Hadoop之HDFS子框架
体系结构
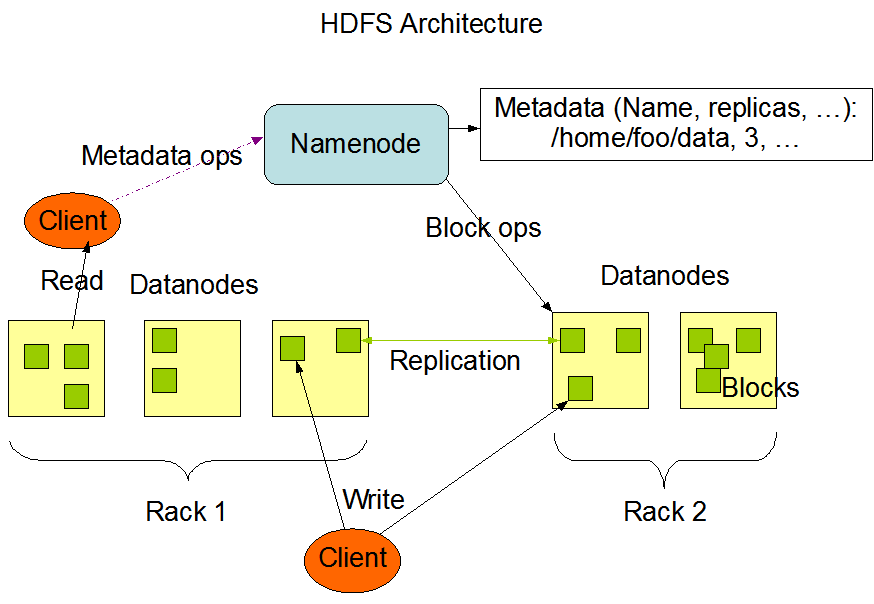
由图片可以看到HDFS主要包含这样几个功能组件
Namenode:存储文档的元数据信息,还有整个文件系统的目录结构
DataNode:存储文档块信息,并且文档块之间是有冗余备份的
这里面提到了文档块的概念,同本地文件系统一样,HDFS也是按块存储的,只不过块的大小设置的相对大一些,默认为64M。如果一个文件不足64M,那么它只存储在一个块中,而且并不会占用64M的磁盘空间,
这一点需要注意,HDFS不适用于小文件存储的原因并不是因为小文件消耗磁盘空间,而是因为小文件占用了太多的块信息,每个文档块的元数据是会存储在namenode的内存里的,因此当文档块较多的时候会十分消耗namenode的内存
从功能结构来看,namenode提供了数据定位的功能,datanode提供数据传输,也就是客户端在访问文件系统的时候是直接从datanode里面读取数据的,而不是namenode
从部署结构来看,namenode作为系统的唯一单点,如果一旦出现问题那么后果是十分危险的,整个文档系统将面临瘫痪,HDFS针对此设计了secondNameNode,用来备份namenode的数据
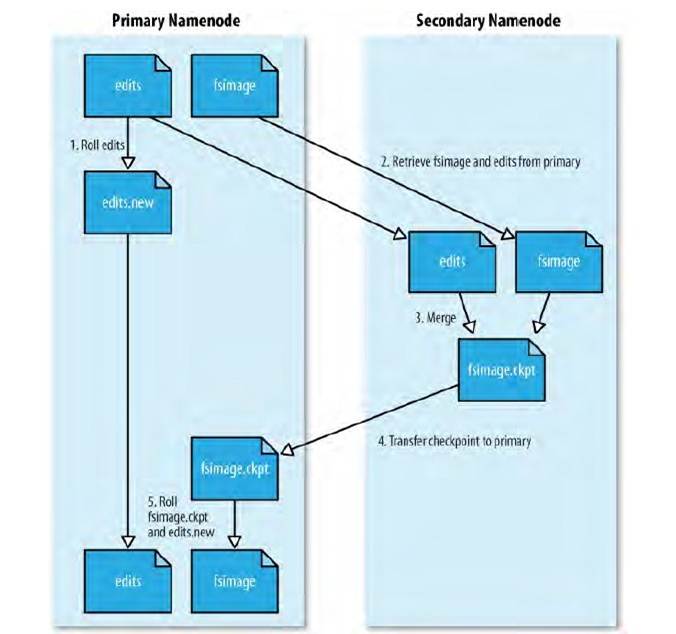
从目录结构来看,namenode由两部分信息组成
fsimage用来封装文件系统的元数据信息(包括文档的访问时间、访问权限,所包含的数据块等)
edits用来记录文档系统的操作日志
当namenode启动的时候,fsimage会被加载到内存,然后对内存里的数据执行edits所记录的操作,以确保内存所保留的数据处于最新的状态。
当namenode启动后,所有对文件系统元数据的访问都是从内存中获取的,而不是fsimage。fsimage和edits只是实现了元数据的持久存储功能,事实上所有基于内存的存储系统大概都是采用这种方式
