数据库索引分析及其优化
最近一直在关注数据库,估计至少需要3个月的时间入门吧,不急。
一边看《MySQL必知必会》,一边看公司的资料。有问题的话,直接google。正确每天都有更新和收获。
本文转自
http://www.cxybl.com/html/wlbc/db/MYSQL/2011_1014_5587.html
什么是索引?
索引用来快速地寻找那些具有特定值的记录,所有MySQL索引都以B-树的形式保存。如果没有索引,执行查询时MySQL必须从第一个记录开始扫描整个表的所有记录,直至找到符合要求的记录。表里面的记录数量越多,这个操作的代价就越高。如果作为搜索条件的列上已经创建了索引,MySQL无需扫描任何记录即可迅速得到目标记录所在的位置。如果表有1000个记录,通过索引查找记录至少要比顺序扫描记录快100倍。
假设我们创建了一个名为people的表
CREATE TABLE people ( peopleid SMALLINT NOT NULL, name CHAR(50) NOT NULL );然后,我们完全随机把1000个不同name值插入到people表。下图显示了people表所在数据文件的一小部分:


对于索引中的每一项,MySQL在内部为它保存一个数据文件中实际记录所在位置的“指针”。因此,如果我们要查找name等于“Mike”记录的peopleid,SQL命令为
SELECT peopleid FROM people WHERE name='Mike'
MySQL能够在name的索引中查找“Mike”值,然后直接转到数据文件中相应的行,准确地返回该行的peopleid(999)。在这个过程中,MySQL只需处理一个行就可以返回结果。如果没有“name”列的索引,MySQL要扫描数据文件中的所有记录,即1000个记录!显然,需要MySQL处理的记录数量越少,则它完成任务的速度就越快。
索引的类型
MySQL提供多种索引类型供选择:
普通索引
这是最基本的索引类型,而且它没有唯一性之类的限制。普通索引可以通过以下几种方式创建:
CREATE INDEX <索引的名字> ON tablename (列的列表);
ALTER TABLE tablename ADD INDEX [索引的名字] (列的列表)
CREATE TABLE tablename ( [...], INDEX [索引的名字] (列的列表) )
唯一性索引
这种索引和前面的“普通索引”基本相同,但有一个区别:索引列的所有值都只能出现一次,即必须唯一。唯一性索引可以用以下几种方式创建:
CREATE UNIQUE INDEX <索引的名字> ON tablename (列的列表)
ALTER TABLE tablename ADD UNIQUE [索引的名字] (列的列表)
CREATE TABLE tablename ( [...], UNIQUE [索引的名字] (列的列表)
主键
主键是一种唯一性索引,但它必须指定为“PRIMARY KEY”。如果你曾经用过AUTO_INCREMENT类型的列,你可能已经熟悉主键之类的概念了。主键一般在创建表的时候指定,例如“CREATE TABLE tablename ( [...], PRIMARY KEY (列的列表) ); ”。但是,我们也可以通过修改表的方式加入主键,例如“ALTER TABLE tablename ADD PRIMARY KEY (列的列表); ”。每个表只能有一个主键。
全文索引
MySQL从3.23.23版开始支持全文索引和全文检索。在MySQL中,全文索引的索引类型为FULLTEXT。全文索引可以在VARCHAR或者TEXT类型的列上创建。它可以通过CREATE TABLE命令创建,也可以通过ALTER TABLE或CREATE INDEX命令创建。对于大规模的数据集,通过ALTER TABLE(或者CREATE INDEX)命令创建全文索引要比把记录插入带有全文索引的空表更快。本文下面的讨论不再涉及全文索引,要了解更多信息,请参见MySQL documentation。
单列索引与多列索引
索引可以是单列索引,也可以是多列索引。下面我们通过具体的例子来说明这两种索引的区别。假设有这样一个people表:
CREATE TABLE people (
peopleid SMALLINT NOT NULL AUTO_INCREMENT,
firstname CHAR(50) NOT NULL,
lastname CHAR(50) NOT NULL,
age SMALLINT NOT NULL,
townid SMALLINT NOT NULL,
PRIMARY KEY (peopleid) );下面是我们插入到这个people表的数据:
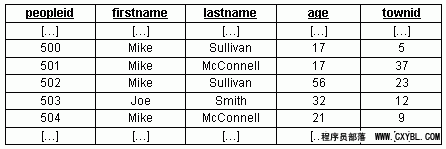
