多线程渲染(Multithreaded- rendering)3D引擎实例分析 : FlagshipEngine
1. 开篇:关于FlagshipEngine
首先要感谢旗舰工作室的倒掉,让我可以名正言顺的使用FlagshipEngine这个 名字,话说这个实验引擎,当初只是我的大学毕业设计,工作之后实在太忙,写写停停,进度缓慢,到今天也只能算V0.001,其特性主要有以下三点:
一、多线程
多核CPU 早已普及,但3D引擎却迟迟不能享受到其好处,还 仅仅停留在资源异步加载,音频独立线程等不疼不痒的应用,就在一年前吧,公司的牛人们为了优化骨骼动画和粒子计算煞费苦心,这两样计算,特别是在无法控制 同屏资源的网络游戏中,对CPU资源的占用非常可观,自然也拖累了游戏帧数,于是我便有了将逻辑计算与渲染分离的想法。
FlagshipEngine实现了一套没有线程同步的双线程结构,可以做到骨骼动画、 粒子计算、光源移动 等逻辑计算分离到一个单独的线程运行,完全不影响渲 染帧数。
二、shader渲染器
DX10已经放弃了固定管线,那么我们也没理由再留恋 它,完全基于shader的渲染器实现起来更加清晰简洁,并且易于扩展,目前FlagshipEngine已经实现了DX9和DX10两个渲染器,可以方 便的添加特效。
三、统一剪裁
场景组织和剪裁永远是3D引擎 的核心功能,视锥、四叉树、BSP 、Portal如何选择,如何统一是个难题,我的 做法是将所有的剪裁都抽象成剪裁面,并用压栈和出栈的方式,递归的对场景进行剪裁,另外我们还可以对大块实体绑定简单模型的遮挡体,使用边缘检测算法生成 遮挡剪裁面,实现遮挡剪裁。
这套机制还没有经过严格的测试,有待进一步的验证。
2. 3D引擎多线程:资源异步加载
资源异步加载恐怕是3D引擎中应用最为广泛的多线程技术了,特别是在无缝地图的网络游戏中,尤为重要,公司3D引擎的资源加载部分采用了硬盘->内 存->显存两级加载的模式,超时卸载也分两级,这样虽然实际效果不错,但代码非常繁琐,在FlagshipEngine中,我设法将其进行了一定程 度的简化。
首先我们需要定义一个Resource基类,它大致上是这样的:
class _DLL_Export Resource : public Base
{
public:
Resource();
virtual ~Resource();
// 是否过期
bool IsOutOfDate();
public:
// 是否就绪
virtual bool IsReady();
// 读取资源
virtual bool Load();
// 释放资源
virtual bool Release();
// 缓存资源
virtual bool Cache ();
// 释放缓存
virtual void UnCache();
protected:
// 加载标记
bool m_bLoad;
// 完成标记
bool m_bReady;
private:
};
在实际游戏中,加载资源的范围大于视野,当摄像机移动到单元格边缘(必须有一定的缓冲区),就应将新的单元格中的对象加入到资源加载队列中,唤醒资源加载 线程调用Load接口进行加载,完成后将该资源的加载标记设为true。而通过可视剪裁所得到的最终可视实体,则需要调用Cache接口构建图像API所 需对象,当Load和Cache都完成后IsReady才会返回true,这时该资源才能开始被渲染。
卸载方面,在加载新的单元同时,卸载身后旧的单元,对单元内所有资源调用Release,Load/Release带有引用计数,仍被引用的资源不会被卸 载。当某一资源长时间没有被看见,则超时,调用UnCache释放VertexBuffer等资源。
为了实现超时卸载功能,我们需要一个ResourceManager类,每帧检查几个已Cache的资源,看起是否超时,另外也需对已加载的资源进行分类 管理,注册其资源别名(可以为其文件名),提供查找资源的接口。
另外为了方便使用,我们需要一个模板句柄类ResHandle<T>,设置该资源的别名,其内部调用ResourceManange的查找方 法,看此资源是否已存在,如不存在则new一个新的,GetImpliment则返回该资源对象,之后可以将该资源添加到实体中,而无需关心其是否已被加 载,代码如下:
template <class T>
class _DLL_Export ResHandle
{
public:
ResHandle() { m_pResource = NULL; }
