trie图的构建------易理解版
当然看这篇文章最好在看trie图那篇原文看不懂的情况下再看这篇
这篇只是便于理解可能有不严谨的地方
看trie图看了一个小时终于看明白了,冯涛原创,我在网上就看到有一篇讲解trie图的看的好费劲啊,绕圈子都快拧成死疙瘩了,我根据自己理解的捋一捋:
首先,要建立好一个trie树
Trie树的建立:
前提:结点定义有一个标志位表示结点是否是危险结点,有一个指针数组保存所指向的儿子结点
</pre><pre name="code" class="cpp">struct trie_node
{
int d;//标志位
trie_node *child[MAX];
};
第一,首先初始化一个根节点
第二,读入字符x,若当前结点的child[x-'a']不为空则把当前结点设置为child[x-'a'];若当前结点的child[x-'a']为空,则新初始化一个结点作为child[x-'a']然后把当前结点设置为child[x-'a']。若字符x为单词的最后一个字符设置当前结点的标志位。
例如:有以下五个单词:
a
apple
beg
orange
egg
那么建立的trie树为:
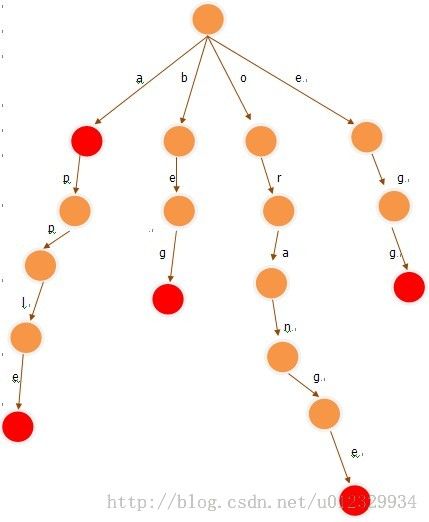
然后,将其改造成trie图
那么在改造trie图的时候:
首先,第一步就是求出所有结点的后缀结点(后缀结点的求法原文中比较绕)
查找每个节点的后缀结点

然后,有了后缀结点就可以对每一个结点进行拓展了也就是建立新的边
连接新边

扩展新边后:
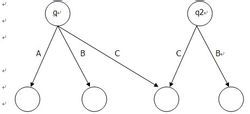
以结点p为根的子树与以结点p的后缀结点为根的子树是一样的.其实这只是讲了建立的过程对于其中深奥的含义还得细细品味