HdfsSink原理解析
我们先了解几个概念:
- batchSize sink从channel中取batchSize数量的event才会flush,sync到hdfs
- transactionCapcity source在收集满transactionCapcity数量的event才会put到channel
接着看一下类图:
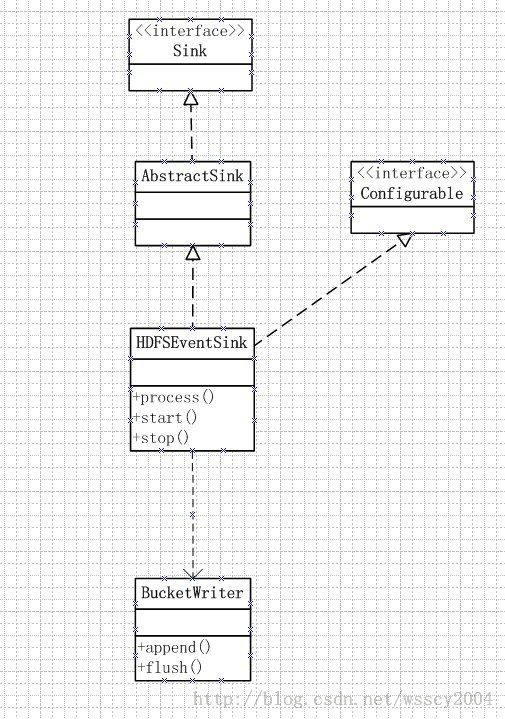
HDFSEventSink
HDFSEventSink,是我们在flume配置文件中指定的channel.type=hdfs时对应的java类。它主要有三个方法:
- start() 初始化线程池等
- stop() 清理工作
- process() SinkRunner调用的方法
process()
HDFS sink主要处理过程为process方法。
//循环batchSize次或者Channel为空
for (txnEventCount = 0; txnEventCount < batchSize; txnEventCount++) {
Event event = channel.take();
if (event == null) {
break;
}
......
//sfWriter是一个LRU缓存,缓存对文件Handler,最大打开文件由参数maxopenfiles控制
BucketWriter bucketWriter = sfWriters.get(lookupPath);
// 如果不存在,则构造一个缓存
if (bucketWriter == null) {
//通过HDFSWriterFactory根据filetype生成一个hdfswriter,由参数hdfs.Filetype控制;eg:HDFSDataStream
HDFSWriter hdfsWriter = writerFactory.getWriter(fileType);
//idleCallback会在bucketWriter flush完毕后从LRU中删除;
WriterCallback idleCallback = null;
if(idleTimeout != 0) {
idleCallback = new WriterCallback() {
@Override
public void run(String bucketPath) {
sfWriters.remove(bucketPath);
}
};
}
bucketWriter = new BucketWriter(rollInterval, rollSize, rollCount,
batchSize, context, realPath, realName, inUsePrefix, inUseSuffix,
suffix, codeC, compType,hdfsWriter, timedRollerPool,
proxyTicket, sinkCounter, idleTimeout, idleCallback,
lookupPath, callTimeout, callTimeoutPool);
sfWriters.put(lookupPath, bucketWriter);
}
......
// track一个事务内的bucket
if (!writers.contains(bucketWriter)) {
writers.add(bucketWriter);
}
// 写数据到HDFS;
bucketWriter.append(event);-------------apend()内部如下------------>
open();//如果底层支持append,则通过open接口打开;否则create接口
//判断是否进行日志切换
//根据复制的副本书和目标副本数做对比,如果不满足则doRotate=false
if(doRotate) {
close();
open();
}
//写数据,超时时间hdfs.callTimeout
callWithTimeout(new CallRunner<Void>() {
@Override
public Void call() throws Exception {
writer.append(event); // could block
return null;
}
});
if(batchCounter == batchSize) {//如果达到batchSize行进行一次flush
flush();---------->
doFlush()--------->
HDFSWriter.sync()----------->
FSDataoutputStream.flush/sync
}
// 提交事务之前,刷新所有的bucket
for(BucketWriter bucketWriter : writers){
bucketWriter.flush();
}
transaction.commit();BucketWriter
BucketWriter主要封装了hadoop hdfs api
Reference
http://boylook.blog.51cto.com/7934327/d-4
转载请注明:http://blog.csdn.net/wsscy2004