virtual ~ResHandle() {}
// 设置资源路径
void SetPath( wstring szPath )
{
Resource * pResource = ResourceManager::GetSingleton()->GetResource( Key( szPath ) );
if ( pResource != NULL )
{
m_pResource = (T *) pResource;
}
else
{
m_pResource = new T;
m_pResource->SetPath( szPath );
ResourceManager::GetSingleton()->AddResource( m_pResource );
}
}
// 模板实体类指针
T * GetImpliment() { return (T *) m_pResource; }
T * operator-> () { return (T *) m_pResource; }
protected:
// 模板实体类指针
Resource * m_pResource;
private:
};
3. 3D引擎多线程:渲染与逻辑分离
目前的3D引擎的渲染帧和逻辑帧都是在一个线程上运行的,在网络游戏中大量玩家聚集,繁重的骨骼动画计算和粒子计算极大的拖累了渲染帧数,有两种有效措 施:
1、控制同屏显示人数,但玩家体验不好
2、帧数低于某值时减少动画Tick频率,但带来的问题是动画不连贯。
如果考虑使用多线程优化,最容易想到的就是采用平行分解模式,将骨骼动画计算和粒子计算写成两个for循环,然后用OpenMP将其多线程化,但事实上这 样并不会提高多少效率,这两者计算仍然要阻滞渲染帧,线程的创建也有一定的消耗。于是我想到了一种极端的解决方案,采用任务分解模式,将渲染和逻辑完全分 离到两个线程去,互不影响,当然这样线程同步会是大问题,毕竟线程的数量和BUG的数量是成正比的。
我们首先来分析下这两个线程分别需要做什么工作,需要那些数据。渲染线程需要获取实体的位置、材质等信息,并交给GPU 渲染,逻辑线程需要更新实体的位置、材质、骨骼动 画等数据,很显然一个写入一个读取,这为我们实现一个没有线程同步的多线程3D渲染系统提供了可能。
为了让读取和写入不需要Lock,我们需要为每一份数据设计一个带有冗余缓存的结构,读取线程读取的是上次写入完成的副本,而写入线程则向新的副本写入数 据,并在完成后置上最新标记,置标记的操作为原子操作即可。以Vector为例,这个结构大致是这样的:
struct VectorData
{
Vector4f m_pVector[DATACENTER_CACHE];
int m_iIndex;
VectorData()
{
memset( m_pVector, 0, DATACENTER_CACHE * sizeof(Vector4f) );
m_iIndex = 0;
}
void Write( Vector4f& rVector )
{
int iNewIndex = m_iIndex == DATACENTER_CACHE - 1 ? 0 : m_iIndex + 1;
m_pVector[iNewIndex] = rVector;
m_iIndex = iNewIndex;
}
Vector4f& Read()
{
return m_pVector[m_iIndex];
}
};
当然我们可以用模板来写这个结构,让其适用于int,float,matrix等多种数据类型,余下的工作就简单了,将所有有共享数据的类的成员变量都定 义为以上这种数据类型,例如我们可以定义:
SharedData<Matrix4f> m_matWorld;
在渲染线程中调用pDevice->SetWorldMatrix( m_matWorld.Read() );
在逻辑线程中调用m_matWorld.Write( matNewWorld );
需要注意的是,这种方案并非绝对健壮,当渲染线程极慢且逻辑线程极快的情况下,有可能写入了超过了DATACENTER_CACHE次,而读取却尚未完 成,那么数据就乱套了,当然真要出现了这种情况,游戏早已经是没法玩了,我测试的结果是渲染帧小于1帧,逻辑帧大于10000帧,尚未出现问题。
FlagshipEngine采用了这一设想,实际Demo测试结果是,计算25个角色的骨骼动画,从静止到开始奔跑,单线程的情况下,帧数下降了 20%~30%,而使用多线程的情况下,帧数完全没有变化!
