nginx源码分析--内存对齐处理
1.nginx内存对齐主要是做2件事情:
1) 内存池的内存地址对齐;
2) 长度按照2的幂取整.因为前面结构体已经是对齐了,如果后面的内存池每一小块不是2的幂,那么后面的就不能对齐
2.通用内存对齐理论
内存对齐:数据项只能存储在地址是数据项大小的整数倍的内存位置上
例如int类型占用4个字节,地址只能在0,4,8等位置上。
数据的对齐(alignment)
指数据的地址和由硬件条件决定的内存块大小之间的关系。一个变量的地址是它大小的倍数的时候,这就叫做自然对齐(naturally aligned)。例如,对于一个32bit的变量,如果它的地址是4的倍数,-- 就是说,如果地址的低两位是0,那么这就是自然对齐了。所以,如果一个类型的大小是2n个字节,那么它的地址中,至少低n位是0。对齐的规则是由硬件引起的。一些体系的计算机在数据对齐这方面有着很严格的要求。在一些系统上,一个不对齐的数据的载入可能会引起进程的陷入。在另外一些系统,对不对齐的数据的访问是安全的,但却会引起性能的下降。在编写可移植的代码的时候,对齐的问题是必须避免的,所有的类型都该自然对齐。
预对齐内存的分配
在大多数情况下,编译器和C库透明地帮你处理对齐问题。POSIX 标明了通过malloc( ), calloc( ), 和realloc( ) 返回的地址对于任何的C类型来说都是对齐的。在Linux中,这些函数返回的地址在32位系统是以8字节为边界对齐,在64位系统是以16字节为边界对齐的。有时候,对于更大的边界,例如页面,程序员需要动态的对齐。虽然动机是多种多样的,但最常见的是直接块I/O的缓存的对齐或者其它的软件对硬件的交互,因此,POSIX 1003.1d提供一个叫做posix_memalign( )的函数
2.1对较小结构体进行机器字对齐--避免多次读
对于现代计算机硬件来说,内存只能通过特定的对齐地址(比如按照机器字)进行访问。举个例子来说,比如在64位的机器上,不管我们是要读取第0个字节还是要读取第1个字节,在硬件上传输的信号都是一样的。因为它都会把地址0到地址7,这8个字节全部读到CPU,只是当我们是需要读取第0个字节时,丢掉后面7个字节,当我们是需要读取第1个字节,丢掉第1个和后面6个字节。
当我们要读取的字节刚好落在两个机器字内时,就出现两次访问内存的情况,同时通过一些逻辑计算才能得到最终的结果。
因此,为了更好的提升性能,我们须尽量将结构体做到机器字(或倍数)对齐,而结构体中一些频繁访问的字段也尽量安排在机器字对齐的位置。
操作系统的默认对齐系数
每个操作系统都有自己的默认内存对齐系数,如果是新版本的操作系统,默认对齐系数一般都是8,因为操作系统定义的最大类型存储单元就是8个字节,例如 long long,不存在超过8个字节的类型(例如int是4,char是1,long在32位编译时是4,64位编译时是8)。当操作系统的默认对齐系数与第一节所讲的内存对齐的理论产生冲突时,以操作系统的对齐系数为基准。
编译器是按照什么样的原则进行对齐的。首先有3个重要的概念:自身对齐值,指定对齐值和有效对齐值。
自身对齐值:即数据类型的自身的对齐值。例如char型的数据,其自身对齐值为1字节;short型的数据,其自身对齐值为2字节;int,float,long类型,其自身对齐值为4字节;double类型,其自身对齐值为4字节;而struct和class类型的数据其自身对齐值为其成员变量中自身对齐值最大的那个值。
指定对齐值:#pragma pack (value)时指定的对齐值value
有效对齐值:上述两个对齐值中最小的那个。
我们一般说的对齐在N上,都是指有效对齐在N上。
2.2对较大结构体进行CACHE LINE对齐--避免占用过多CACHE LINE
我们知道,CACHE与内存交换的最小单位为CACHE LINE,一个CACHE LINE大小以64字节为例。当我们的结构体大小没有与64字节对齐时,一个结构体可能就要占用比原本需要更多的CACHE LINE。比如,把一个内存中没有64字节长的结构体缓存到CACHE时,即使该结构体本身长度或许没有还没有64字节,但由于其前后搭占在两条CACHE LINE上,那么对其进行淘汰时就会淘汰出去两条CACHE LINE。
这还不是最严重的问题,非CACHE LINE对齐结构体在SMP机器上容易引发名为错误共享的CACHE问题。
#include <stdio.h>
struct xx{
char b;
long long a;
int c;
char d;
};
int main()
{
struct xx bb;
printf("&a = %p\n", &bb.a);
printf("&b = %p\n", &bb.b);
printf("&c = %p\n", &bb.c);
printf("&d = %p\n", &bb.d);
printf("sizeof(xx) = %d\n", sizeof(struct xx));
return 0;
}

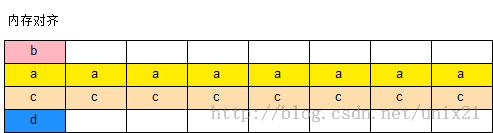
例如假设没有内存对齐,结构体xx的变量位置会出现如下情况:
struct xx{
char b; //0xffbff5e8
int a; //0xffbff5e9
int c; //0xffbff5ed
char d; //0xffbff5f1
};
操作系统先读取0xffbff5e8-0xffbff5ef的内存,然后在读取0xffbff5f0-0xffbff5f8的内存,为了获得值c,就需要将两组内存合并,进行整合,这样严重降低了内存的访问效率。