个数据片段中有四个名字为“Mikes”的人(其中两个姓Sullivans,两个姓McConnells),有两个年龄为17岁的人,还有一个名字与众不同的Joe Smith.这个表的主要用途是根据指定的用户姓、名以及年龄返回相应的peopleid。例如,我们可能需要查找姓名为Mike Sullivan、年龄17岁用户的peopleid。
SQL命令为
SELECT peopleid FROM people WHERE firstname='Mike' AND lastname='Sullivan' AND age=17
由于我们不想让MySQL每次执行查询就去扫描整个表,这里需要考虑运用索引。
首先,我们可以考虑在单个列上创建索引,比如firstname、lastname或者age列。如果我们创建firstname列的索引,
ALTER TABLE people ADD INDEX firstname (firstname);
MySQL将通过这个索引迅速把搜索范围限制到那些firstname='Mike'的记录,然后再在这个“中间结果集”上进行其他条件的搜索:它首先排除那些lastname不等于“Sullivan”的记录,然后排除那些age不等于17的记录。当记录满足所有搜索条件之后,MySQL就返回最终的搜索结果。
由于建立了firstname列的索引,与执行表的完全扫描相比,MySQL的效率提高了很多,但我们要求MySQL扫描的记录数量仍旧远远超过了实际所需要的。虽然我们可以删除firstname列上的索引,再创建lastname或者age列的索引,但总地看来,不论在哪个列上创建索引搜索效率仍旧相似。
为了提高搜索效率,我们需要考虑运用多列索引。如果为firstname、lastname和age这三个列创建一个多列索引,MySQL只需一次检索就能够找出正确的结果!下面是创建这个多列索引的SQL命令
ALTER TABLE people ADD INDEX fname_lname_age (firstname,lastname,age);
由于索引文件以B-树格式保存,MySQL能够立即转到合适的firstname,然后再转到合适的lastname,最后转到合适的age。在没有扫描数据文件任何一个记录的情况下,MySQL就正确地找出了搜索的目标记录!
那么,如果在firstname、lastname、age这三个列上分别创建单列索引,效果是否和创建一个firstname、lastname、age的多列索引一样呢?答案是否定的,两者完全不同。当我们执行查询的时候,MySQL只能使用一个索引。如果你有三个单列的索引,MySQL会试图选择一个限制最严格的索引。但是,即使是限制最严格的单列索引,它的限制能力也肯定远远低于firstname、lastname、age这三个列上的多列索引。
最左前缀
多列索引还有另外一个优点,它通过称为最左前缀(Leftmost Prefixing)的概念体现出来。继续考虑前面的例子,现在我们有一个firstname、lastname、age列上的多列索引,我们称这个索引为fname_lname_age。当搜索条件是以下各种列的组合时,MySQL将使用fname_lname_age索引:
firstname,lastname,age
firstname,lastname
firstname
从另一方面理解,它相当于我们创建了(firstname,lastname,age)、(firstname,lastname)以及(firstname)这些列组合上的索引。下面这些查询都能够使用这个fname_lname_age索引:
SELECT peopleid FROM people WHERE firstname='Mike' AND lastname='Sullivan' AND age='17';
SELECT peopleid FROM people WHERE firstname='Mike' AND lastname='Sullivan';
SELECT peopleid FROM people WHERE firstname='Mike';另外,注意的是下面sql语句并不会使用索引
SELECT peopleid FROM people WHERE lastname='Sullivan';
SELECT peopleid FROM people WHERE age='17';
SELECT peopleid FROM people WHERE lastname='Sullivan' AND age='17';
选择索引列
在性能优化过程中,选择在哪些列上创建索引是最重要的步骤之一。可以考虑使用索引的主要有两种类型的列:在WHERE子句中出现的列,在join子句中出现的列。请看下面这个查询:
SELECT age ## 不使用索引 FROM people WHERE firstname='Mike' ## 考虑使用索引 AND