这样做的好处是加快了元数据的读取和更新操作(直接在内存中进行),但是也带来了负面的影响,当edits内容较大时,namenode的启动会变得非常缓慢
对此,secondNamenode提供了将fsimage和edits聚合的功能,首先将namenode里的数据拷贝过来,然后执行merge聚合操作,在将聚合后的结果返回给namenode,并且在本地保留备份,这样不但加快了namenode的启动速度,也对namenode的数据增加了冗余。
IO操作
hdfs读取文件流程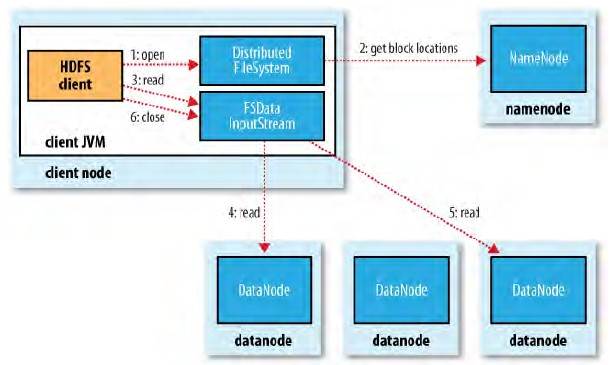
首先,连接到分布式文件系统,从namenode里获取要访问的文件由哪些块组成,每一个块的存储地址是多少
然后,定位到指定的datanode去读取文件
注意:每个块的存储地址是在hadoop启动之后才加载到namenode的内存里的,而不是持久化存储到namenode本地
namenode和datanode具备心跳通信的功能,它会定时从datanode那里收到一些反馈,包括block的存储地址信息等等
hdfs写文件流程
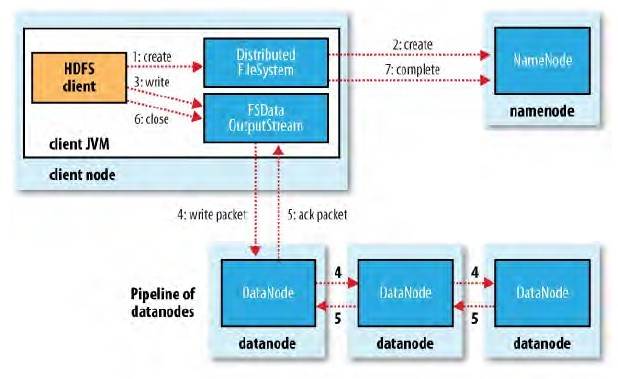
首先同样是连接到分布式文件系统,向namenode发送创建文件的命令
namenode保存文档的元数据信息之后会调度具体的datanode来执行数据流的写入操作,写入成功后,需要执行冗余备份,将Block复制多份,每一分存储到不同的机器节点中,防止单点故障的出现
使用HDFS来存储数据,每个block至少要备份一份,默认是3份,如果没有指定备份,或者备份的过程中出现了异常,则文件的写入操作不会成功
hdfs不适用的场景
1.低延迟的数据访问HDFS主要针对大文件来设计的,多用于线下的数据分析,对于线上应用并且及时性要求较高的系统,可尝试使用Hbase
2.大量小文件
消耗namenode内存,可以使用SequenceFile或MapFile来作为小文件的容器
3.多线程写入,随机写入
HDFS系统中,每个文件只能并发开启一个Writer,并且写入操作只能在文件的末尾进行