通用性与性能间的妥协-Direct3D 10
在过去的10年中,OpenGL与Direct3D的渲染管道模型都已经取得了重大的进展,自2002年的DirectX 9.0到DirectX 9.0c便是管道模型从固定管道到可编程管道的过渡。这之间每一步的变化都反映出设计者通用性、性能和成本上所做出的妥协。

Intel的G965图形芯片便是这种妥协的最好诠释之一,其先进的内部硬件设计中有许多可编程的渲染元件,但在那之外还不得不保留了许多专用的处理单元。
GPU与CPU在计算范畴的最大区别在于有绪计算以及无绪计算,在有绪计算中GPU得以与强大的浮点计算能力超越CPU,依靠OpenGL与Direct3D这些中间件图形应用程序的编写可以拜托直接对图形硬件寄存器的访问,把这个过程通过API交由OpenGL与Direct3D这些中间件来完成,不过解析运行这些中间件却是由CPU来完成,换句话说不过GPU运行的指令诠释是由CPU来完成的,而随着GPU处理能力的飞速发展,CPU的指令诠释速度越来越跟不上GPU发展的步伐。这些问题在GeForce 7系列、Radeon X1K系列等最新的图形GPU中表现的尤为明显。因此,把CPU从GPU指令解析中解脱出来,把更多的工作交由GPU独立完成便是近年图形显示领域最关注的话题。
与之前的Direct3D版本一样,Direct3D 10同样是由应用程序开发者、硬件设计师以及API/架构师三方合作下设计的,旨在解决目前图形编程所遭遇的一些限制,创造出缓和这些问题的解决方案:
1.状态(state)改变的代价过高。 改变任何类型的状态(顶点格式、纹理、shader、shader参数、混合模式,等等)都会付出很大代价。优化方法通常是通过查询对象状态来排序,减少API状态改变次数;减少外观的改变;或者使用基于shader的技术,使用shader来决定状态。对于后者,例子之一就是把多张纹理打包为一张纹理地图(texture map)(也称为纹理地图集),通过纹理坐标变换,来索引相应的子纹理。
2. 硬件加速器性能变化太多。 应用程序不得不编写一系列分支语句,以保证在不同硬件上都能正常运行。这些问题会影响到程序的特性设置,资源管理,算法精度,以及储存格式。
3. CPU和GPU之间频繁的同步。传统的图形管道允许有限制的重新使用管道当前产生的数据,作为下一个处理步骤的输入数据。Render-to-texture就是这种机制的最好例子之一,所渲染的图片接下来能被当作纹理使用,最小化CPU的干涉。但是,产生新顶点数据,或者创建立方贴图就需要CPU与GPU进行更多的协调和通信,降低了效率。
4. 指令以及数据类型的限制。通常都以精度和所支持的流程控制指令来衡量vertex shader,同样的方法也用来衡量pixel shader,但是,无论是pixel还是vertex shader都不支持整数指令。此外,出于对pixel shader精确性的要求,还指定了浮点算法。应用程序要么不使用这些额外的功能,要么模仿他们的使用。基于表格功能的计算就是例子之一。
5. 资源限制。 纹理读取的次数、纹理范围、程序指令,等等,都受到限制。应用程序不得不压缩算法,或者把它们分为多个shader pass。因此,还出现了对自动划分shader程序的研究。
当前图形管道及Shader Model 4.0
我们的系统建立于PC、工作站以及XBOX平台上的应用程序可编程管道。在Direct3D 7之后图形渲染管道分为两个编程阶段,一个用来处理顶点数据(Vertex Engine),一个用来处理像素(Pixel Shader)。包括Direct3D 10在内我们可以把顶点引擎及像素渲染器的发展分为4代。
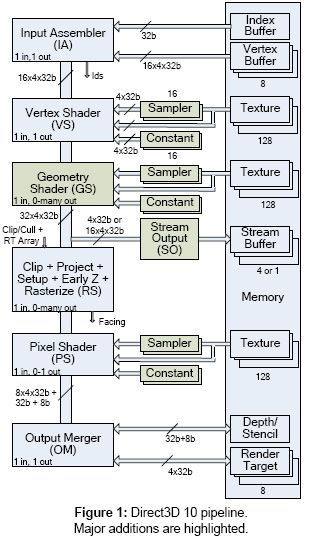