4. 3D引擎多线程:框架
现在我们已经有了三个可独立工作的线程:资源加载线程、逻辑线程、渲染线程,下一步我们需要决定它们如何在实际的项目中相互配合,也就是所谓的应用程序框 架了,该框架需要解决以下两个问题
首先,资源读取线程可以简单设计为一个循环等待的线程结构,每隔一段时间检查加载队列中是否有内容,如果有则进行加载工作,如果没有则继续等待一段时间。 这种方式虽然简单清晰,但却存在问题,如果等待时间设得过长,则加载会产生延迟,如果设得过短,则该线程被唤醒的次数过于频繁,会耗费很多不必要的CPU 时间。
然后,主线程是逻辑线程还是渲染线程?因为逻辑线程需要处理键盘鼠标等输入设备的消息,所以我起初将逻辑线程设为主线程,而渲染线程另外创建,但实际发 现,帧数很不正常,估计与WM_PAINT消息有关,有待进一步验证。于是掉转过来,帧数正常了,但带来了一个新的问题,逻辑线程如何处理键盘鼠标消息?
对于第一个问题,有两种解决方案:
第一,我们可以创建一个Event,资源读取线程使用WaitForSingleObject等待着个Event,当渲染线程向加载队列添加新的需加载的 资源后,将这个Event设为Signal,将资源读取线程唤醒,为了安全,我们仍需要在渲染线程向加载队列添加元素,以及资源加载线程从加载队列读取元 素时对操作过程加锁。
第二,使用在渲染线程调用PostThreadMessage,将资源加载的请求以消息的形式发送到资源价值线程,并在wParam中传递该资源对象的指 针,资源加载线程调用WaitMessage进行等待,收到消息后即被唤醒,这种解决方案完全不需要加锁。
对于第二个问题,我们同样可以用PostThreadMessage来解决,在主线程的WndProc中,将逻辑线程需要处理的消息发送出去,逻辑线程收 到后进行相关处理。
需要注意的是,我们必须搞清楚线程是在何时创建消息队列的,微软如是说:
The thread to which the message is posted must have created a message queue, or else the call to PostThreadMessage fails. Use one of the following methods to handle this situation.
Call PostThreadMessage. If it fails, call the Sleep function and call PostThreadMessage again. Repeat until PostThreadMessage succeeds.
Create an event object, then create the thread. Use the WaitForSingleObject function to wait for the event to be set to the signaled state before calling PostThreadMessage. In the thread to which the message will be posted, call PeekMessage as shown here to force the system to create the message queue.
PeekMessage(&msg, NULL, WM_USER, WM_USER, PM_NOREMOVE)
Set the event, to indicate that the thread is ready to receive posted messages.
看来,我们只需要在线程初始化时调一句PeekMessage(&msg, NULL, WM_USER, WM_USER, PM_NOREMOVE)就可以了,然后在主线程中如此这般:
switch ( uMsg )
{
case WM_PAINT:
{
hdc = BeginPaint(hWnd, &ps);
EndPaint(hWnd, &ps);
}
break;
case WM_DESTROY:
{
m_pLogic->StopThread();
WaitForSingleObject( m_pLogic->GetThreadHandle(), INFINITE );
PostQuitMessage(0);
}
break;
default:
{
if ( IsLogicMsg( uMsg ) )
{
PostThreadMessage( m_pLogic->GetThreadID(), uMsg, wParam, lParam );
}
else
{
return DefWindowProc( hWnd, uMsg, wParam, lParam );
}
}
break;
}
在逻辑线程中这般如此:
MSG msg;
while ( m_bRunning )
{
if ( PeekMessage( &msg, NULL, 0, 0, PM_NOREMOVE ) )
{
if ( ! GetMessageW( &msg, NULL, 0, 0 ) )
{
return (int) msg.wParam;
}
MessageProc( msg.message, msg.wParam, msg.lParam );
}
LogicTick();
}
完成!
