Android4.4深入浅出之SurfaceFlinger总体结构
Android4.4 GUI系统框架之SurfaceFlinger
一. Android GUI框架:

SurfaceFlinger:每当用户程序刷新UI的时候,会中介BufferQueue申请一个buffer(dequeueBuffer),然后把UI的信息填入,丢给SurfaceFlinger,SurfaceFlinger通过计算多重计算合成visibleRegion之后,丢给openGL层处理,处理之后送到显示器display上显示。
根据整个Android系统的GUI设计理念,我们不难猜想到至少需要两种本地窗口:
Ø 面向管理者(SurfaceFlinger)
既然SurfaceFlinger扮演了系统中所有UI界面的管理者,那么它无可厚非地需要直接或间接地持有“本地窗口”,这个窗口就是FramebufferNativeWindow
Ø 面向应用程序
这类窗口是Surface(这里和以前版本出入比较大,之前的版本本地窗口是SurfaceTextureClient)
第二种窗口是能直接显示在终端屏幕上的——它使用了帧缓冲区,而第一种Window实际上是从内存缓冲区分配的空间。当系统中存在多个应用程序时,这能保证它们都可以获得一个“本地窗口”,并且这些窗口最终也能显示到屏幕上——SurfaceFlinger会收集所有程序的显示需求,对它们做统一的图像混合操作。
二. SurfaceFlinger和BufferQueue
一个UI完全显示到diplay的过程,SurfaceFlinger扮演着重要的角色但是它的职责是“Flinger”,即把系统中所有应用程序的最终的“绘图结果”进行“混合”,然后统一显示到物理屏幕上,而其他方面比如各个程序的绘画过程,就由其他东西来担任了。这个光荣的任务自然而然地落在了BufferQueue的肩膀上,它是每个应用程序“一对一”的辅导老师,指导着UI程序的“画板申请”、“作画流程”等一系列细节。下面的图描述了这三者的关系:
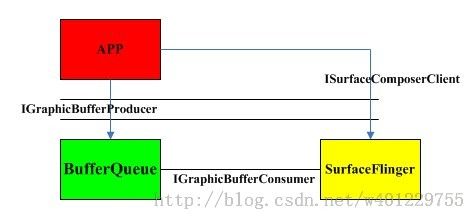
虽说是三者的关系,但是他们所属的层却只有两个,app属于java层,BufferQueue/SurfaceFlinger属于native层。也就是说BufferQueue也是隶属SurfaceFlinger,所有工作围绕SurfaceFlinger展开。
这里IGraphicBufferProducer就是app和BufferQueue重要桥梁,GraphicBufferProducer承担着单个应用进程中的UI显示需求,与BufferQueue打交道的就是它。它的工作流程如下:
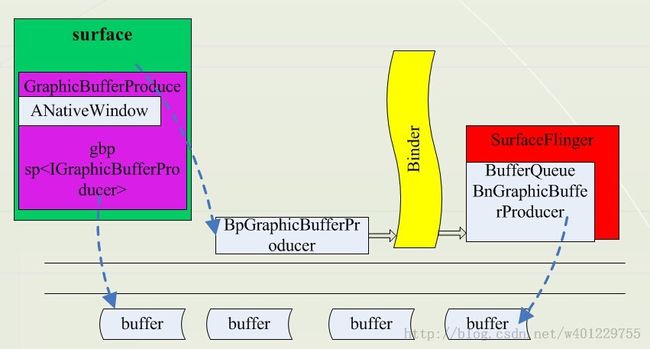
BpGraphicBufferProducer是GraphicBufferProducer在客户端这边的代理对象,负责和SF交互,GraphicBufferProducer通过gbp(IGraphicBufferProducer类对象)向BufferQueue获取buffer,然后进行填充UI信息,当填充完毕会通知SF,SF知道后就对该Buffer进行下一步操作。典型的生产-消费者模式。
接下来具体说明客户端(producer)和服务端SurfaceFlinger(consumer)工作的模式:
首先这里的buffer是共享缓冲区,故肯定会涉及到互斥锁,所以buffer的状态也会有多种,一般的buffer大致会经过FREE->DEQUEUED->QUEUED->ACQUIRED->FREE这个流程,如右图:

Ø BufferQueue
可以认为BufferQueue是一个服务中心,其它两个owner必须要通过它来管理buffer。比如说当producer想要获取一个buffer时,它不能越过BufferQueue直接与consumer进行联系,反之亦然。
Ø Producer
生产者就是“填充”buffer空间的人,通常情况下当然就是应用程序。因为应用程序不断地刷新UI,从而将产生的显示数据源源不断地写到buffer中。当Producer需要使用一块buffer时,它首先会向中介BufferQueue发起dequeue申请,然后才能对指定的缓冲区进行操作。这种情况下buffer就属于producer一个人的了,它可以对buffer进行任何必要的操作,而其它owner此刻绝不能擅自插手。
当生产者认为一块buffer已经写入完成后,它进一步调用BufferQueue的queue。从字面上看这个函数是“入列”的意思,形象地表达了buffer此时的操作——把buffer归还到BufferQueue的队列中。一旦queue成功后,owner也就随之改变为BufferQueue了
Ø Consumer