目前大多数的顶点引擎及像素渲染器都是以并行的状态来处理相互独立的顶点及像素数据,典型的硬件现实中Pixel Shader的数量要比Vertex Shader多很多,比如Radeon X1950XTX中Pixel Shader:Vertex Shader就是16:8,GeForce 7900GTX是24:8。这反映了典型的3D游戏渲染过程中像素处理的工作量要比顶点多很多。
Shader Model 4.0:
在Shader Model3.0版本的图形处理核心中,可编程的渲染管线都是通过每个阶段独立的虚拟机来实现。Direct3D 10定义了一个称为Common Core的虚拟机,作为每一个阶段的编程基础以及向下兼容之前的Direct3D版本,Common Core这个虚拟机保留了以前模型中许多特性,比如浮点运算操作这些,在这之外Common Core还增加了一下特性:
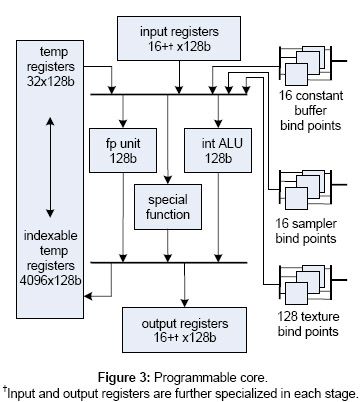
32-bit的整数指令(数学运算,位运算以及转换);
通用和索引寄存器将使用统一的内存池(4096 x 4);
独立的不过滤或者过滤内存读取指令(加载和采样指令);
不相关(decoupled)的纹理绑定点(128)和采样状态(16);
支持阴影贴图采样;
多层(16)常量(参数)缓冲(4096 x 4);
借助于Common Core这个统一的模型,GPU上的各种算法、逻辑和流程控制指令更接近于CPU,这些改进将在未来几年内解决目前困扰着开发者的问题,另寄存器、纹理邦定点以及指令存储空间都得到明显的提升。很明显的一点区别是借助于Common Core的虚拟化能力,图形硬件并不需要像以往一样增加相同数量的专用纹理处理单元来提升纹理性能。
虽然Shader Model4.0帮助开发者实现了统一的API调用,无需再区分Vertex指令与Pixel指令,但在Shader Model4.0中数据的呈现方式、算法精度、行为等都比以前的版本有更严厉的规范。为了保证这些内容在不同时代系统(主要是Windows)中的可移植性,开发者被告知需要尽可能的在所有地方都避免使用自定义的行为,需要遵循CPU的标准。为了获得精确的行为,Shader Model4.0时用了IEEE-754定义的单精度浮点数据呈现方式,通过该定义非规格化数将被近似为0,通过这样在不同硬件间建立良好的定义、一致的行为。
被广泛应用的高级着色语言HLSL10
高级着色语言广泛,迅速的被人们所接受,无疑显示了这种语言的重要性。为了支持新管线的特性,我们对高级着色语言――HLSL也提出了一些新的目标。简单的说,我们希望应用程序开发者使用HLSL高效的开发程序,而不需要了解虚拟机的复杂细节,比如,寄存器名称或常量缓冲索引。我们把目标精炼为以下几个小点:
1:应用程序不需要了解资源是如何配置和分配的。
2:把bind-by-position作为主要的绑定机制,而不是现在的bind-by-name。
3:程序员不再需要编写中间(汇编)语言代码
第一个目标主要用于解决下面这个问题:当前系统中,应用程序开发者需要学会控制常量储存空间中的参数布局。开发者需要对多个shader进行全局分配和布局(global allocation and placement),以便在多个shader之间共享某些变量。通过在每个管线阶段添加的多个常量缓冲,我们相信,编译器有足够的信息能自动对缓冲进行布局,当然,程序员还是要控制把参数分配到常量缓冲中的操作。我们对语言进行了扩展,允许把缓冲名作为参数的一部分,进行声明。