5. 3D引擎多线程:逻辑操作
在实际游戏中,逻辑线程需要对渲染对象做许多操作,比如添加与删除,改变渲染对象的属性等等,而由于在先前的设计中,逻辑线程与渲染线程相互独立,如果只 是改变某一共享数据,没有问题,但如果操作影响到了场景结构,例如实体的添加与删除,则必须进行线程同步,这又违背了FlagshipEngine的设计 初衷——避免繁重的逻辑计算影响渲染速度。
解决办法其实在上一篇中已经提到了,仍然是利用天然的同步机制——Windows消息,添加实体时,逻辑线程只是new了一个Entity对象,设置这个 对象的初始共享数据,比如位置信息,同时向渲染线程发送一条WM_ADDENTITY的自定义消息,将Entity指针作为wParam传递。渲染线程接 受到消息后调用Entity的UpdateScene方法,更新Entity在场景树中的位置,并加载资源。
删除也是一样,逻辑线程向渲染线程发送WM_DELETEENTITY消息,并不再使用该Entity指针,渲染对象则处理改消息,将此Entity从场 景中删除并卸载资源。
这里有一个非常危险的情况,前面一篇提到,资源加载也是通过消息传递实现的,同样是传递的资源指针,如果逻辑线程添加了一个Entity,还没加载就删掉 了它,则资源加载线程会拿到一个过期指针,一切就结束了。。。
解决这一问题,最稳妥的方法是消息的wParam并不传递指针,而是传递该Entity或资源的唯一ID,这样的话即使ID过期,也可轻松忽略掉这条消 息,坏处是每次消息处理都的从全局的map 里检查是否存在此ID对应的Entity或资源, 这可是笔不小的开销。
第二种方案,我们仍然传递指针,只是在接受到WM_DELETEENTITY消息时,检查该Entity是否已经加载完成,如果没有完成,则重新将此消息 加入消息队列,下个渲染帧再次判断。
FlagshipEngine的多线程设计大致就是如此了。
6. DX11 与多线程渲染
前几天突然想起新的DXSDK应该早出了,去微软网站一看,好么。。。2008 Dec版早出了,这次火星了,下载完后居然发现包坏掉了,于是重下。。。还是坏掉!第三次也不行,折腾了一下午,最后放弃了,还好貌似只有Sample的 最后一点点没解压开,没什么大碍。
本来只是以为自己只是火星了而已,装好一看,完。。。彻底冥王星了,DX11的Preview版出了!真是又激动又懊悔,粗略看了看,新特性真是太令人激 动了,主要有以下几点:
一、SM5.0 从类C变成类C++了,有类有继承有虚函数,太夸张了。。。
二、支持Shader动态 Link,DX9里面就有个 FragmentLinker,不太好用,DX10直接取消了,这次变本加厉的又回来了!
三、渲染的多线程支持,我重点来谈谈这个
DX11提供了一个新的接口:
ID3D11DeviceContext,取 代了以前Device接口所有与渲染相关的功能,有两个类型:immediate和deferred,前者和现在的效果一样,收到渲染指令就立即执行,而 后者则会将命令缓存起来,由用户决定何时执行 。