消费者是与生产者相对应的,它的操作同样受到BufferQueue的管控。当一块buffer已经就绪后,Consumer就可以开始工作了。这里需要特别留意的是,从各个对象所扮演的角色来看,BufferQueue是中介机构,属于服务提供方;Producer属于buffer内容的产出方,它对缓冲区的操作是一个“主动”的过程;反之,Consumer对buffer的处理则是“被动”的、“等待式”的——它必须要等到一块buffer填充完成后才能做工作。在这样的模型下,我们怎么保证Consumer可以及时的处理buffer呢?换句话说,当一块buffer数据ready后,应该怎么告知Consumer来操作呢?
仔细观察的话,可以看到BufferQueue里还同时提供了一个特别的类,名称为ProxyConsumerListener,其中的函数接口包括:
- classProxyConsumerListener : public BnConsumerListener {
- public:
- //省略构造函数
- virtual void onFrameAvailable();/*当一块buffer可以被消费时,这个函数会被调用,特别注意此时没有共享锁的保护*/
- virtual voidonBuffersReleased();/*BufferQueue通知consumer它已经释放其slot中的一个或多个 GraphicBuffer引用*/
- private:
- wp<ConsumerListener>mConsumerListener;
- }
这样子就很清楚了,当有一帧数据准备就绪后,BufferQueue就会调用onFrameAvailable()来通知Consumer进行消费。
BufferQueue和SurfaceFlinger之间的通信模式如下:

也是有一对BpGraphicBufferConsumer/BnGraphicBufferConsumer支持他们之间的信息传输。
三. 具体分析BufferQueue
首先说明一下BufferQueue的类关系:

下面是BufferQueue中的核心函数分析:
| 核心成员函数 |
说明 |
| setBufferCount |
setBufferCount updates the number of available buffer slots. |
| requestBuffer |
requestBuffer returns the GraphicBuffer for slot N. |
| dequeueBuffer |
dequeueBuffer gets the next buffer slot index for the producer to use. |
| queueBuffer |
queueBuffer returns a filled buffer to the BufferQueue. |
| cancelBuffer |
cancelBuffer returns a dequeued buffer to the BufferQueue |
| acquireBuffer |
acquireBuffer attempts to acquire ownership of the next pending buffer BufferQueue. |
| releaseBuffer |
releaseBuffer releases a buffer slot from the consumer back to the BufferQueue. |
BufferQueue是IGraphicBufferProducer和IGraphicBufferConsumer的具体实现,用户在请求和SurfaceFlinger连接的过程中会请求SF创建一个Layer,IGraphicBufferProducer就是在这个过程中获取一个BufferQueue对象,又转化成IGraphicBufferProducer类对象,是为了进一步和BufferQueue进行交互,下面是关键代码:
- status_t SurfaceFlinger::createNormalLayer(constsp<Client>& client,
- const String8& name, uint32_t w,uint32_t h, uint32_t flags, PixelFormat& format,
- sp<IBinder>* handle, sp<IGraphicBufferProducer>*gbpsp<Layer>* outLayer)
- {
- switch (format) {
- case PIXEL_FORMAT_TRANSPARENT:
- case PIXEL_FORMAT_TRANSLUCENT:
- format = PIXEL_FORMAT_RGBA_8888;
- break;
- case PIXEL_FORMAT_OPAQUE:
- }
- #ifdefNO_RGBX_8888
- if (format == PIXEL_FORMAT_RGBX_8888)