VC和GCC默认的都是4字节对齐,编程中可以使用#pragma pack(n)指定对齐模数。出现以上差异的原因在于,VC和GCC中对于double类型的对齐方式不同。
Win32平台下的微软VC编译器在默认情况下采用如下的对齐规则: 任何基本数据类型T的对齐模数就是T的大小,即sizeof(T)。比如对于double类型(8字节),就要求该类型数据的地址总是8的倍数,而char类型数据(1字节)则可以从任何一个地址开始。
Linux下的GCC奉行的是另外一套规则:任何2字节大小(包括单字节吗?)的数据类型(比如short)的对齐模数是2,而其它所有超过2字节的数据类型(比如long,double)都以4为对齐模数。
复杂类型(如结构)的默认对齐方式是它最长的成员的对齐方式,这样在成员是复杂类型时,可以最小化长度。
struct{char a;double b;}
在VC中,因为结构中存在double和char,按照最长数据类型对齐,char只占1B,但是加上后面的double所占空间超过8B,所以char独占8B;而double占8B,一共16Byte。
在GCC中,double长度超过4字节,按照4字节对齐,原理同上,不过char占4字节,double占两个4字节,一共12Byte。
3.Nginx中的内存处理
ngx_alloc.c部分代码
ngx_uint_t ngx_cacheline_size;
#if (NGX_HAVE_POSIX_MEMALIGN)
void *
ngx_memalign(size_t alignment, size_t size, ngx_log_t *log)
{
void *p;
int err;
err = posix_memalign(&p, alignment, size);
if (err) {
ngx_log_error(NGX_LOG_EMERG, log, err,
"posix_memalign(%uz, %uz) failed", alignment, size);
p = NULL;
}
ngx_log_debug3(NGX_LOG_DEBUG_ALLOC, log, 0,
"posix_memalign: %p:%uz @%uz", p, size, alignment);
return p;
}
#elif (NGX_HAVE_MEMALIGN)
void *
ngx_memalign(size_t alignment, size_t size, ngx_log_t *log)
{
void *p;
p = memalign(alignment, size);
if (p == NULL) {
ngx_log_error(NGX_LOG_EMERG, log, ngx_errno,
"memalign(%uz, %uz) failed", alignment, size);
}
ngx_log_debug3(NGX_LOG_DEBUG_ALLOC, log, 0,
"memalign: %p:%uz @%uz", p, size, alignment);
return p;
}
#endif
ngx_cpuinfo.c
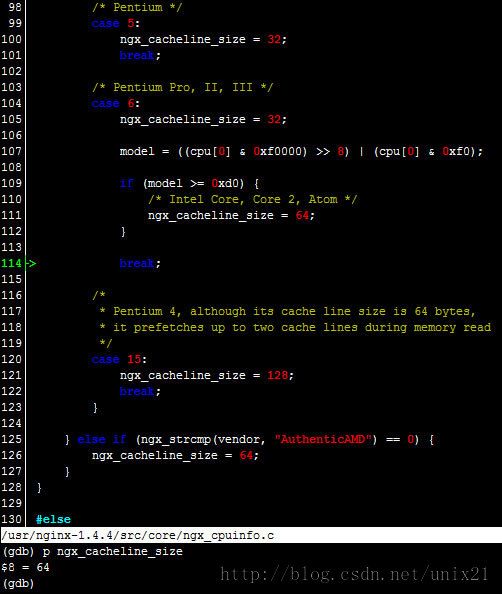
得到ngx_cacheline_size = 64;
ngx_config.h
#ifndef NGX_ALIGNMENT
#define NGX_ALIGNMENT sizeof(unsigned long) /* platform word */
#endif
#define ngx_align(d, a) (((d) + (a - 1)) & ~(a - 1))
#define ngx_align_ptr(p, a) \
(u_char *) (((uintptr_t) (p) + ((uintptr_t) a - 1)) & ~((uintptr_t) a - 1))
sizeof(unsigned long)=4
先分析 (((d) + (a - 1)) & ~(a - 1))表达式
两个参数d和a,d代表数据,a代表对其单位。假设a是8,那么用二进制表示就是1000,a-1就是0111. d + a-1之后在第四位可能进位一次(如果d的前三位不为000,则会进位。反之,则不会),~(a-1)是1111...1000,&之后的结过就自然在4位上对其了。注意二进制中第四位的单位是8,也就是以8为单位对其。
理解表达式 ~(a - 1)注意,其中a为2的幂,设右数第n位为非零位,则a-1为右数的n-1位均为1, 则有~(a-1)为最后的n-1位全为0;
显然可得一个数和2的幂进行 减一取反再按位与操作,即为该数减去(其与a求余的值)
这种计算地址或者长度对齐,取整的宏还是很有用的。cpu访问对齐的数据较快,不对齐的的int之类的,有可能区要多次内存访问才能取到值。
向上取整倍数,ngx_align内存对齐的宏,对于a,传入CPU的二级cache的line大小,通过ngx_cpuinf函数,可以获得ngx_cacheline_size的大小,一般intel为64或128
计算宏ngx_align(1, 64)=64,只要输入d<64,则结果总是64,如果输入d=65,则结果为128,以此类推。
进行内存池管理的时候,对于小于64字节的内存,给分配64字节,使之总是cpu二级缓存读写行的大小倍数,从而有利cpu二级缓存取速度和效率。
ngx_cpuinfo函数实际是调用了汇编代码,获取cpu二级缓存大小!
