdir:创建文件夹
mkdir [-mp] 目录名称 mkdir -p test1/test2/test3 #-p表示递归的建立目录 mkdir -m 711 test #-m表示建立目录同时设置权限
3.5 命令rmdir:删除文件夹
rmdir [-p] 目录名称 rmdir -pv test1/test2/test3 #-p表示连同上层的空目录也一起删除; -v表示显示过程
3.6 命令rm:删除文件
强制删除backup.zip这个文件并不需确认,列出删除文件列表,一般还是别强制删除,除非你知道你在干嘛…
-v一般v参数都是显示过程的意思
-f 一般force的意思,即强制删除
rm -rf backup
删除backup这个文件夹,包含它的子文件和子文件夹
删除文件用上面的命令,但删除文件夹的时候就需要跑下遍历了
-r 在所有命令里都是 recursive 的意思,有些命令是大写的 R 需要注意
3.7 命令mv:移动文件
重命名backup.zip为sayhosts.com
如果加路径,就是移动到某个路径并重命名为sayhosts.com
3.8 命令cp:拷贝文件
复制backup.zip这个文件并重命名为sayhosts.com
cp -r test test2
递归将文件夹test拷贝到test2
cp -a test test2
参数-a :相当于 -pdr 的意思,即递归将所有文件包括时间等属性都复制过来。
3.9 命令chmod:更改文件权限
chmod 777 backup.zip默认文件为644,文件夹为755,用这个命令就可以改成我们常用的777权限了
3.10 命令chown:更改属主
3.11 命令df:显示磁盘使用率
df -h显示整个主机的总容量以及比率
3.12 命令du:查看文件夹总容量
du -sh dir-s就是summary,只输出当前文件夹总容量
-h一般在linux就是human给人看的意思,会把1048580b转换为1mb显示
du -h --max-depth=1
只列出当前文件夹和第一级子目录占用大小
而用ls dir的话只是列出其目录(而非其下所有文件)的大小,一般一个目录大小<=4K都记为4K。
3.13 命令ln:硬链接软链接
Linux链接分两种,一种被称为硬链接(Hard Link),另一种被称为符号链接(Symbolic Link)。默认情况下,ln命令产生硬链接。

前提必须清楚一点,当指向数据的文件个数为0 时,数据块就会被释放掉,硬链接相当于硬盘上一块数据的多个指针,而软链接相当于指向数据指针的指针。
【硬连接】
硬连接指通过索引节点来进行连接。在Linux的文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号(Inode Index)。在Linux中,多个文件名指向同一索引节点是存在的。一般这种连接就是硬连接。硬连接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止“误删”的功能。其原因如上所述,因为对应该目录的索引节点有一个以上的连接。只删除一个连接并不影响索引节点本身和其它的连接,只有当最后一个连接被删除后,文件的数据块及目录的连接才会被释放。也就是说,文件真正删除的条件是与之相关的所有硬连接文件均被删除。
【软连接】
另外一种连接称之为符号连接(Symbolic Link),也叫软连接。软链接文件有类似于Windows的快捷方式。它实际上是一个特殊的文件。在符号连接中,文件实际上是一个文本文件,其中包含的有另一文件的位置信息。
实验
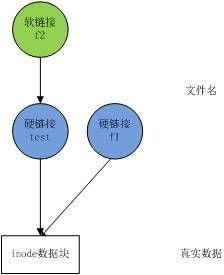
[oracle@Linux]$ touch test #创建一个测试文件test [oracle@Linux]$ ln test f1 #创建test的一个硬连接文件f1 [oracle@Linux]$ ln -s test f2 #创建test的一个软连接文件f2(符号链接) [oracle@Linux]$ ls -li # -i参数显示文件的inode节点信息 total 0 9797648 -rw-r--r-- 2 oracle oinstall 0 Apr 21 08:11 test 9797648 -rw-r--r-- 2 oracle oinstall 0 Apr 21 08:11 f1 9797649 lrwxrwxrwx 1 oracle oinstall 2 Apr 21 08:11 f2 -> test
从上面的结果中可以看出,硬连接文件f1与原文件test的inode节点相同,均为9797648,然而符号连接文件的inode节点不同。