- format = PIXEL_FORMAT_RGBA_8888;
- #endif
- *outLayer = new Layer(this, client, name,w, h, flags);
- status_t err =(*outLayer)->setBuffers(w, h, format, flags);
- if (err == NO_ERROR) {
- *handle = (*outLayer)->getHandle();
- *gbp =(*outLayer)->getBufferQueue();
- }
- ALOGE_IF(err, "createNormalLayer()failed (%s)", strerror(-err));
- return err;
- }
下面是getBufferQueue的实现,很简单,获取BufferQueue对象:
- sp<IGraphicBufferProducer>Layer::getBufferQueue() const {
- return mBufferQueue;
- }
IGraphicBufferProducer是个接口类,它的实现必然在子类BpGraphicBufferProducer中实现,我们来看下这个类:
- classBpGraphicBufferProducer : public BpInterface<IGraphicBufferProducer>
- {
- public:
- BpGraphicBufferProducer(constsp<IBinder>& impl)
- :BpInterface<IGraphicBufferProducer>(impl)
- {
- }
- virtual status_t requestBuffer(intbufferIdx, sp<GraphicBuffer>* buf) {
- Parcel data, reply;
- data.writeInterfaceToken(IGraphicBufferProducer::getInterfaceDescriptor());
- data.writeInt32(bufferIdx);
- status_t result =remote()->transact(REQUEST_BUFFER, data,&reply);
- if (result != NO_ERROR) {
- return result;
- }
- bool nonNull = reply.readInt32();
- if (nonNull) {
- *buf = new GraphicBuffer();
- reply.read(**buf);
- }
- result = reply.readInt32();
- return result;
- }
- virtual status_t dequeueBuffer(int*buf, sp<Fence>* fence, bool async,
- uint32_t w, uint32_t h, uint32_tformat, uint32_t usage) {
- Parcel data, reply;
- data.writeInterfaceToken(IGraphicBufferProducer::getInterfaceDescriptor());
- data.writeInt32(async);
- data.writeInt32(w);
- data.writeInt32(h);
- data.writeInt32(format);
- data.writeInt32(usage);
- status_t result = remote()->transact(DEQUEUE_BUFFER, data,&reply);
- if (result != NO_ERROR) {
- return result;
- }
- *buf = reply.readInt32();
- bool nonNull = reply.readInt32();
- if (nonNull) {
- *fence = new Fence();
- reply.read(**fence);
- }
- result = reply.readInt32();
- return result;
- }
- virtual status_t queueBuffer(intbuf,
- const QueueBufferInput& input,QueueBufferOutput* output) {
- Parcel data, reply;
- data.writeInterfaceToken(IGraphicBufferProducer::getInterfaceDescriptor());
- data.writeInt32(buf);