在例子MultithreadedRendering11中,渲染了三面带反射的镜子和一个人物模型,Sample创建了四个Context,三个 deferred用于镜子反射表面的渲染,一个immediate用于最终场景,Sample创建了三个线程,渲染帧开始时,首先并行的执行三个镜子反射 的渲染,完成后,在主线程顺序执行三个Context,然后用immediate的Context渲染最终场景。
由这个例子,我们来展望一下美好的未来:所有的渲染表面都可以并行执行,比如水面、镜子、甚至Shadow Map,并行的进行场景剪裁,使得多核 CPU的使用更有效率。
DX11预计在今年年底推出,于Windows7捆绑,到那时,四核CPU应该已经普及了吧。。。
7. 多Pass渲染体系与多线程渲染的矛盾
最近为了实现多光源和多阴影的渲染,把渲染系统改成了多Pass的,对每一个可见光源进行一次光照、ShadowMap和最终阴影的渲染,虽然这样等于是 把整个场景重复渲染了很多次,但为了实现灵活的实时光照系统,这似乎是唯一的办法了。
但实践后发现,阴影和光照会随着骨骼动画的播放而闪烁,甚至镜头的移动也会造成闪烁,究其原因,还是逻辑线程和渲染线程的同步问题,由于对场景内的同一个 物体渲染了多次,而逻辑线程又在不停的更新摄像机和骨骼动画数据,导致了两Pass渲染取到的数据很可能不一致,造成了光照和阴影的闪烁。
所以共享数据结构必须做一些修改,在多Pass渲染开始前进行一次备份,渲染中只取备份数据,这样就保证了多次渲染的数据一致性了
也就是加这么两个简单的set和get方法,在渲染相关数据读取时调用get,逻辑相关时调用read
template <class T>
struct SharedData
{
T m_pData[DATACENTER_CACHE];
T m_kCloneData;
int m_iIndex;
SharedData()
{
ZeroMemory( m_pData, DATACENTER_CACHE * sizeof(T) );
m_iIndex = 0;
}
void Write( T& rData )
{
int iNewIndex = m_iIndex == DATACENTER_CACHE - 1 ? 0 : m_iIndex + 1;
m_pData[iNewIndex] = rData;
m_iIndex = iNewIndex;
}
T& Read()
{
return m_pVector[m_iIndex];
}
void Set()
{
m_kCloneData = Read();
}
T& Get()
{
return m_kCloneData;
}
};
8. 几种多线程3D引擎架构的比较
首先我们得明确3D引擎使用多线程的目的所在:
1、在CPU上进行的逻辑计算(比如骨骼动画粒子发射等)不影响渲染速度
2、较差的GPU渲染速度的低下不影响逻辑速度
