目标跟踪学习系列三:A robust boosting tracker with minimum error bound in a Co-training framework
文章:A robust boosting tracker with minimum error bound in a Co-training framework
Rong Liu ; Nat. Lab. of Pattern Recognition, Chinese Acad. of Sci., Beijing, China ; Jian Cheng ; Hanqing Lu: ICCV,2009
这篇文章是中科院自动化所2009年发在ICCV上面的文章。用一句话来总结这篇文章是:The most important contribution is that we find a boostingerror upper bound in a co-training framework to guide the novel tracker construction。这篇文章正是发现一般的boosting和co-training的方法,他们的得到的结果的错误率有一个上界。于是找到这个错误率,并通过对它的最小化来引导tracker的生成。由此便得到了一个准确率很好的tracker。作者同时还对这个上界进行了证明。这就是这篇文章主要做的工作。(足见作者的数学功底)
看完了论文的introduction后知道09年前的主要的tracking的算法和他们的特点:1、LDA 简单但是tracker效果不能很好的提高;2、基于SVM的support vector tracker效果好,但是降低了对于复杂背景的适应能力;3、使用多特征的Ensemble tracker 有明显的优势,但是他是对pixel操作的,丢失了很多的结构信息;4、on-line boosting有很好的适应能力,但是会漂移(用文章的原话说是:self-training process which use the classification results toupdate the classifier itself)。很明显作者也关注到06年的这篇on-line boosting的文章中存在的问题:拿检测到的结果来更新分类器。于是他也想到了半监督的方法(这篇论文的作者08年的另一篇论文就是通过semi-supervised方法改进了这篇论文)。不同的是他通过co-training和boosting的方法。
如他的文章所说,他不是简单的将boosting和co-training合起来,而是导出boosting error的上界,并由此构造分类器。如下面的Eq(1)所示,是一个有adaboost构造的强分类器。

而这个强分类器的错误如Eq(2)所示,其中的Zt如Eq(3)所示。而Eq(3)中的Dt(i)表示第i个sample第t次训练时的归一化权重。结合Eq(1)就可以推导出Eq(2)。比较好理解。
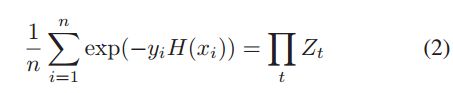
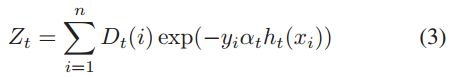
而下面的这个式子是在2007年的一篇叫做:Bayesian co-training的文章中推导出来的。其中的j是Multi-view algorithm(多视角算法)中的系数,代表视角的个数。 本文中的view有两个,即:j=2 。可见,若是使用贝叶斯决策构造分类器就满足该式子。我们也由此知道这类错误有一个上界如Eq(4)所示。Eq(5)则是通过co-training构造的最终的强分类器。


接下来,作者花了大量的章节来证明这个错误函数是有上界的。
首先,证明了下面的这个式子。证明的过程大概是这样的:在不失一般性的情况下,做三个假设:1、training sample 量很大;2、在不同视角(view)中的特征所给的标签条件独立;3、依照不同的视角的决策大体是一致的。然后,根据前面的Eq(2)(5),最重要的是在做Eq(1)的转化便可以证明出来。
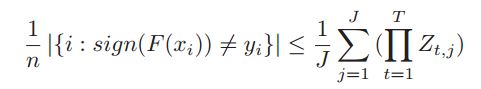
但是这里有个问题,上面的证明是认为所有的样本都是有标签的,于是推导到半监督的学习当中。将所有的样本分为两部分来求解,有标签的和上面一样;没标签的通过错误率来推导,关键步骤用到了Eq(4)。具体的证明还是要认认真真的看论文原文。
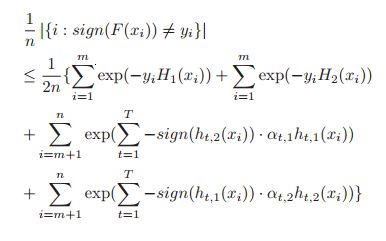
证明了上面的结论后,就可以使用它来构造分类器了。下面具体列出本文使用的特征和方法。
本文对100帧图像进行跟踪,对比其他算法。将其中的前十帧作为是有标签的,用来训练。后面的90帧样本作为无标签的,用来测试。对前十个样本,建立两种特征池,一种是颜色特征(49种组合的color feature),另一种是LBP特征(25种)。通过这两种特征构造直方图,分别用来训练分类器(也就是说,这里采用的muti-view算法中的视角数是2,即j=2)。这里的弱分类器是通过bayesian decision criterion 构造的(也就说他的错误的大小存在一个上界,如Eq(4))。
到此刻,前期的准备工作都已经完成。接下来的重点就是如何来更新分类器的问题了。作者的基本思路还是使用boosting方法:分别更新两个视角中每个弱分类器以及它们的权重。然后综合两个视角的结果(co-training)构造强的分类器。关键的不同时更新规则的不同。首先找到这种分类器的错误的表达式;然后,得到它的上界;最后,将这个上界最小化,于是相应的选出错误最小的那个弱分类器以及得到它的权重,组合构造出强分类器。算法的伪代码如下:

文章的优点:使用co-training半监督的方法,很好的结合了labeled和unlabeled样本,克服了on-line算法的漂移的问题。
缺点:推导较为复杂不易传播推广;以前十帧作为训练样本,不知道这是不是他的算法比别人的好的原因。