[oracle@Linux]$ echo "I am test file" >>test [oracle@Linux]$ cat test I am test file [oracle@Linux]$ cat f1 I am test file [oracle@Linux]$ cat f2 I am test file [oracle@Linux]$ rm -f test [oracle@Linux]$ cat f1 I am test file [oracle@Linux]$ cat f2 cat: f2: No such file or directory通过上面的测试可以看出:当删除原始文件test后,硬连接f1不受影响,但是符号连接f2文件无效
总结
依此您可以做一些相关的测试,可以得到以下全部结论:
1).删除符号连接f2,对test,f1无影响;
2).删除硬连接f1, 对test,f2也无影响;
3).删除原文件test,对硬连接f1没有影响,导致符号连接f2失效;
4).同时删除原文件test,硬连接f1,整个文件会真正的被删除。
使用
比如我要建立一个目录 xiaobao->/asp/disk8/xiaobao
[[email protected]]$df -h Filesystem Size Used Avail Use% Mounted on /dev/sdb1 1.8T 13G 1.8T 1% /aps/disk1 /dev/sdc1 1.8T 13G 1.8T 1% /aps/disk2 /dev/sdd1 1.8T 13G 1.8T 1% /aps/disk3 [[email protected]]$cd /aps/disk3 [[email protected]]$mkdir xiaobao [[email protected]]$cd - [[email protected]]$ln -s /aps/disk3/xiaobao xiaobao [[email protected]]$ll lrwxrwxrwx 1 admin admin 30 Nov 20 11:31 xiaobao -> /apsarapangu/disk3/xiaobao
3.14 命令dd:指定块拷贝
dd 是 Linux/UNIX 下的一个非常有用的命令,作用是用指定大小的块拷贝一个文件,并在拷贝的同时进行指定的转换。
#创建一个100M的空文件 dd if=/dev/zero of=hello.txt bs=100M count=1
3.15 命令mount:挂载设备
以Linux挂载U盘为例(默认设备最开始在/dev/下,需要挂载到/mnt/usb下):
1、插入u盘到计算机,如果目前只插入了一个u盘而且你的硬盘不是scsi的硬盘接口的话,那它的硬件名称为:sda1。
2、在mnt目录下先建立一个usb的目录 mkdir /mnt/usb
3、挂载U盘:mount -t vfat /dev/sda1 /mnt/usb
4、卸载U盘:umount /mnt/usb
5、删除usb目录:rm -rf /mnt/usb
3.16 命令lsof:列出被打开文件
lsof(list open files)是一个列出当前系统打开文件的工具。
lsof abc.txt 显示开启文件abc.txt的进程 lsof -p 1234 列出进程号为1234的进程所打开的文件恢复删除的文件:
当Linux计算机受到入侵时,常见的情况是日志文件被删除,以掩盖攻击者的踪迹。管理错误也可能导致意外删除重要的文件,比如在清理旧日志时,意外地删除了数据库的活动事务日志。有时可以通过lsof来恢复这些文件。
当进程打开了某个文件时,只要该进程保持打开该文件,即使将其删除,它依然存在于磁盘中。这意味着,进程并不知道文件已经被删除,它仍然可以向打开该文件时提供给它的文件描述符进行读取和写入。 除了该进程之外,这个文件是不可见的,因为已经删除了其相应的目录索引节点。
在/proc 目录下,其中包含了反映内核和进程树的各种文件。/proc目录挂载的是在内存中所映射的一块区域,所以这些文件和目录并不存在于磁盘中,因此当我们对这些文件进行读取和写入时,实际上是在从内存中获取相关信息。大多数与 lsof 相关的信息都存储于以进程的 PID 命名的目录中,即 /proc/1234 中包含的是 PID 为 1234 的进程的信息。每个进程目录中存在着各种文件,它们可以使得应用程序简单地了解进程的内存空间、文件描述符列表、指向磁盘上的文件的符号链接和其他系统信息。lsof 程序使用该信息和其他关于内核内部状态的信息来产生其输出。所以lsof 可以显示进程的文件描述符和相关的文件名等信息。也就是我们通过访问进程的文件描述符可以找到该文件的相关信息。
当系统中的某个文件被意外地删除了,只要这个时候系统中还有进程正在访问该文件,那么我们就可以通过lsof从/proc目录下恢复该文件的内容。 假如由于误操作将/var/log/messages文件删除掉了,那么这时要将/var/log/messages文件恢复的方法如下:
