ubuntu11.04上cloudera cdh3u0的hadoop和hbase分布式安装
概述:
业务需要较实时的处理大数据量,并提供大吞吐量的读写,hbase作为一个可选的列数据库,记录一下安装过程,待查。
hbase的安装需要hadoop和zookeeper和hbase,生产环境下需要将zookeeper独立安装,并保证整个集群没有单点。
hbase软件选择cloudera的cdh3u0,apache的版本需要重新编译hadoop0.20.2-appender版以保证没有数据丢失。
1、规划机器
使用12个虚拟机作为集群测试,ip为192.168.0.221-232,hostname为ubuntu-1到ubuntu-12其中
2、安装操作系统及必要软件
安装ubuntu11.04 server X64版,hadoop推荐2.6.30以上内核
# sudo apt-get install ssh
# sudo apt-get install vim
# sudo apt-get install rsync
创建hadoop用户
在所有机器上,密码为hadoop,并加入到sudo组
# sudo adduser hadoop
# sudo usermod -G sudo hadoop
安装jdk
从oracle下载jdk-6u24-linux-x64.bin,在所有的机器上安装
# ./jdk-6u24-linux-x64.bin
# sudo mv jdk1.6.0_24 /usr/local
解压cdh3u0软件
在所有机器创建cdh3目录
# mkdir /home/hadoop/cdh3
在221上解压hadoop和hbase
# tar zxvf hadoop-0.20.2-cdh3u0.tar.gz -C /home/hadoop/cdh3
# tar zxvf hbase-0.90.1-cdh3u0.tar.gz -C /home/hadoop/cdh3
在229上解压zookeeper
# tar zxvf zookeeper-3.3.3-cdh3u0.tar.gz -C /home/hadoop/cdh3
在221-228,232上修改/etc/profile
# sudo vim /etc/profile
添加
在229-231上修改/etc/profile
添加
ssh免密码登录
用hadoop用户登录所有机器,在/home/hadoop/下建立.ssh目录
运行
# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
这样会在~/.ssh/生成两个文件:id_dsa 和id_dsa.pub。
# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
拷贝authorized_keys到222-232
# scp /home/hadoop/.ssh/authorized_keys [email protected]:/home/hadoop/.ssh/
修改hosts文件
# sudo vim /etc/hosts
修改所有机器的/etc/hosts文件为
从221登录221-232,用hostname,第一次需要确认,以后就可以直接登录。
# ssh ubuntu-1
# ssh ubuntu-2
# ssh ubuntu-3
# ssh ubuntu-4
# ssh ubuntu-5
# ssh ubuntu-6
# ssh ubuntu-7
# ssh ubuntu-8
# ssh ubuntu-9
# ssh ubuntu-10
# ssh ubuntu-11
# ssh ubuntu-12
3、安装hadoop
在221和232上创建/data
# sudo mkdir /data
# sudo chown hadoop /data
在222和228上创建/disk1,/disk2,/disk3
# sudo mkdir /disk1
# sudo mkdir /disk2
# sudo mkdir /disk3
# sudo chown hadoop /disk1
# sudo chown hadoop /disk2
# sudo chown hadoop /disk3
修改/home/hadoop/cdh3/hadoop-0.20.2-cdh3u0/conf/hadoop-env.sh添加
修改/home/hadoop/cdh3/hadoop-0.20.2-cdh3u0/conf/core-site.xml添加
修改/home/hadoop/cdh3/hadoop-0.20.2-cdh3u0/conf/hdfs-site.xml添加
修改/home/hadoop/cdh3/hadoop-0.20.2-cdh3u0/conf/mapred-site.xml添加
修改/home/hadoop/cdh3/hadoop-0.20.2-cdh3u0/conf/masters添加
修改/home/hadoop/cdh3/hadoop-0.20.2-cdh3u0/conf/slaves添加
拷贝221的hadoop到222-228,232
# scp -r /home/hadoop/cdh3/hadoop-0.20.2-cdh3u0/ [email protected]:/home/hadoop/cdh3/
格式化hadoop文件系统
# hadoop namenode -format
启动hadoop,在221上运行
# start-all.sh
查看集群状态: http://192.168.0.221:50070/dfshealth.jsp
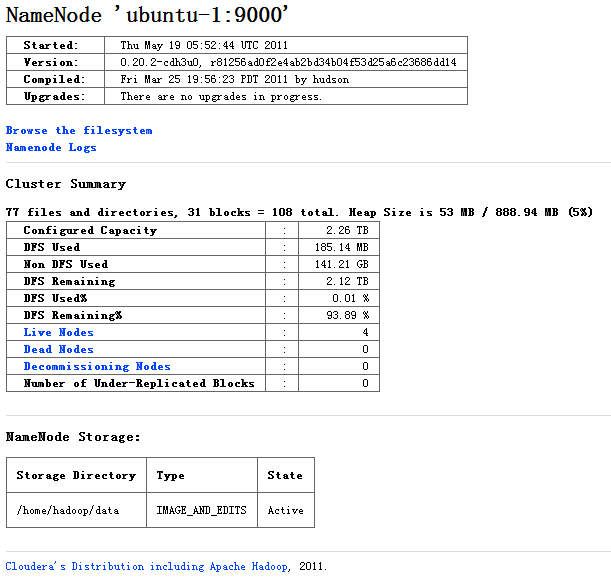
查看JOB状态: http://192.168.0.221:50030/jobtracker.jsp

4、安装zookeeper
在229-231上创建/home/hadoop/zookeeperdata目录
修改229的/home/hadoop/cdh3/zookeeper-3.3.3-cdh3u0/conf/zoo.cfg
拷贝229的hadoop到230,231