- data.write(input);
- status_t result = remote()->transactQUEUE_BUFFER, data, &reply);
- if (result != NO_ERROR) {
- return result;
- }
- memcpy(output,reply.readInplace(sizeof(*output)), sizeof(*output));
- result = reply.readInt32();
- return result;
省去了一些成员函数,只贴出关键成员函数,首先这里的dequeueBuffer和queueBuffer并非真正对Buffer进行操作,留意红色部分,会发现他只是发出一个“消息”通知接收方要去
Dequeue一个Buffer或queue一个Buffer。相对应的BnGraphicBufferProducer来接收消息。
BnGraphicBufferProducer中的onTransact负责这件事:
- status_tBnGraphicBufferProducer::onTransact(
- uint32_t code, const Parcel& data,Parcel* reply, uint32_t flags)
- {
- switch(code) {
- case DEQUEUE_BUFFER: {
- CHECK_INTERFACE(IGraphicBufferProducer, data, reply);
- bool async = data.readInt32();
- uint32_t w = data.readInt32();
- uint32_t h =data.readInt32();
- uint32_t format = data.readInt32();
- uint32_t usage = data.readInt32();
- int buf;
- sp<Fence> fence;
- int result = dequeueBuffer(&buf, &fence, async, w, h,format, usage);
- reply->writeInt32(buf);
- reply->writeInt32(fence !=NULL);
- if (fence != NULL) {
- reply->write(*fence);
- }
- reply->writeInt32(result);
- return NO_ERROR;
- } break;
- case QUEUE_BUFFER: {
- CHECK_INTERFACE(IGraphicBufferProducer, data, reply);
- int buf = data.readInt32();
- QueueBufferInput input(data);
- QueueBufferOutput* const output =
- reinterpret_cast<QueueBufferOutput*>(
- reply->writeInplace(sizeof(QueueBufferOutput)));
- status_t result = queueBuffer(buf, input, output);
- reply->writeInt32(result);
- return NO_ERROR;
- } break;
- }
- return BBinder::onTransact(code, data,reply, flags);
- }
省略了一些分支,留意红色部分才发现这里调用了dequeueBuffer和queueBuffer,
它们的实现在BufferQueue中,这里才真正踏足到BufferQueue领域中。到这里客户端和BufferQueue建立联系,接下去的事就是BufferQueue内部处理的事了,BufferQueue和SuefaceFlinger之间的关系也如此。
四. SurfaceFlinger处理buffer
这里先用2张图来介绍下SurfaceFlinger的整个消息处理机制和工作流程:
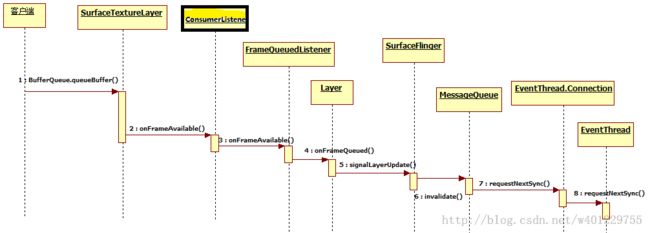
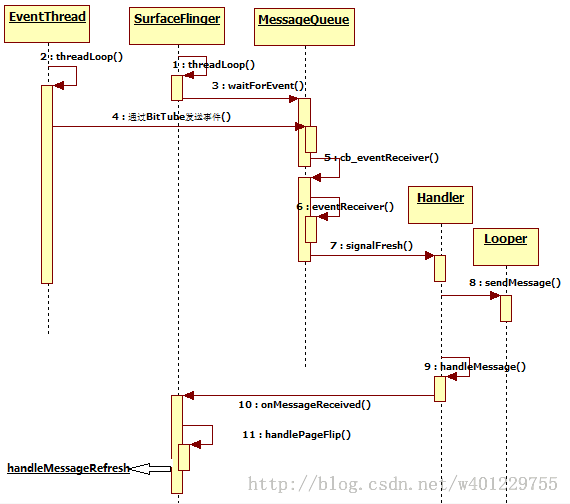
更具体的代码流程之前有经过分析。
这里继续下去对handleMessageRefresh分析,这是SuefaceFlinger的核心处理函数。
- voidSurfaceFlinger::handleMessageRefresh() {
- ATRACE_CALL();
- preComposition();
- rebuildLayerStacks();
- setUpHWComposer();
- doDebugFlashRegions();
- doComposition();
