性能问题的查找
1、发现问题
1)、使用w命令查看CPU的Load情况, Load越高说明问题越严重;
2)、 使用jstat查看FGC发生的频率及FGC所花费的时间, FGC发生的频率越快、花费的时间越高,问题越严重;
2、导出数据:在应用快要发生FGC的时候把堆导出来
1)、查看快要发生FGC使用命令:
jmap -heap <pid>
会看到如下图结果:
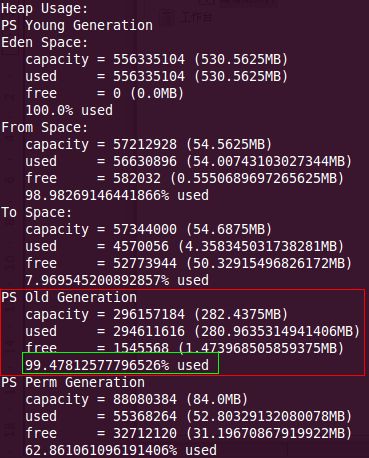
以上截图包括了新生代、老年代及持久代的当前使用情况, 如果不停的重复上面的命令,会看到这些数字的变化, 变化越大说明系统存在问题的可能性越大, 特别是被红色圈起来的老年代的变化情况。 现在看到的这个值为使用率为99%或才快接近的时候, 就立即可以执行导出堆栈的操作了。
注:这是因为我这里没有在jvm参数中使用"-server" 参数,也没有指定FGC的阀值, 在线上的应用中通过会指定CMSInitiatingOccup ancyFraction这个参数来指定当老年代使用了百分之多 少的时候,通过CMS进行FGC, 当然这个参数需要和这些参数一起使用“-XX:+ UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+ UseCMSCompactAtFullCollection -XX:+ UseCMSInitiatingOccupancyOnly” , CMSInitiatingOccupancyFraction 的默认值是68,现在中文站线上的应用都是70, 也就是说当老年代使用率真达到或者超过70%时, 就会进行FGC。
2)、将数据导出:
jmap -dump:format=b,file=heap.bin <pid>
这个时候会在当前目录以生成一个heap. bin这个二进制文件。
3、通过命令查看大对象
也是使用jmap的命令,只不过参数使用-histo
使用:jmap -histo <pid>|less
可得到如下包含对象序号、某个对象示例数、当前对象所占内存的大小、当前对象的全限定名,如下图:
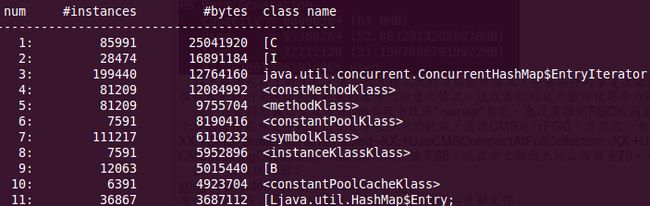
执行:jmap -histo <pid>|grep alibaba|sort -k 2 -g -r|less
结果如图:
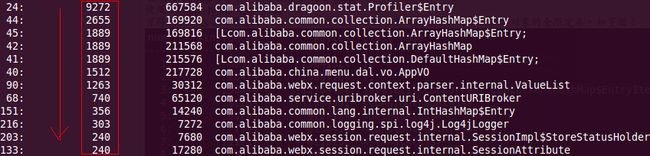
查看占用内存最多的最象,并按降序排序输出:
执行:
jmap -histo <pid>|grep alibaba|sort -k 3 -g -r|less
结果如图:

4、数据分析
这个时候将dump出的文件在ECLIPSE中打开, 使用MAT进行分析(ECLIPSE需要先安装MAT插件), 会展示如下截图:
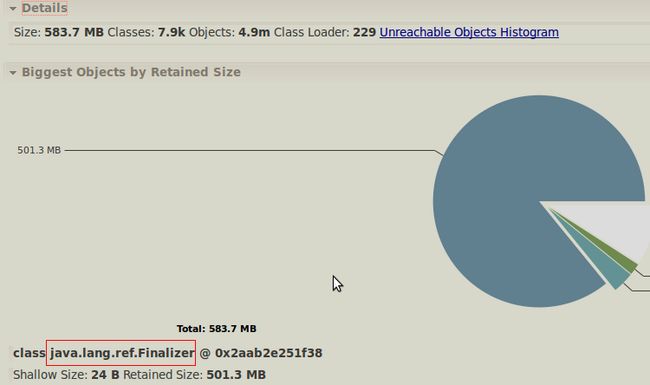
可以从这个图看出这个类java.lang.ref.
Finalizer占用500多M,
表示这其中很多不能够被回对象的对象,
此时点开hisgogram视图,并通过Retained Heap进行排序,如下截图:

从图中可以看出,被线线框圈起来的三个对象占用量非常大, 那说明这几个大的对象并没有被释放, 那现在就可以有针对性的从代码中去找这几个对象为什么没有被释放 了。
再切换到dominator_tree视图:

这里可以看到velocity渲染也存在着问题,以及数据库的请求也比较多。
5、优化
优化的思路就是上面所列出来的问题,查看实现代码中所存在问题,具体问题具体分析。
本文出自:冯立彬的博客