Boosting(Adaboost+Haar-like人脸识别)
http://blog.csdn.net/xiaowei_cqu/article/details/7670703
毕设算是告一段落,里面用了一点点人脸识别,其实完全是OpenCV自带的,源自两篇论文:
P. Viola and M. Jones. Rapid object detection using a boosted cascade of simple features.
R. Lienhart and J. Maydt. An Extended Set of Haar-like Features for Rapid Object Detection.
转载请注明出处:http://blog.csdn.net/xiaowei_cqu/article/details/7670703
Paul Viola 和Miachael Jones等利用Adaboost算法构造了人脸检测器,称为Viola-Jones检测器,取得很好的效果。之后Rainer Lienhart和Jochen Maydt用对角特征,即Haar-like特征对检测器进行扩展。OpenCV中自带的人脸检测算法即基于此检测器,称为“Haar分类器”。
Haar-like特征可由下图表示:

每个特征由2~3个矩形组成,在这些小波示意图中,浅色区域表示“累加数据”,深色区域表示“减去该区域的数据”。分别检测边界、线、中心特征,这些特征可表示为:
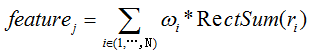
其中, wi 为矩形的权,RectSum(ri) 为矩形 ri 所围图像的灰度积分, N 是组成 featurej 的矩形个数。
Adaboost是一种基于统计的学习算法,在学习过程中不断根据事先定义的各个正例和反例的特征所起的效果调整该特征的权值,最终按照特征的性能的好坏给出判断准则。
其基本思想是利用分类能力一般的弱分类器通过一定的方法叠加(boost)起来,构成分类能力很强的强分类器。Adaboost训练强分类器的算法描述如下:
给定一系列训练样本 (x1,y1),(x2,y2),...(xn,yn),其中 xi 表示第 i 个样本, yi=1 时为正样本(人脸), yi=0 表示负样本(非人脸)。对每个特征 featurej ,训练一个弱分类器 hj(x),之后对每个特征生成的弱分类器计算权重误差:
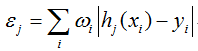
将具有最小误差 ej 的分类器叠加到强分类器中,并更新训练样本的概率分布:
![]()
其中![]() , ei=0 表示样本 xi 被正确分类,否则 ei=1 表示未被正确分类。最终构成强分类器:
, ei=0 表示样本 xi 被正确分类,否则 ei=1 表示未被正确分类。最终构成强分类器:
![]()
其中 b 为设置的阈值,默认为0。
级联强分类器示意图如下:

Viola-Jones检测器利用瀑布(Cascade)算法分类器组织为筛选式的级联分类器,级联的每个节点是AdaBoost训练得到的强分类器。在级联的每个节点设置阈值 b,使得几乎所有人脸样本都能通过,而绝大部分非人脸样本不能通过。节点由简单到复杂排列,位置越靠后的节点越复杂,即包含越多的弱分类器。这样能最小化拒绝图像但区域时的计算量,通知保证分类器的高检测率和低拒绝率。例如在识别率为99.9%,拒绝率为50%时,(99.9%的人脸和50%的非人脸可以通过),20个节点的总识别率为 :![]()
而错误接受率仅为:![]()
*另外有关于Haar矩形特征的博文,请参见:《计算Haar特征个数》、《利用积分图像法快速计算Haar特征》