- postComposition();
- //………省略
- }
preComposition();预先准备“合成物“就是客户端那边传来的UI信息的buffer;
rebuildLayerStacks();在每一个screen上重建可见区域;
setUpHWComposer();初始化一个硬件容器;
doDebugFlashRegions();这个函数一般进去就返回来了;
doComposition();实质的合成过程,并且合成完的BUFFER由opengl es处理,处理之后由postFramebuffer()送到display上显示;
这里重点研究doComposition()
- voidSurfaceFlinger::doComposition() {
- ATRACE_CALL();
- const bool repaintEverything =android_atomic_and(0, &mRepaintEverything);
- for (size_t dpy=0 ; dpy<mDisplays.size(); dpy++) {
- const sp<DisplayDevice>&hw(mDisplays[dpy]);
- if (hw->canDraw()) {
- // transform the dirty region intothis screen's coordinate space
- const Region dirtyRegion(hw->getDirtyRegion(repaintEverything));
- // repaint the framebuffer (ifneeded)
- doDisplayComposition(hw, dirtyRegion);
- hw->dirtyRegion.clear();
- hw->flip(hw->swapRegion);
- hw->swapRegion.clear();
- }
- // inform the h/w that we're donecompositing
- hw->compositionComplete();
- }
- postFramebuffer();
- }
doDisplayComposition(hw, dirtyRegion);负责渲染的核心函数它的走向是:
doDisplayComposition-> doComposeSurfaces->draw->onDraw->drawWithOpenGL.一直走到OPENGL层。Opengl贴完图之后,调用了flip函数,在这里跟之前版本有很大出入,之前版本flip是在postFramebuffer中的,而且函数内容也做了很大的改变,只是计数加一。
在这里说明一下,UI显示是双缓冲机制,每当画完一个buffer需要flip一下,也就是交换。但在这个版本已经融合到postFramebuffer中:
贴出关键代码
r = hwc.commit();
成员变量hwc是在DisplayHardware::init中生成的一个HWComposer对象。只要HWC_HARDWARE_MODULE_ID模块可以正常加载,且hwc_open能打开hwc_composer_device设备,那么initCheck()就返回NO_ERROR,否则就是NO_INIT。
此时我们通过HWComposer::commit来执行flip,这个函数直接调用如下硬件接口:
mHwc->set(mHwc, mNumDisplays, mLists);
set()和后面的eglSwapBuffers是基本等价的,原型如下:
int (*set)(struct hwc_composer_device*dev,hwc_display_t dpy,
hwc_layer_list_t* list);
其中最后一个list必须与最近一次的prepare()所用列表完全一致。假如list为空或者列表数量为0的话,说明SurfaceFlinger已经利用OpenGL ES做了composition,此时set就和eglSwapBuffers一样。当list不为空,且layer的compositionType == HWC_OVERLAY,那么HWComposer需要进行硬件合成。
如果成功执行的话,set返回0,否则就是HWC_EGL_ERROR。
如果没成功的话,后面还有一句:
if (r)
{
hw->hwcSwapBuffers();
}
作用也是跟flip一样。它的函数走向是:
hwcSwapBuffers->eglSwapBuffers->swapBuffers->advanceFrame-> fbPost->post。
一旦交换完毕就顺着这个走向抛给底层display去显示。
这里我们主要研究swapBuffers这个函数:
- EGLBooleanegl_window_surface_v2_t::swapBuffers()
- {
- //………….