# scp -r /home/hadoop/cdh3/zookeeper-3.3.3-cdh3u0/ [email protected]:/home/hadoop/cdh3/
在229,230,231的/home/hadoop/zookeeperdata目录下建myid文件,内容分别为1,2,3
启动zookeeper,在229-231上分别执行
# zkServer.sh start
启动后可以使用
# zkServer.sh status
查看状态
5、安装hbase
在221上修改/home/hadoop/cdh3/hbase-0.90.1-cdh3u0/conf/hbase-env.sh添加
在221上修改/home/hadoop/cdh3/hbase-0.90.1-cdh3u0/conf/hbase-site.xml添加
在221上修改/home/hadoop/cdh3/hbase-0.90.1-cdh3u0/conf/regionservers添加
拷贝221的hbase到222-228,232
# scp -r /home/hadoop/cdh3/hbase-0.90.1-cdh3u0/ [email protected]:/home/hadoop/cdh3/
启动hbase
在221上执行
# start-hbase.sh
启动hbase的第二个HMaster
在232上执行
# hbase-daemon.sh start master
查看Master: http://192.168.0.221:60010/master.jsp

查看Region Server: http://192.168.0.222:60030/regionserver.jsp

查看ZK: http://192.168.0.221:60010/zk.jsp

6、说明
jps查看启动进程
221
222-228
229-231
232
启动顺序
1.hadoop
2.zookeeper
3.hbase
4.第二个HMaster
停止顺序
1.第二个HMaster, kill-9删除
2.hbase
3.zookeeper
4.hadoop
hbase的安装需要hadoop和zookeeper和hbase,生产环境下需要将zookeeper独立安装,并保证整个集群没有单点。
hbase软件选择cloudera的cdh3u0,apache的版本需要重新编译hadoop0.20.2-appender版以保证没有数据丢失。
1、规划机器
使用12个虚拟机作为集群测试,ip为192.168.0.221-232,hostname为ubuntu-1到ubuntu-12其中
| 机器名 | IP | 安装系统 |
| ubuntu-1 | 192.168.0.221 | hadoop namenode / hbase HMaster |
| ubuntu-2 | 192.168.0.222 | hadoop datanode / hbase HRegionServer |
| ubuntu-3 | 192.168.0.223 | hadoop datanode / hbase HRegionServer |
| ubuntu-4 | 192.168.0.224 | hadoop datanode / hbase HRegionServer |
| ubuntu-5 | 192.168.0.225 | hadoop datanode / hbase HRegionServer |
| ubuntu-6 | 192.168.0.226 | hadoop datanode / hbase HRegionServer |
| ubuntu-7 | 192.168.0.227 | hadoop datanode / hbase HRegionServer |
| ubuntu-8 | 192.168.0.228 | hadoop datanode / hbase HRegionServer |
| ubuntu-9 | 192.168.0.229 | zookeeper |
| ubuntu-10 | 192.168.0.230 | zookeeper |
| ubuntu-11 | 192.168.0.231 | zookeeper |
| ubuntu-12 | 192.168.0.232 | hadoop second namenode / hbase HMaster |
2、安装操作系统及必要软件
安装ubuntu11.04 server X64版,hadoop推荐2.6.30以上内核
# sudo apt-get install ssh
# sudo apt-get install vim
# sudo apt-get install rsync
创建hadoop用户
在所有机器上,密码为hadoop,并加入到sudo组
# sudo adduser hadoop
# sudo usermod -G sudo hadoop
安装jdk
从oracle下载jdk-6u24-linux-x64.bin,在所有的机器上安装
# ./jdk-6u24-linux-x64.bin
# sudo mv jdk1.6.0_24 /usr/local
解压cdh3u0软件
在所有机器创建cdh3目录
# mkdir /home/hadoop/cdh3
在221上解压hadoop和hbase
# tar zxvf hadoop-0.20.2-cdh3u0.tar.gz -C /home/hadoop/cdh3
# tar zxvf hbase-0.90.1-cdh3u0.tar.gz -C /home/hadoop/cdh3
在229上解压zookeeper
# tar zxvf zookeeper-3.3.3-cdh3u0.tar.gz -C /home/hadoop/cdh3
在221-228,232上修改/etc/profile
# sudo vim /etc/profile
添加
Xml代码


- JAVA_HOME=/usr/local/jdk1.6.0_24
- JRE_HOME=$JAVA_HOME/jre
- CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
- HADOOP_HOME=/home/hadoop/cdh3/hadoop-0.20.2-cdh3u0
- HBASE_HOME=/home/hadoop/cdh3/hbase-0.90.1-cdh3u0
- PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HBASE_HOME/bin:$PATH
- export JAVA_HOME JRE_HOME CLASSPATH HADOOP_HOME HBASE_HOME PATH
添加
Xml代码
- JAVA_HOME=/usr/local/jdk1.6.0_24
- ZOOKEEPER_HOME=/home/hadoop/cdh3/zookeeper-3.3.3-cdh3u0
- PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf:$PATH
- export JAVA_HOME ZOOKEEPER_HOME PATH
用hadoop用户登录所有机器,在/home/hadoop/下建立.ssh目录
运行
# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
这样会在~/.ssh/生成两个文件:id_dsa 和id_dsa.pub。
# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
拷贝authorized_keys到222-232
# scp /home/hadoop/.ssh/authorized_keys [email protected]:/home/hadoop/.ssh/
修改hosts文件
# sudo vim /etc/hosts
修改所有机器的/etc/hosts文件为
Xml代码
- 127.0.0.1 localhost
- 192.168.0.221 ubuntu-1
- 192.168.0.222 ubuntu-2
- 192.168.0.223 ubuntu-3
- 192.168.0.224 ubuntu-4
- 192.168.0.225 ubuntu-5
- 192.168.0.226 ubuntu-6
- 192.168.0.227 ubuntu-7
- 192.168.0.228 ubuntu-8
- 192.168.0.229 ubuntu-9
- 192.168.0.230 ubuntu-10
- 192.168.0.231 ubuntu-11
- 192.168.0.232 ubuntu-12
# ssh ubuntu-1
# ssh ubuntu-2
# ssh ubuntu-3
# ssh ubuntu-4
# ssh ubuntu-5
# ssh ubuntu-6
# ssh ubuntu-7
# ssh ubuntu-8
# ssh ubuntu-9
# ssh ubuntu-10
# ssh ubuntu-11
# ssh ubuntu-12
3、安装hadoop
在221和232上创建/data
# sudo mkdir /data
# sudo chown hadoop /data
在222和228上创建/disk1,/disk2,/disk3
# sudo mkdir /disk1
# sudo mkdir /disk2
# sudo mkdir /disk3
# sudo chown hadoop /disk1
# sudo chown hadoop /disk2
# sudo chown hadoop /disk3
修改/home/hadoop/cdh3/hadoop-0.20.2-cdh3u0/conf/hadoop-env.sh添加
Xml代码
- export JAVA_HOME=/usr/local/jdk1.6.0_24
Xml代码
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/data</value>
- <description>A base for other temporary directories.</description>
- </property>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://ubuntu-1:9000/</value>
- <description>The name of the default file system. A URI whose
- scheme and authority determine the FileSystem implementation. The
- uri's scheme determines the config property (fs.SCHEME.impl) naming
- the FileSystem implementation class. The uri's authority is used to
- determine the host, port, etc. for a filesystem.</description>
- </property>
Xml代码
- <property>
- <name>dfs.name.dir</name>
- <value>/home/hadoop/data</value>
- </property>
- <property>
- <name>dfs.data.dir</name>
- <value>/disk1,/disk2,/disk3</value>
- </property>
- <property>
- <name>dfs.permissions</name>
- <value>false</value>
- </property>
- <property>
- <name>dfs.replication</name>
- <value>3</value>
- </property>
Xml代码
- <property>
- <name>mapred.job.tracker</name>
- <value>ubuntu-1:9001</value>
- <description>The host and port that the MapReduce job tracker runs
- at. If "local", then jobs are run in-process as a single map
- and reduce task.
