Learning Multi-Domain Convolutional Neural Networks for Visual Tracking 笔记
这篇paper利用DL做 visual tracking,目前在Object Tracking Benchmark以及VOT2014上实现了state of the art。文章的方法比较直观:
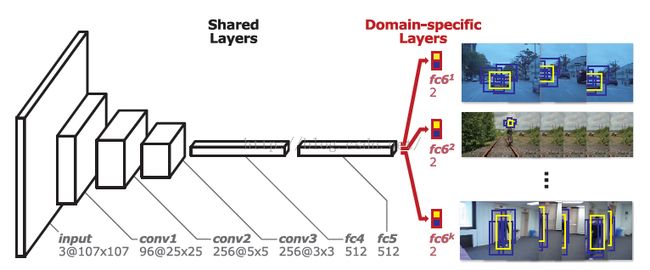
作者称之为Multi_domain network,实际上有些包装的嫌疑。本质上,作者首先拿第一帧大量的正负样本来训练前面这个conv1-conv2-conv3-fc4-fc5网络,而对于fc6,针对不同的输入图像序列(比如OTB中的basketball, Bolt)就单独训练这个fc6。 上图中的k对应的就是domain的个数,也就是OTB中不同类别的个数。注意的是,OTB中不同视频的个数可不等于类别的个数,因为有些视频是属于同一类的,比如car4,cardark,carscale. 于是作者干脆将这些看做是一个domain,训练的时候fc6层是一样的,这就是所谓domain的来源,好水。
然后我们具体讲讲作者怎么做的:
首先作者需要在拿数据集所有的图像序列的第一帧图像,从中获取大量的正负样本,那这些样本来训练上面那个网路,这是一个迭代过程,因为需要选出一些“好”的负样本:
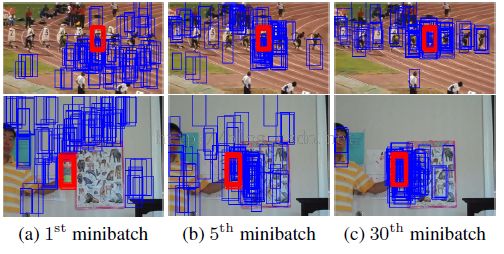
这个选择的方法叫做hard negtive minding,直观的结果就是尽量选择正样本附近的mini-batch,这些batch 被resized成107*107大小,输入到网路中,一直迭代知道网路收敛。注意的是每一个domain单独对应一个fc6层,而前面的层是共同训练的。从而出现所谓的multi-domain network.
第二步就是利用训练好的model做tracking。由于这个网络本身不是很复杂,所以在tracking的过程中,作者对网络也进行了更新,而不是像一般的网络那样只是更新分类器。同时,作者针对不同的情形,采用不同的更新策略:long term updating and short term updating. 当目标被分类成背景就立马更新这个model。同时可能存在从某一帧预测位置获取的正样本与真实的ground_truthc差别很大的情况,也就是说这些正样本没有一个能够很好的match真实的ground_truth,为了解决这个问题,作者将object detection中的bounding box regression技术融合进来了,从而尽量找出好的正样本出来。
第三步预测。
作者对每一帧预测256个candidates,具有不同的位置和尺度。然后从中找出最好的,最为该帧中目标的位置。
第四实验
第一个实验在OTB上做的,有100个视频,作者还把VOT2013,2014以及2015视频拿来训练,反正DL需要大量数据训练。在OTB50以及OTB100上的结果如下:
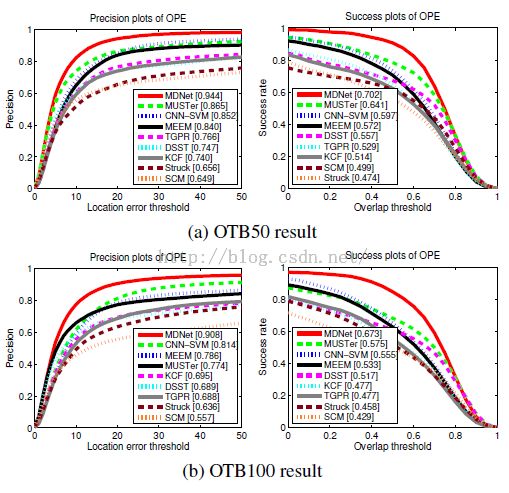
的确是很高!