- nativeWindow->queueBuffer(nativeWindow,buffer, -1);
- // dequeue a new buffer
- if (nativeWindow->dequeueBuffer(nativeWindow, &buffer, &fenceFd)== NO_ERROR) {
- sp<Fence> fence(new Fence(fenceFd));
- if(fence->wait(Fence::TIMEOUT_NEVER)) {
- nativeWindow->cancelBuffer(nativeWindow, buffer, fenceFd);
- return setError(EGL_BAD_ALLOC,EGL_FALSE);
- }
- //。。。。。。
- }
这和我一开始的那张图的流程是一致的——通过queueBuffer来入队,然后通过dequeueBuffer重新申请一个buffer以用于下一轮的刷新。
Android4.4深入浅出之SurfaceFlinger框架-渲染一个surface(二)
SurfaceFlinger自启动之后,主要有三种类型线程参与工作:
1.binder线程,负责监控binder设备完成与客户端的交接
2.控制台事件监控线程,负责监控硬件帧缓冲区的睡眠/唤醒状态切换事件。
3.UI渲染线程,负责渲染UI。
一 UI渲染线程
UI渲染线程平时是处于休眠状态,一旦binder线程监测到有其他进程发过来的请求渲染UI的消息就会唤醒UI渲染线程,另一方面一旦SurfaceFlinger服务的控制台事件监控线程发现硬件帧缓冲区即将要进入睡眠或者唤醒状态时,它就会往SurfaceFlinger服务的UI渲染线程的消息队列中发送一个消息,以便SurfaceFlinger服务的UI渲染线程可以执行冻结或者解冻显示屏的操作。(摘自老罗的android之旅)接下来我从客户端一个请求渲染UI的请求入手开始研究渲染UI的整个过程
UI渲染线程的运行过程:
这里在说明一下,SurfaceFlinger的各个代理负责的事情:前面讲述的BpSurfaceComposer是SF在客户端的Binder代理,BnSurfaceComposer是本地对象负责和BpXXX交互,他们主要负责客户端请求连的整个过程和监控binder设备。而客户端与server端真正的交易则交给BpSurfaceComposerClient和BnSurfaceComposerClient来做,他们负责通知管理一个UI的渲染等重要过程。那我就从BpSurfaceComposerClient代理入手,还记得这个BpSurfaceComposerClient是哪里诞生的吗?在之前客户端请求连接到server的时候:
- void SurfaceComposerClient::onFirstRef() {
- sp<ISurfaceComposer> sm(ComposerService::getComposerService());
- if (sm != 0) {
- sp<ISurfaceComposerClient> conn = sm->createConnection();
- if (conn != 0) {
- mClient = conn;
- mStatus = NO_ERROR;
- }
- }
- }
当中的一句 mClient = conn;即把返回来的surfacecomposerclient保存了下来,又因为mClient是强指针,导致最终其实mClient就是BpSurfaceComposerClient类的对象,具体原因之前在研究SF启动过程中有详细说明。从连接之后,就获得了一个BpSurfaceComposerClient对象,这样连接后就可以进行下一步的渲染工作了。我们再看下BpSurfaceComposerClient这个类:
- class BpSurfaceComposerClient : public BpInterface<ISurfaceComposerClient>
- {
- public:
- BpSurfaceComposerClient(const sp<IBinder>& impl)
- : BpInterface<ISurfaceComposerClient>(impl) {
- }
- virtual status_t createSurface(const String8& name, uint32_t w,
- uint32_t h, PixelFormat format, uint32_t flags,
- sp<IBinder>* handle,
- sp<IGraphicBufferProducer>* gbp) {
- Parcel data, reply;
- data.writeInterfaceToken(ISurfaceComposerClient::getInterfaceDescriptor());
- data.writeString8(name);
- data.writeInt32(w);
- data.writeInt32(h);
- data.writeInt32(format);
- data.writeInt32(flags);
- remote()->transact(CREATE_SURFACE, data, &reply);
- *handle = reply.readStrongBinder();
- *gbp = interface_cast<IGraphicBufferProducer>(reply.readStrongBinder());
- return reply.readInt32();
- }
- virtual status_t destroySurface(const sp<IBinder>& handle) {
- Parcel data, reply;
- data.writeInterfaceToken(ISurfaceComposerClient::getInterfaceDescriptor());
- data.writeStrongBinder(handle);
- remote()->transact(DESTROY_SURFACE, data, &reply);
- return reply.readInt32();
- }
- };
他有两个成员函数,分别是createSurface和destroySurface对应创建和销毁一个surface。两个核心函数的核心语句都在remote()->transact(CREATE_SURFACE, data, &reply);
即transact这个函数,之前也介绍过这是和binder设备打交道的必经之路。不做过多深入,这里意思就是简单的发个消息 CREATE_SURFACE给服务端,并把一个surface的信息打包成data一并发送过去。
server端这边会有线程监控binder设备,一旦收到消息自然调用对应的函数。这里就是BnSurfaceComposerClient负责了,不过这边跟之前的BnSurfaceComposer有点不一样,BnSurfaceComposerClient派生出一个Client类来负责这件事了,我们来看下这个类:
- class Client : public BnSurfaceComposerClient