第一个目标已经很明确了,我来解释下需要达到第二个目标的原因:许多动作游戏的逻辑判定是基于帧的,所以在渲染较慢的情况下,逻辑不能跳帧,而仍然需要严 格执行才能保证游戏逻辑的正确性,这就导致了游戏速度的放慢,而实际上个人认为渲染保持15帧以上就已经可以正常进行游戏了。
在较差的GPU上跑《鬼泣4》《刺客信条》《波斯王子4》简直就像是慢镜头一样,完全没法玩。而实际上CPU跑满帧是没有问题的,如果能把逻辑帧和渲染帧 彻底分离,即使渲染帧达不到要求,但CPU仍能正确的执行游戏逻辑,就可以解决动作游戏对GPU要求过高的问题。
我们先来看多线程Ogre的两种架构,第一种是middle-level multithread
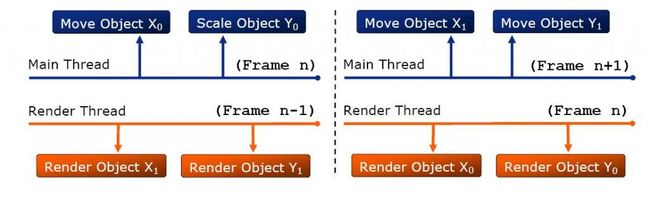
如上图所示,每个需渲染的实体被复制成了两份,主线程和渲染线程交替更新和渲染同一个实体的两个备份,并在一帧结束时同 步,这种解决方案达到了第一个目标而并没有达到第二个目标,同时两份实体的维护也相对复杂,并且没法为更多核数的CPU进行扩展优化。
第二种Ogre多线程的方法是 low-level multithread
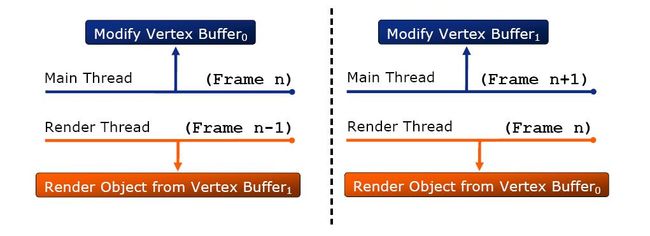
如图,将D3D对象复制两份,同样是在帧结束时同步并交换,和上面的优缺点类似。两种多线程Ogre的解决方案都是在引擎层完成的,对上层应用透明,对于 用户而言无需考虑多线程细节,这点是非常不错的。
接下来我们来看SIGGRAPH2008上,id soft提出的多线程3D引擎的方案
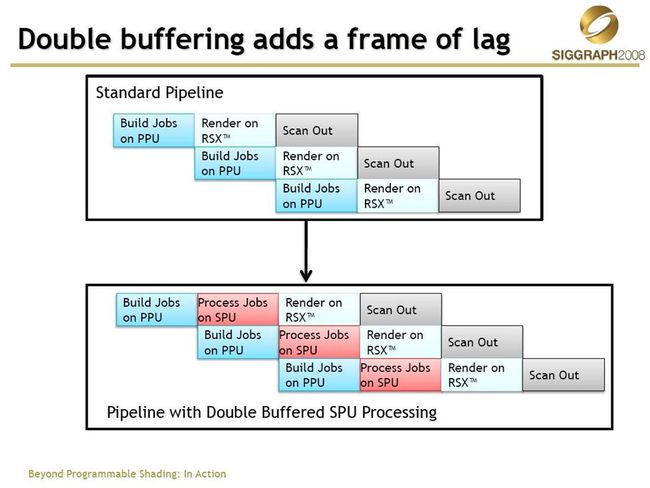
这里是已PS3的引擎结构为例的,与PC有较大的差别,其中SPU是Cell芯片的8个协处理器,拥有强大的并行能 力,id的解决方案在SPU上进行了诸如骨骼动画、形变动画、顶点和索引缓存的压缩、Progressive Mesh的计算等诸多内容,同时与PPU上的物理计算RSX上的渲染工作交错进行,最大化的利用了PS3的硬件结构,最终的游戏产品《Rage》很快就会 面世了!
最后是我的解决方案
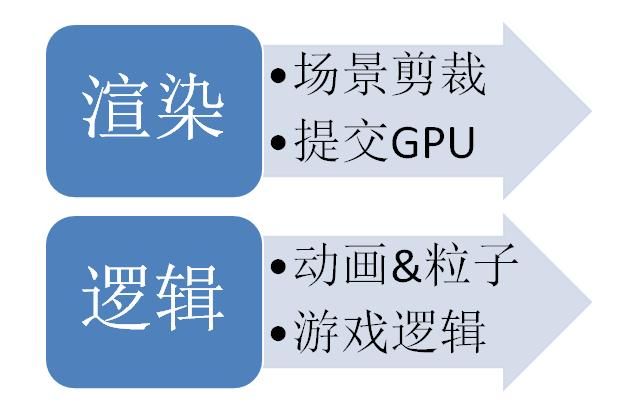
特点是逻辑完全分离,无需同步,虽然成功的达到了文章开始提出的两个目标,但对于引擎的使用者必须考虑多线程的诸多问题, 各种计算需放在哪个线程,如何在两个线程间交互,都需要深入思考,所以要应用到实际的游戏制作,恐怕还有很长的一段路要走。
结合目前的架构和上面看到的几种多线程架构,同时也为了迎接DX11的到来,我准备将我的方案进一步改进成如下所示
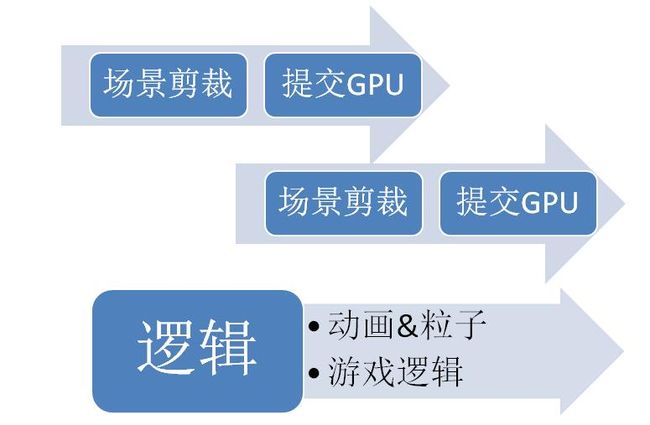
场景剪裁与提交渲染交替进行,并在渲染帧末进行一次同步,而多个渲染表面的场景剪裁可再并行执行。
图片多,文字少,需更详细资料 请自行google,本文就此结束!
from http://www.cppblog.com/flagship/category/9250.html