- </description>
- </property>
Xml代码
- ubuntu-12
Xml代码
- ubuntu-2
- ubuntu-3
- ubuntu-4
- ubuntu-5
- ubuntu-6
- ubuntu-7
- ubuntu-8
# scp -r /home/hadoop/cdh3/hadoop-0.20.2-cdh3u0/ [email protected]:/home/hadoop/cdh3/
格式化hadoop文件系统
# hadoop namenode -format
启动hadoop,在221上运行
# start-all.sh
查看集群状态: http://192.168.0.221:50070/dfshealth.jsp
查看JOB状态: http://192.168.0.221:50030/jobtracker.jsp
4、安装zookeeper
在229-231上创建/home/hadoop/zookeeperdata目录
修改229的/home/hadoop/cdh3/zookeeper-3.3.3-cdh3u0/conf/zoo.cfg
Xml代码
- # The number of milliseconds of each tick
- tickTime=2000
- # The number of ticks that the initial
- # synchronization phase can take
- initLimit=10
- # The number of ticks that can pass between
- # sending a request and getting an acknowledgement
- syncLimit=5
- # the directory where the snapshot is stored.
- dataDir=/home/hadoop/zookeeperdata
- # the port at which the clients will connect
- clientPort=2181
- server.1=ubuntu-9:2888:3888
- server.2=ubuntu-10:2888:3888
- server.3=ubuntu-11:2888:3888
# scp -r /home/hadoop/cdh3/zookeeper-3.3.3-cdh3u0/ [email protected]:/home/hadoop/cdh3/
在229,230,231的/home/hadoop/zookeeperdata目录下建myid文件,内容分别为1,2,3
启动zookeeper,在229-231上分别执行
# zkServer.sh start
启动后可以使用
# zkServer.sh status
查看状态
5、安装hbase
在221上修改/home/hadoop/cdh3/hbase-0.90.1-cdh3u0/conf/hbase-env.sh添加
Xml代码
- export JAVA_HOME=/usr/local/jdk1.6.0_24
- export HBASE_MANAGES_ZK=false
Xml代码
- <property>
- <name>hbase.rootdir</name>
- <value>hdfs://ubuntu-1:9000/hbase</value>
- </property>
- <property>
- <name>hbase.cluster.distributed</name>
- <value>true</value>
- </property>
- <property>
- <name>hbase.master.port</name>
- <value>60000</value>
- </property>
- <property>
- <name>hbase.zookeeper.quorum</name>
- <value>ubuntu-9,ubuntu-10,ubuntu-11</value>
- </property>
Java代码
- ubuntu-2
- ubuntu-3
- ubuntu-4
- ubuntu-5
- ubuntu-6
- ubuntu-7
- ubuntu-8
# scp -r /home/hadoop/cdh3/hbase-0.90.1-cdh3u0/ [email protected]:/home/hadoop/cdh3/
启动hbase
在221上执行
# start-hbase.sh
启动hbase的第二个HMaster
在232上执行
# hbase-daemon.sh start master
查看Master: http://192.168.0.221:60010/master.jsp
查看Region Server: http://192.168.0.222:60030/regionserver.jsp
查看ZK: http://192.168.0.221:60010/zk.jsp
6、说明
jps查看启动进程
221
Xml代码
- JobTracker
- NameNode
- HMaster
Xml代码
- HRegionServer
- DataNode
- TaskTracker
Xml代码
- QuorumPeerMain
Xml代码
- SecondaryNameNode
- HMaster
1.hadoop
2.zookeeper
3.hbase
4.第二个HMaster
停止顺序
1.第二个HMaster, kill-9删除
2.hbase
3.zookeeper
4.hadoop