首先使用lsof来查看当前是否有进程打开/var/logmessages文件,如下:
$lsof |grep /var/log/messages 或者用 lsof | grep deleted syslogd 1283 root 2w REG 3,3 5381017 1773647 /var/log/messages (deleted)从上面的信息可以看到 PID 1283(syslogd)打开文件的文件描述符为 2。同时还可以看到/var/log/messages已经标记被删除了。因此我们可以在 /proc/1283/fd/2 (fd下的每个以数字命名的文件表示进程对应的文件描述符)中查看相应的信息,如下:
$head -n 10 /proc/1283/fd/2 Aug 4 13:50:15 holmes86 syslogd 1.4.1: restart. Aug 4 13:50:15 holmes86 kernel: klogd 1.4.1, log source = /proc/kmsg started. Aug 4 13:50:15 holmes86 kernel: Linux version 2.6.22.1-8 ([email protected]) (gcc version 4.2.0) #1 SMP Wed Jul 18 11:18:32 EDT 2007 Aug 4 13:50:15 holmes86 kernel: BIOS-provided physical RAM map: Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 0000000000000000 - 000000000009f000 (usable) Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 000000000009f000 - 00000000000a0000 (reserved) Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 0000000000100000 - 000000001f7d3800 (usable) Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 000000001f7d3800 - 0000000020000000 (reserved) Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 00000000e0000000 - 00000000f0007000 (reserved) Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 00000000f0008000 - 00000000f000c000 (reserved)从上面的信息可以看出,查看 /proc/8663/fd/15 就可以得到所要恢复的数据。如果可以通过文件描述符查看相应的数据,那么就可以使用 I/O 重定向将其复制到文件中,如:
cat /proc/1283/fd/2 > /var/log/messages
对于许多应用程序,尤其是日志文件和数据库,这种恢复删除文件的方法非常有用。
3.17 命令stat:查看文件inode信息
xxx@xxx:~/xxx/inode> stat test File: “test” Size: 8 Blocks: 8 IO Block: 4096 一般文件 Device: 804h/2052d Inode: 89636879 Links: 2 Access: (0644/-rw-r--r--) Uid: (30026/ xxx) Gid: ( 100/ users) Access: 2014-08-07 14:21:49.000000000 +0800 Modify: 2014-08-07 14:26:48.000000000 +0800 Change: 2014-08-07 14:27:51.000000000 +0800
3.18 命令addr2line:查看内存地址表示的core行位置
addr2line –e scened 0x916d65
4 基本命令
4.1 shell脚本:在一堆JAR包中找CLASS
for f in `find *.jar`; do jar tvf $f |grep -i GrammarSanity.class ; echo $f; done

find ./lib/*
4.2 命令wget :获取远程文件
wget http://wordpress.org/latest.zip
