Deciding the Number of Clusterings(学习Free Mind知识整理)
阅读http://freemind.pluskid.org/machine-learning/deciding-the-number-of-clusterings/文章的一些知识整理。
=====================================================================
前面不知道kid在后面会介绍如何确定聚类的类别个数这一部分知识,我在前面也提到了这点,我们再看下这篇里面的解释吧。
=====================================================================
文章前面说明了一个问题"原来的选择 的问题转化成了选择树深度的问题"。
先看一下mean sift,(http://www.cnblogs.com/liqizhou/archive/2012/05/12/2497220.html)
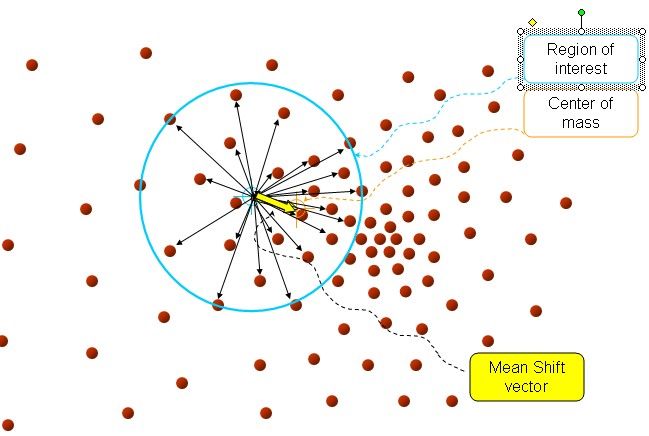
在d维空间中,任选一个点,然后以这个点为圆心,h为半径做一个高维球,因为有d维,d可能大于2,所以是高维球。落在这个球内的所有点和圆心都会产生一个向量,向量是以圆心为起点落在球内的点位终点。然后把这些向量都相加。相加的结果就是Meanshift向量。也就是黄色箭头。
再以meanshift向量的终点为圆心,再做一个高维的球。如下图所以,重复以上步骤,就可得到一个meanshift向量。如此重复下去,meanshift算法可以收敛到概率密度最大得地方。也就是最稠密的地方。
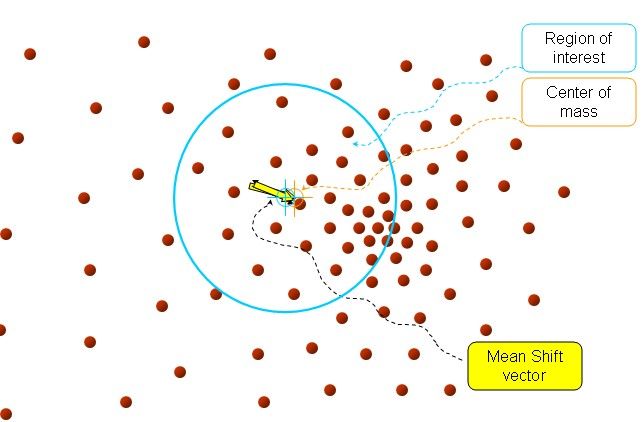
最终的结果如下:

推导见上面这篇文章,这里就不啰嗦的复制粘贴了。这样原来选择 的问题现在被转化为了选择圆圈的大小的问题。
====================================================================
这里推荐一本机器学习方面的好书,名字是《Pattern Recognition and Machine Learning》,作者是Christopher M.Bishop,据说是机器学习方面的经典著作。我导师也推荐看一下,一直没看,后面补一下PRML。
关于Dirichlet Process这个过程先看下这位网友的通俗解释,http://blog.csdn.net/xianlingmao/article/details/7342837 其中The Dirichlet Distribution 狄利克雷分布 (PRML 2.2.1)[http://www.xperseverance.net/blogs/2012/03/510/]
=====================================================================
近邻传播聚类Affinity Propagation,(http://www.kylen314.com/archives/425)。
=====================================================================
里面有个slides可以看看。
=====================================================================
最后“对于层次聚类,给出一个Q函数,Q函数最大处即是合适的最深度,由此也不需要任何预设参数即可确定最终的聚类。”作者是这个意思。
=====================================================================