- {
- public:
- Client(const sp<SurfaceFlinger>& flinger);
- ~Client();
- status_t initCheck() const;
- // protected by SurfaceFlinger::mStateLock
- void attachLayer(const sp<IBinder>& handle, const sp<Layer>& layer);
- void detachLayer(const Layer* layer);
- sp<Layer> getLayerUser(const sp<IBinder>& handle) const;
- private:
- // ISurfaceComposerClient interface
- virtual status_t createSurface(
- const String8& name,
- uint32_t w, uint32_t h,PixelFormat format, uint32_t flags,
- sp<IBinder>* handle,
- sp<IGraphicBufferProducer>* gbp);
- virtual status_t destroySurface(const sp<IBinder>& handle);
- virtual status_t onTransact(
- uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags);
- // constant
- sp<SurfaceFlinger> mFlinger;
- // protected by mLock
- DefaultKeyedVector< wp<IBinder>, wp<Layer> > mLayers;
- // thread-safe
- mutable Mutex mLock;
- };
其实核心的成员函数就两个 一个是createSurface和onTransact。首先看onTransact,毕竟他负责接收消息。
- status_t Client::onTransact(
- uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
- {
- // these must be checked
- IPCThreadState* ipc = IPCThreadState::self();
- const int pid = ipc->getCallingPid();
- const int uid = ipc->getCallingUid();
- const int self_pid = getpid();
- if (CC_UNLIKELY(pid != self_pid && uid != AID_GRAPHICS && uid != 0)) {
- // we're called from a different process, do the real check
- if (!PermissionCache::checkCallingPermission(sAccessSurfaceFlinger))
- {
- ALOGE("Permission Denial: "
- "can't openGlobalTransaction pid=%d, uid=%d", pid, uid);
- return PERMISSION_DENIED;
- }
- }
- return BnSurfaceComposerClient::onTransact(code, data, reply, flags);
- }
这里前面的语句为了判断是否得到进入使用SF的权限,看他的返回 BnSurfaceComposerClient::onTransact(code, data, reply, flags);直接调用了另外一个onTransact接着看BnSurfaceComposerClient类中的onTransact
- status_t BnSurfaceComposerClient::onTransact(
- uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
- {
- switch(code) {
- case CREATE_SURFACE: {
- CHECK_INTERFACE(ISurfaceComposerClient, data, reply);
- String8 name = data.readString8();
- uint32_t w = data.readInt32();
- uint32_t h = data.readInt32();
- PixelFormat format = data.readInt32();
- uint32_t flags = data.readInt32();
- sp<IBinder> handle;
- sp<IGraphicBufferProducer> gbp;
- status_t result = createSurface(name, w, h, format, flags,
- &handle, &gbp);
- reply->writeStrongBinder(handle);
- reply->writeStrongBinder(gbp->asBinder());
- reply->writeInt32(result);
- return NO_ERROR;
- } break;
- case DESTROY_SURFACE: {
- CHECK_INTERFACE(ISurfaceComposerClient, data, reply);
- reply->writeInt32( destroySurface( data.readStrongBinder() ) );
- return NO_ERROR;
- } break;
- default:
- return BBinder::onTransact(code, data, reply, flags);
- }
- }
这才是处理的核心中间人,还记得刚刚传的消息是CREATE_SURFACE,所以这里走第一个分支,首先解析数据包得到一些数据例如surface名字,长宽,还有格式等。然后在经过createSurface创建,但是到这里有个问题,这里的createSurface没有指明属于哪个类,发现去追踪起定义这追踪不到,这才想起这是调用了他子类Client的函数。我们回到之前client类中的createSurface;
- status_t Client::createSurface(
- const String8& name,
- uint32_t w, uint32_t h, PixelFormat format, uint32_t flags,
- sp<IBinder>* handle,
- sp<IGraphicBufferProducer>* gbp)
- {
- /*
- * createSurface must be called from the GL thread so that it can
- * have access to the GL context.