这样便可以非常方便的将wordpress最新版下载到服务器上当前目录,免去了下载、上传的麻烦。而且通过服务器去另外的服务器下载东东.4.3 命令tar:压缩/解压缩
• *.Z compress 程序压缩的文件;
• *.bz2 bzip2 程序压缩的文件;
• *.gz gzip 程序压缩的文件;
• *.tar tar 程序打包的文件,并没有压缩过;
• *.tar.gz tar 程序打包的文件,并且经过 gzip 的压缩
unzip latest.zip
如果压缩文档是zip格式的,那么就可以用unzip这个命令来解压。
tar -czvf backup.tar.gz *该命令就是将当前目录下所有文件打包保存成backup.tar.gz压缩包
-c创建
-z用gzip压缩方式
-v显示压缩过程
-f后接文件名
tar -xzvf backup.tar.gz把刚才打包成的一坨文件解压出来放到当前目录下
-x解压缩
-z用gzip压缩方式
-v显示压缩过程
-f后接文件名
4.4 命令sort:进行文本排序
sork -nrk 1 data.txt //按第1列逆序排列其中-k 指定按哪个键进行排序,-r说明是逆序排列,-n表示按数字排序。
4.5 命令uniq:进行文本查重
文本内容:
good nice room nice nice good
进行排序,并统计单词数目:
sort 1.txt | uniq -c | sort -n -r | tee 2.txt其中第一步sort 1.txt,先进行字母排序:
good good nice nice nice room
然后进行uniq -c 统计:
2 good
3 nice
1 room
然后再进行按数字大小由大到小排序sort的-n表示按数值比较,-r表示反序:
3 nice
2 good
1 room最后tee保存到文件同时输出。
4.6 命令tail:即时显示文件内容
tail -f tester.log
可以监控多个
tail -f lua.*
4.7 命令reset:重置屏幕字符
reset可能是屏幕的缓冲区满了,原因未细究。
4.8 命令xargs:过滤器
xargs是给命令传递参数的一个过滤器,也是组合多个命令的一个工具。它把一个数据流分割为一些足够小的块,以方便过滤器和命令进行处理。通常情况下,xargs从管道或者stdin中读取数据,但是它也能够从文件的输出中读取数据。xargs的默认命令是echo,这意味着通过管道传递给xargs的输入将会包含换行和空白,不过通过xargs的处理,换行和空白将被空格取代。
find . -name "*.py" | xargs ls –l
如果“find . -name "*.py"”有两个结果a.py和b.py。那么这里xargs的作用就是将这两个结果分割并传递给ls -l。【结果默认都在结尾!】所以这里相当于:
ls -l a.py ls -l b.py
xargs特别适合与find一起使用:
不过有中错误的组合方式。例如:
错误:find . -type f -name "*.txt" -print |xargs rm -f这样做很危险。有是可能会删除不必要删除的文件。 很多文件名中都可能会包含空格符,xargs很可能会误认为他们是 定界符(例如,hell text.txt 会被xargs误认为hell和text.txt)
find的-print0表示以字符null来分隔输出。xargs的-0表示将\0作为输入定界符。
用find匹配并列出所有的.txt文件,然后用xargs将这些文件删除:
正确:find . -type f -name "*.txt" -print0 | xargs -0 rm -f
xargs+cp/mv
因为这种的结果都不是在末尾处,而是在cp/mv命令的中间。-exec之后可以接任何命令。{}表示一个匹配。对于任何一个匹配的文件名,{}会被该文件名所替换。
find . -type f -newer meta.h -print0| xargs -0 -i{} cp {} ../testMYSQL/
find . -newer meta.h | while read line; do mv $line ../testMYSQL/ ; done
find . -name "actor_xh*" | while read line ; do cat $line ; done > result.txt
xargs+tar
ls -ltr //按时间增长顺序查看文件信息
find . -type f -newer a.txt | xargs tar czvf ./cmt_pkg_`date +%Y%m%d_%H%M%S`.tar.gz //将比某文件新的进行打包