第二个目标则是设计思想的改变,主要与性能和未来的进一步发展有关系。Bind-by-name主要用于几个地方:对多个shader之间输入和输出数据进行匹配,让vertex shader的布局与vertex shader进行匹配,等等。虽然运行时可以让源数据和目标数据之间的名字匹配操作进行的比较高效,并且实现源—目标对缓存,但我们觉得这些只会带来不必要的复杂性,并且为运行时添加额外的负载。新系统中,将在多个方面发生变化。Shader的输出和输入将与签名(signature)相关,这和C总的函数原形有些类似。只有当前一阶段的输出和后一阶段的输入兼容时,管线才是有效的。兼容意味着输入和输出间element-by-element的对应。这里,我们允许下一阶段的管线,不使用上一阶段拖尾的(trailing)的输出数据。Bind-by-postion通用影响到IA和SO阶段的顶点缓冲绑定。但是,对这几个阶段,我们将创建独立的对象来封装(encapsulate)绑定,让代价较大的匹配操作只在创建时运行一次。第三个目标是比较具有争议性的,它表示我们的实现将不支持使用使用中间语言编写的shader作为输入。我们认为着色程序的发展已经达到了一定复杂程度,因此,手写的IL很难比编译器产生的代码高效。此外,当我们改进优化技巧,联接,以及与驱动的交互时,无法保证对手写IL代码的支持和兼容。作为诊断技术,系统将支持编译器生成中间代码作为输出,但是,我们不允许应用程序开发者修改编译器的输出,并把它注入到运行时中。
如何最优化编译器生成的代码性能,有很多问题。首先,是优化的范围,驱动可能允许把中间语言转换为特定机器语言时进行优化。随着shader复杂性的增加,确保开发者在优化之上,有充分的控制权,改变操作的执行顺序是相当重要的。特别是需要保证关键代码的恒定性(invariance),多pass算法应该能生成同样的中间值,以便把这些值复制到分散的shader中。我们考虑了几种在源码上指定中间值的方案,比如,要求以一种特定的方式来编译子程序,而不管这个子程序是否是内连的。但是,研究最终让我们选择了更加常见的方法:使用与驱动编译器相关的,可选择的,定义良好的优化级别。
请注意,我们首选的使用模型是在编写shader时,编译HLSL代码,在程序运行时通过驱动编译IL代码。这样的目的是希望减少程序运行时,编译shader所花费的时间。但是,在运行时再把HLSL编译为IL也是可以的。
HLSL-FX 10:
我们注意到,编程管道的成功,改变了人们的观点,shader程序不但是引擎的一部分,同时,也是艺术家创作工具之一。为了适应这方面的应用,Effect(FX)系统对HLSL进行了扩展,允许使用它来初始化管线的固定功能部分。这和CgFX以及Cg所描述的方法很类似。虽然这些方法有共同的基础,但HLSL-FX是进行了革新的。我们的目标是,FX首先需要满足实时运行的需求,其次,才是作为内容创建者的工具。基于一些历史原因,这两者在很多方面都是由差别的。创作工具常常通过牺牲性能来换取灵活性,而我们的运行时则把性能放在第一位。
通过我们积累的经验和努力,FX系统在易用性和性能方便都有了充分的提高。最终FX,HLSL,API,运行时,以及管线都紧密的结合到一起,作为互补的解决方案。我们同样对频繁的状态操作进行了改变,分离了名字查找以及匹配操作。
再次来讨论处理状态改变的方式。构建应用程序的方法之一是渲染一系列几何体,每个几何体都有其各自的管线配置(一个Effect)。通过设置常量缓冲中的shader参数,纹理绑定,以及其他固定功能的状态,来传递参数给Effect。为了最大化性能,应用程序应该使用一个Effect来绘制所有物体。这是场景管理系统中,传统的状态排序解决方案。但是,对一个Effect来说,可能有几个层次的参数,比如,当前时间和观察点是属于per-frame的状态;纹理或顶点数据则是角色的静态状态;位置和姿势则是对象的动态状态,等等。我们使用了一个单独的常量缓冲来储存shader每个层次的参数,当绘制物体时,将直接绑定保存静态参数的常量缓冲,保存动态参数的缓冲则要经过更新后再绑定。
在实际应用中,应用程序并不能总是通过Effect来排序对象。通常还可能有其他的机制,控制着绘图,比如物体的远近程度,透明度,等等。我们已经把Direct3D 10系统状态改变的代价进行了充分缩减,因此,重新配置整个管道也是很高效的。