- */
- class MessageCreateLayer : public MessageBase {
- SurfaceFlinger* flinger;
- Client* client;
- sp<IBinder>* handle;
- sp<IGraphicBufferProducer>* gbp;
- status_t result;
- const String8& name;
- uint32_t w, h;
- PixelFormat format;
- uint32_t flags;
- public:
- MessageCreateLayer(SurfaceFlinger* flinger,
- const String8& name, Client* client,
- uint32_t w, uint32_t h, PixelFormat format, uint32_t flags,
- sp<IBinder>* handle,
- sp<IGraphicBufferProducer>* gbp)
- : flinger(flinger), client(client),
- handle(handle), gbp(gbp),
- name(name), w(w), h(h), format(format), flags(flags) {
- }
- status_t getResult() const { return result; }
- virtual bool handler() {
- result = flinger->createLayer(name, client, w, h, format, flags,
- handle, gbp);
- return true;
- }
- };
- sp<MessageBase> msg = new MessageCreateLayer(mFlinger.get(),
- name, this, w, h, format, flags, handle, gbp);
- mFlinger->postMessageSync(msg);
- return static_cast<MessageCreateLayer*>( msg.get() )->getResult();
- }
这个函数才真正的是程序进入SF领域的分水岭,函数内部定义了一个MessageCreateLayer类,我的理解是这个类把一个surface封装成了一个消息,这个消息当中含有surface的所有信息。sp<MessageBase> msg = new MessageCreateLayer(mFlinger.get(), name, this, w, h, format, flags, handle, gbp);定义了一个消息封装了surface,mFlinger->postMessageSync(msg);这个向SF发出一个异步信号,这个信号会唤醒SF处于休眠状态的UI渲染线程核心处理部分。
我们看下这个函数:
- status_t SurfaceFlinger::postMessageSync(const sp<MessageBase>& msg,
- nsecs_t reltime, uint32_t flags) {
- status_t res = mEventQueue.postMessage(msg, reltime);
- if (res == NO_ERROR) {
- msg->wait();
- }
- return res;
- }
调用postMessage()
- status_t MessageQueue::postMessage(
- const sp<MessageBase>& messageHandler, nsecs_t relTime)
- {
- const Message dummyMessage;
- if (relTime > 0) {
- mLooper->sendMessageDelayed(relTime, messageHandler, dummyMessage);
- } else {
- mLooper->sendMessage(messageHandler, dummyMessage);
- }
- return NO_ERROR;
- }
这边 无论是sendMessageDelayed还是sendMessage都将会触发线程,将主线程(渲染UI)唤醒。那么我用一张图来介绍下主线程:
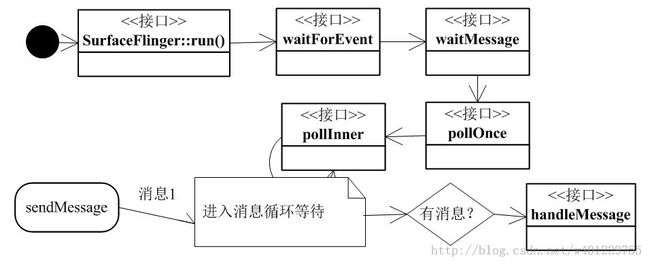
图画的很粗糙不过大致走向就是这样,当主线程收到消息后,就执行handleMessage。到这里可以去参考之前钱几篇SF流程系列文章看接下去是怎么渲染的。