ls -ltr | grep '11:18' | awk '{print $8}' | grep -v '1.txt' | xargs tar czvf res.tar.gz注意其中的-type f 是为了去掉.文件,注意如果alias ls='ls --corlor',这里的xargs tar会出现错误。因为--color会带有格式字符。
4.9 命令md5sum:检验两个文件是否相同
如检验Jar包是否更新过代码
[[email protected]]$md5sum myJar.jar 061ea1d09a2e52036359a008e27efefe myJar.jar
也可以把多个文件的报文摘要输出到一个md5文件中,这要使用通配符*,比如某目录下有几个sh文件,要把这几个sh文件的摘要输出到sh.md5文件中,命令如下:
[[email protected]]$md5sum *.sh > sh.md5 c79f5d1a2625475790ac374b6a92cded oneKey.sh 412b7b3fdfdbc9ef493e6cde3fa3254f run_mr.sh e63c74df12477857364db4c0245559da trans_file.sh
4.10 命令grep:文本字符串查找
cat file | grep -i -r '\<nice\>' -A 2 -B 1
-i选项忽略大小写,一般正则表达式用单引号‘ ’括起来,后面的‘\<word\>’是正则表达式匹配一个完成单词,前后有空格的。-A表示after2行-B表示before的1行都打印出来。
ps aux| grep -v grep | grep python
-v选项表示反选后面的单词
grep xxx * -r -n-n表示输出行号
命令格式:
[root@linux ~]# grep [-acinv] 'pattern' filename参数:
-a :将 binary 档案以 text 档案的方式搜寻数据
-c :计算找到 '搜寻字符串' 的次数
-i :忽略大小写的不同,所以大小写视为相同
-n :顺便输出行号
-v :反向选择,亦即显示出没有 '搜寻字符串' 内容的那一行!
-r: 或者-R 表示递归搜索
4.11 命令tr:集合映射
将来自stdin的输入字符从set1映射到set2,然后将输出写入stdout(标准输出)。set1和set2是字符类或字符集。
如果set1>set2,那么set2会不断重复其最后一个字符,直到长度与set1相同。如果set1<set2,那么set2中超出set1长度的那部分字符则全部被忽略。
tr [option] set1 set2例如:将输入字符由大写转换为小写
$echo "HELLO" |tr 'A-Z','a-z'删除字符集选项-d:可以通过指定需要被删除的 字符集合(而不是单词),将出现在stdin中的特定字符清除掉:
$echo “Hello 123 world 345″ | tr -d ’0-9′ Hello world压缩字符集选项-s:压缩输入中连续重复的字符为1个。
$cat a.txt | tr -s '\n' 删除多余的换行符
4.12 命令cut:文本行处理
[root@linux ~]# cut -d '分隔字符' -f fields [root@linux ~]# cut -c 字符区间参数:
-d :后面接分隔字符。与 -f 一起使用;
-f :依据 -d 的分隔字符将一段信息分割成为数段,用 -f 取出第几段的意思;
-c :以字符 (characters) 的单位取出固定字符区间;
示例1:将 PATH 变量取出,我要找出第三个路径。
[root@linux ~]# echo $PATH /bin:/usr/bin:/sbin:/usr/sbin:/usr/local/bin:/usr/X11R6/bin:/usr/games: [root@linux ~]# echo $PATH | cut -d ':' -f 5 #以:作为分隔符,取第5个,输出:/usr/local/bin [root@linux ~]# echo $PATH | cut -d ':' -f 3,5 #取第3个~第5个 [root@linux ~]# export declare -x HISTSIZE="1000" ......其它省略...... [root@linux ~]# export | cut -c 12- HISTSIZE="1000" ......其它省略...... # 知道怎么回事了吧?用 -c 可以处理比较具有格式的输出数据!我们还可以指定某个范围的值,例如第 12-20 的字符,就是 cut -c 12-20 等等!
4.13 命令awk:文本行处理
awk [ -F re] [parameter...] ['prog'] [-f progfile][in_file...]