lastname='Sullivan' ## 考虑使用索引
这个查询与前面的查询略有不同,但仍属于简单查询。由于age是在SELECT部分被引用,MySQL不会用它来限制列选择操作。因此,对于这个查询来说,创建age列的索引没有什么必要。下面是一个更复杂的例子:
SELECT people.age, ##不使用索引 town.name ##不使用索引 FROM people LEFT JOIN town ON
people.townid=town.townid ##考虑使用索引 WHERE firstname='Mike' ##考虑使用索引 AND
lastname='Sullivan' ##考虑使用索引
与前面的例子一样,由于firstname和lastname出现在WHERE子句中,因此这两个列仍旧有创建索引的必要。除此之外,由于town表的townid列出现在join子句中,因此我们需要考虑创建该列的索引。
那么,我们是否可以简单地认为应该索引WHERE子句和join子句中出现的每一个列呢?差不多如此,但并不完全。我们还必须考虑到对列进行比较的操作符类型。MySQL只有对以下操作符才使用索引:,>=,BETWEEN,IN,以及某些时候的LIKE。可以在LIKE操作中使用索引的情形是指另一个操作数不是以通配符(%或者_)开头的情形。例如,“SELECT peopleid FROM people WHERE firstname LIKE 'Mich%';”这个查询将使用索引,但“SELECT peopleid FROM people WHERE firstname LIKE '%ike';”这个查询不会使用索引。
分析索引效率
现在我们已经知道了一些如何选择索引列的知识,但还无法判断哪一个最有效。MySQL提供了一个内建的SQL命令帮助我们完成这个任务,这就是EXPLAIN命令。EXPLAIN命令的一般语法是:EXPLAIN <SQL命令>。你可以在MySQL文档找到有关该命令的更多说明。下面是一个例子
EXPLAIN SELECT peopleid FROM people WHERE firstname='Mike' AND lastname='Sullivan' AND age='17';
这个命令将返回下面这种分析结果:

下面我们就来看看这个EXPLAIN分析结果的含义。
table:这是表的名字。
type:连接操作的类型。下面是MySQL文档关于ref连接类型的说明:
“对于每一种与另一个表中记录的组合,MySQL将从当前的表读取所有带有匹配索引值的记录。如果连接操作只使用键的最左前缀,或者如果键不是UNIQUE或PRIMARY KEY类型(换句话说,如果连接操作不能根据键值选择出唯一行),则MySQL使用ref连接类型。如果连接操作所用的键只匹配少量的记录,则ref是一种好的连接类型。”
在本例中,由于索引不是UNIQUE类型,ref是我们能够得到的最好连接类型。
如果EXPLAIN显示连接类型是“ALL”,而且你并不想从表里面选择出大多数记录,那么MySQL的操作效率将非常低,因为它要扫描整个表。你可以加入更多的索引来解决这个问题。预知更多信息,请参见MySQL的手册说明。
possible_keys:
可能可以利用的索引的名字。这里的索引名字是创建索引时指定的索引昵称;如果索引没有昵称,则默认显示的是索引中第一个列的名字(在本例中,它是“firstname”)。默认索引名字的含义往往不是很明显。
Key:
它显示了MySQL实际使用的索引的名字。如果它为空(或NULL),则MySQL不使用索引。
key_len:
索引中被使用部分的长度,以字节计。在本例中,key_len是102,其中firstname占50字节,lastname占50字节,age占2字节。如果MySQL只使用索引中的firstname部分,则key_len将是50。
ref:
它显示的是列的名字(或单词“const”),MySQL将根据这些列来选择行。在本例中,MySQL根据三个常量选择行。
rows:
MySQL所认为的它在找到正确的结果之前必须扫描的记录数。显然,这里最理想的数字就是1。
Extra:
这里可能出现许多不同的选项,其中大多数将对查询产生负面影响。在本例中,MySQL只是提醒我们它将用WHERE子句限制搜索结果集。
索引的缺点
到目前为止,我们讨论的都是索引的优点。事实上,索引也是有缺点的。
首先,索引要占用磁盘空间。通常情况下,这个问题不是很突出。但是,如果你创建每一种可能列组合的索引,索引文件体积的增长速度将远远超过数据文件。如果你有一个很大的表,索引文件的大小可能达到操作系统允许的最大文件限制。
第二,对于需要写入数据的操作,比如DELETE、UPDATE以及INSERT操作,索引会降低它们的速度。这是因为MySQL不仅要把改动数据写入数据文件,而且它还要把这些改动写入索引文件。