//==================================================
上面式子,当a等于2的幂的时候,比如,4,8,16等值时,
d加上(a-1) 之后的值肯定要比最小的a的倍数要大的。因为a为2的幂,所以(a - 1) 刚好后面几位都是连续的1,取反之后再相与一下之后,就把小于a的余数部分丢掉了。 不过如果a不是2的幂,比如a=3, d=1 ,那么推算一下,上面的计算就不成立了。
这种计算地址或者长度对齐,取整的宏还是很有用的。cpu访问对齐的数据跟快把,不对齐的的int之类的,有可能区要多次内存访问才能取到值出来。 写个简单的字符串内存池,AllocateString时打算把所有的字符串放到一个连续的内存块上,觉得还是把长度取整一下比较好。这样后续的对字符串的memcpy就是内存字对齐,更好吧。
//=================================================
ngx_palloc.c部分代码
ngx_align_ptr的调用
void *
ngx_palloc(ngx_pool_t *pool, size_t size)
{
u_char *m;
ngx_pool_t *p;
if (size <= pool->max) {
p = pool->current;
do {
m = ngx_align_ptr(p->d.last, NGX_ALIGNMENT);
if ((size_t) (p->d.end - m) >= size) {
p->d.last = m + size;
return m;
}
p = p->d.next;
} while (p);
return ngx_palloc_block(pool, size);
}
return ngx_palloc_large(pool, size);
}
ngx_memalign的调用
static void *
ngx_palloc_block(ngx_pool_t *pool, size_t size)
{
u_char *m;
size_t psize;
ngx_pool_t *p, *new, *current;
psize = (size_t) (pool->d.end - (u_char *) pool);
m = ngx_memalign(NGX_POOL_ALIGNMENT, psize, pool->log);
if (m == NULL) {
return NULL;
}
new = (ngx_pool_t *) m;
new->d.end = m + psize;
new->d.next = NULL;
new->d.failed = 0;
m += sizeof(ngx_pool_data_t);
m = ngx_align_ptr(m, NGX_ALIGNMENT);
new->d.last = m + size;
current = pool->current;
for (p = current; p->d.next; p = p->d.next) {
if (p->d.failed++ > 4) {
current = p->d.next;
}
}
p->d.next = new;
pool->current = current ? current : new;
return m;
}
ngx_http.c
ngx_align的调用
hash.bucket_size = ngx_align(64, ngx_cacheline_size);
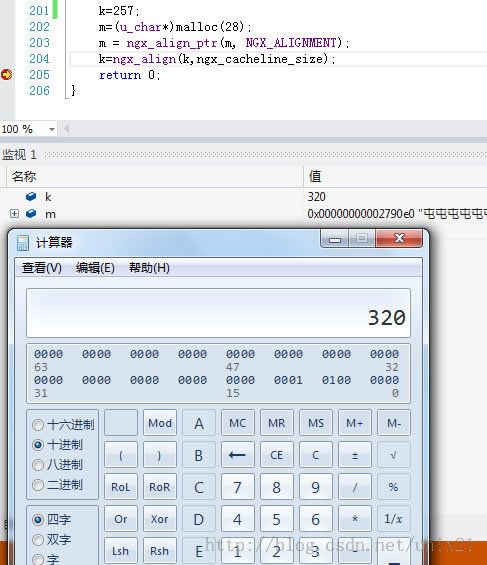
4.Nginx内存对齐使用举例
64=2的6次方
5.编译器对齐值
Visualstudio2012

参考《linux系统编程》好累啊,我翻译的<Linux system programming> 第八章 二 ;《Linux System Programming》中文版
Cache line
从CPU角度看内存访问对齐
如何高效的访问内存