$awk -F: '$2!="x" {printf("%s no password!\n",$1)}' /etc/passwd
$awk '/sun/{print}' mydoc
其中-F 表示用什么来分割字段,'prog'= 'pattern {action}' 用来处理以什么模式来匹配,和怎么进行处理。
4.14 命令sed:文本行处理
$ sed '2d' example-----删除example文件的第二行。 $ sed '2,$d' example-----删除example文件的第二行到末尾所有行。 $ sed '$d' example-----删除example文件的最后一行。 $ sed '/test/'d example-----删除example文件所有包含test的行。
替换:s命令
$ sed 's/word1/word2/' example-----每行第一个匹配的word1被替换成word2。 $ sed 's/word1/word2/g' example-----整行范围内把word1替换为word2。 $ sed 's#word1#word2#g' example-----不论什么字符,紧跟着s命令的都被认为是新的分隔符,所以,“#”在这里是分隔符,代替了默认的“/”分隔符。
选定行的范围:逗号
$ sed -n '/test/,/check/p' example-----所有在模板test和check所确定的范围内的行都被打印。 $ sed -n '5,/^test/p' example-----打印从第五行开始到第一个包含以test开始的行之间的所有行。 $ sed -n '20,80p' home/temp.txt > 1.txt-----将文件第20行~第80行转存到1.txt sed
4.15 命令find:递归搜索文件名
find <指定目录> <指定条件> <指定动作>1,最一般
$find /tmp -name "*.sh" -ls2,忽略大小写
$find . -iname abcd
3,常用命令
find . -name '*.o' -type f -print -exec rm -rf {} \;
find . -name '*.d' -type f -print -exec rm -rf {} \;
find . -type f -size 0 -exec rm {} \;
4.16 命令tee:打印并同时输出到文件
tee 命令读取标准输入,然后将程序的输出写到标准输出,并同时将其复制到指定的一个或多个文件。
主要参数
-a 将输出添加到 File 的末尾而不是覆盖写入。
-i 忽略中断
实验
1,要同时查看和保存一个命令的输出:
lint program.c | tee program.lint它在工作站上显示命令 lint program.c 的标准输出,同时在文件 program.lint 中保存输出的一个副本。 如果program.lint 文件早已存在,它将被删除并替换。
2,要同时查看一个命令的输出并保存到一个现有文件:
lint program.c | tee -a program.lint它将在工作站上显示 lint program.c 命令的标准输出,同时在 program.lint 文件尾部添加输出的一个副本。 如果 program.lint 文件不存在,它将被创建。
3,同时拷贝三份文件
cat slayers.story |tee ss-copy1 ss-copy2 ss-copy3列出文本文件slayers.story的内容,同时复制3份副本,文件名称分别为ss-copy1、ss-copy2、ss-copy3
4.17 命令diff_patch:比较文件并打补丁
diff和patch是一对工具,在数学上来说,diff是对两个集合的差运算,patch是对两个集合的和运算。
一般A是原始文件,B是修改后的文件,C称为A的补丁文件。
#修改文件B - 原文件A = 补丁文件C diff A B >C #原文件A + 补丁文件C = 修改文件B(此时A被覆盖) patch A C #修改文件B - 补丁文件C = 原文件A(此时B被覆盖) patch -R B C
4.18 命令pstack:查看某进程下所有线程
Linux下打印出他所有线程的调用栈,从栈再配合程序代码就知道程序行为。事实上pstack雷人的是,这个程序竟然是个shell脚本,核心实现是gdb的 thread apply all bt。
查看某进程号pid下所有线程:
pstack pid
4.19 命令jar:打成jar包
JAR 文件就是 Java Archive File,顾名思意,它的应用是与 Java 息息相关的,是 Java 的一种文档格式。JAR 文件非常类似 ZIP 文件,准确的说,它就是 ZIP 文件,所以叫它文件包。JAR 文件与 ZIP 文件唯一的区别就是在 JAR 文件的内容中,包含了一个 META-INF/MANIFEST.MF 文件,这个文件是在生成 JAR 文件的时候自动创建的。
创建Jar包:
jar -cvfM0 test.jar ./*-c 创建jar包
-v 显示过程信息
-f 指定 JAR 文件名,通常这个参数是必须的
-M 不产生所有项的清单(MANIFEST〕文件,此参数会忽略 -m 参数
-0 数字0,表示只存储,不压缩,这样产生的 JAR 文件包会比不用该参数产生的体积大,但速度更快
解压Jar包:
jar -xvf test.jar-x 展开 JAR 文件包的指定文件或者所有文件
-v 显示过程信息
-f 指定 JAR 文件名,通常这个参数是必须的
列出目录:
jar -tf test.jar-t 列出 JAR 文件包的内容列表
-f 指定 JAR 文件名,通常这个参数是必须的
将两个Jar包合并为一个:
先将两个Jar包都解压,然后再打成一个,注意,里面的MANIFEST可以不要,即重新打包的时候不需要参数-M了。
jar -xvf gson-1.7.1.jar#得到META-INF和com rm -rf META-INF jar -xvf log4j-1.2.16.jar#得到META-INF和org rm -rf META-INF jar -cvf my.jar com org#将com和org打包成my.jar
4.20 命令java -cp:爪哇运行Jar包
java -cp .:./*:./lib/* package.app.Tool -f ./1.file用冒号分割目录,必须要加入当前目录".",-cp表示-classpath指明了class文件路径
4.21 命令scp:远程传输文件
1,从本地服务器复制到远程服务器
scp local_file remote_username@remote_ip:remote_folder
#scp /home/administrator/news.txt [email protected]:/etc/squid2,从远程服务器复制到本地服务器
scp remote_username@remote_ip:remote_folder local_file
#scp [email protected]:/usr/local/sin.sh /home/administrator
对于递归复制文件夹,则需要-r参数,注意-r参数应放置的位置是:scp -r ....
4.22 命令ssh:远程登录
命令格式 :
ssh name@remoteserver ssh remoteserver -l name说明:以上两种方式都可以远程登录到远程主机,server代表远程主机,name为登录远程主机的用户名。
2、连接到远程主机指定的端口
命令格式:
ssh name@remoteserver -p 2222 ssh remoteserver -l name -l -p 2222说明:p 参数指定端口号,通常在路由里做端口映射时,我们不会把22端口直接映射出去,而是转换成其他端口号,这时就需要使用-p端口号命令格式。
3、通过远程主机1跳到远程主机2
命令格式:
ssh -t remoteserver1 ssh remoteserver2说明:当远程主机remoteserver2无法直接到达时,可以使用-t参数,然后由remoteserver1跳转到remoteserver2。在此过程中要先输入remoteserver1的密码,然后再输入remoteserver2的密码,然后就可以操作remoteserver2了。
4、通过SSH运行远程shell命令
命令格式:
ssh name@remoteserver ‘command1;commmand2;command3’说明:连接到远程主机,并执行远程主机的command命令。例如:查看远程主机的内存使用情况。
$ ssh -l root 192.168.1.100 svmon -G
A机器ssh免密码登陆B机器




ssh-keygen -t dsa
ssh-keygen -t rsa
ssh-keygen -t rsa1
| A机器 | B机器 |
| 公钥id_rsa.pub | |
| 私钥id_rsa |
3,将公钥从A机器拷贝到B机器
把公钥传到远端主机B的.ssh文件夹下,这时当然还是需要密码的。
scp [email protected]:/root/.ssh/id_rsa.pub /root/.ssh/

| A机器 | B机器 |
| 私钥id_rsa | 公钥id_rsa.pub |
并将公钥写入到B机器上的authorized_keys中:
mv id_rsa.pub ~/.ssh/authorized_keys 或者: cat id_dsa.pub >> ~/.ssh/authorized_keys
chmod 600 .ssh/authorized_keys #authorized_keys的权限要是600。
| A机器 | B机器 |
| 私钥id_rsa | 公钥authorized_keys(id_rsa.pub) |
4,操作完毕,登陆检查
到客户机A执行ssh 192.168.1.254
 ‘
‘
可以看到登录成功!
4.23 命令watch:让静态命令动态输出
watch -n1 'netstat -s'
4.24 命令tcpdump:网络抓包
tcpdump -i eth0 -c 100 -w 1.log strings 1.log > 2.log其中-c表示抓100个包,-w表示保存到某文件,strings表示处理查看该文件。